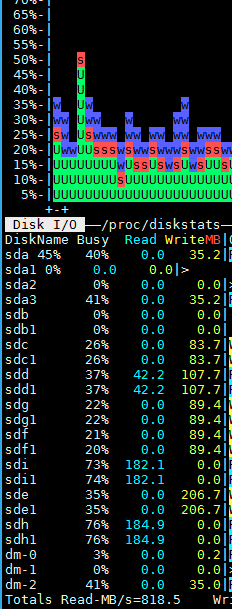
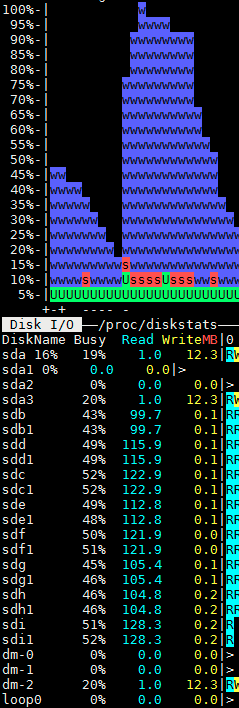
is this right setting for elasticsearch.yml ?
thread_pool.fetch_shard_store.core: 1
warm nodes are still falling out of cluster:
[2020-09-30T16:30:32,098][DEBUG][o.e.c.a.s.ShardStateAction] [serverra2_warm.sit.comp.state] sending [internal:cluster/shard/started] to [BVnFEkNNTcKHn-WldV8mlw] for shard
entry [StartedShardEntry{shardId [[comp_app_compp_rrs-performance-2020.08.08][0]], allocationId [NbGASq0BSamDAskL6z5sDA], primary term [41], message [after existing
store recovery; bootstrap_history_uuid=false]}]
[2020-09-30T16:30:33,499][DEBUG][o.e.c.a.s.ShardStateAction] [serverra2_warm.sit.comp.state] sending [internal:cluster/shard/started] to [BVnFEkNNTcKHn-WldV8mlw] for shard
entry [StartedShardEntry{shardId [[comp_app_compp_srs-services-2020.08.08][0]], allocationId [8OAHKPBURQOMEBk6UldDvA], primary term [43], message [after existing sto
re recovery; bootstrap_history_uuid=false]}]
[2020-09-30T16:31:05,440][DEBUG][o.e.c.c.PublicationTransportHandler] [serverra2_warm.sit.comp.state] received diff cluster state version [459269] with uuid [oMZXGcEbQpmAV
mrJtiPJow], diff size [673]
[2020-09-30T16:31:21,251][DEBUG][o.e.c.a.s.ShardStateAction] [serverra2_warm.sit.comp.state] sending [internal:cluster/shard/started] to [BVnFEkNNTcKHn-WldV8mlw] for shard
entry [StartedShardEntry{shardId [[comp_app_compp_rrs-daolog-2020.08.08][0]], allocationId [YROyRcorQyO2UXuCvG0VWQ], primary term [85], message [after existing store
recovery; bootstrap_history_uuid=false]}]
[2020-09-30T16:33:05,868][DEBUG][o.e.c.c.PublicationTransportHandler] [serverra2_warm.sit.comp.state] received diff cluster state version [459270] with uuid [C6DRtdZmQaqaE
uxJMkjPfw], diff size [9155]
[2020-09-30T16:35:06,498][DEBUG][o.e.c.c.PublicationTransportHandler] [serverra2_warm.sit.comp.state] received diff cluster state version [459271] with uuid [3aF7wogRTM2A8
KyDb1rIyw], diff size [7192]
[2020-09-30T16:37:10,041][DEBUG][o.e.c.c.LeaderChecker ] [serverra2_warm.sit.comp.state] 1 consecutive failures (limit [cluster.fault_detection.leader_check.retry_count
] is 9) with leader [{serverra3.sit.comp.state}{BVnFEkNNTcKHn-WldV8mlw}{0S9K9G-BRG2F_u2__tlZoA}{10.100.24.232}{10.100.24.232:9300}{dilmrt}{rack_id=rack_one, ml.machine_mem
ory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=hot, transform.node=true}]
org.elasticsearch.transport.RemoteTransportException: [serverra3.sit.comp.state][10.100.24.232:9300][internal:coordination/fault_detection/leader_check]
Caused by: org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: rejecting leader check since [{serverra2_warm.sit.comp.state}{KiQQGwdoTgWwHYzMItyhXQ}
{-WbNLIpnR0i2_JR9srCxFQ}{10.100.24.231}{10.100.24.231:9301}{dlrt}{rack_id=rack_one, ml.machine_memory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=war
m, transform.node=true}] has been removed from the cluster
at org.elasticsearch.cluster.coordination.LeaderChecker.handleLeaderCheck(LeaderChecker.java:180) ~[elasticsearch-7.7.0.jar:7.7.0]
at org.elasticsearch.cluster.coordination.LeaderChecker.lambda$new$0(LeaderChecker.java:106) ~[elasticsearch-7.7.0.jar:7.7.0]
at org.elasticsearch.xpack.security.transport.SecurityServerTransportInterceptor$ProfileSecuredRequestHandler$1.doRun(SecurityServerTransportInterceptor.java:2
57) ~[?:?]
...
[2020-09-30T16:37:16,063][DEBUG][o.e.c.c.LeaderChecker ] [serverra2_warm.sit.comp.state] 3 consecutive failures (limit [cluster.fault_detection.leader_check.retry_count
] is 9) with leader [{serverra3.sit.comp.state}{BVnFEkNNTcKHn-WldV8mlw}{0S9K9G-BRG2F_u2__tlZoA}{10.100.24.232}{10.100.24.232:9300}{dilmrt}{rack_id=rack_one, ml.machine_mem
ory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=hot, transform.node=true}]
org.elasticsearch.transport.RemoteTransportException: [serverra3.sit.comp.state][10.100.24.232:9300][internal:coordination/fault_detection/leader_check]
Caused by: org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: rejecting leader check since [{serverra2_warm.sit.comp.state}{KiQQGwdoTgWwHYzMItyhXQ}
{-WbNLIpnR0i2_JR9srCxFQ}{10.100.24.231}{10.100.24.231:9301}{dlrt}{rack_id=rack_one, ml.machine_memory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=war
m, transform.node=true}] has been removed from the cluster
...
[2020-09-30T16:37:34,121][INFO ][o.e.c.c.Coordinator ] [serverra2_warm.sit.comp.state] master node [{serverra3.sit.comp.state}{BVnFEkNNTcKHn-WldV8mlw}{0S9K9G-BRG2F_u2__tl
ZoA}{10.100.24.232}{10.100.24.232:9300}{dilmrt}{rack_id=rack_one, ml.machine_memory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=hot, transform.node=t
rue}] failed, restarting discovery
org.elasticsearch.ElasticsearchException: node [{serverra3.sit.comp.state}{BVnFEkNNTcKHn-WldV8mlw}{0S9K9G-BRG2F_u2__tlZoA}{10.100.24.232}{10.100.24.232:9300}{dilmrt}{rack_
id=rack_one, ml.machine_memory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=hot, transform.node=true}] failed [9] consecutive checks
...
[2020-09-30T16:37:34,114][DEBUG][o.e.c.c.LeaderChecker ] [serverra2_warm.sit.comp.state] leader [{serverra3.sit.comp.state}{BVnFEkNNTcKHn-WldV8mlw}{0S9K9G-BRG2F_u2__tlZoA}{
10.100.24.232}{10.100.24.232:9300}{dilmrt}{rack_id=rack_one, ml.machine_memory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=hot, transform.node=true}]
has failed 9 consecutive checks (limit [cluster.fault_detection.leader_check.retry_count] is 9); last failure was:
org.elasticsearch.transport.RemoteTransportException: [serverra3.sit.comp.state][10.100.24.232:9300][internal:coordination/fault_detection/leader_check]
Caused by: org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: rejecting leader check since [{serverra2_warm.sit.comp.state}{KiQQGwdoTgWwHYzMItyhXQ}
{-WbNLIpnR0i2_JR9srCxFQ}{10.100.24.231}{10.100.24.231:9301}{dlrt}{rack_id=rack_one, ml.machine_memory=269645852672, ml.max_open_jobs=20, xpack.installed=true, data=war
m, transform.node=true}] has been removed from the cluster
 . Thanks, you've been very helpful.
. Thanks, you've been very helpful.