So we have a small development cluster that we are doing some sizing tests
with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB per
node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) - 32GB
per node for heap
We have around 280GB of data and 250M documents in a single index. This
index is a readonly index, we do no indexing. My question is what is using
the heap?
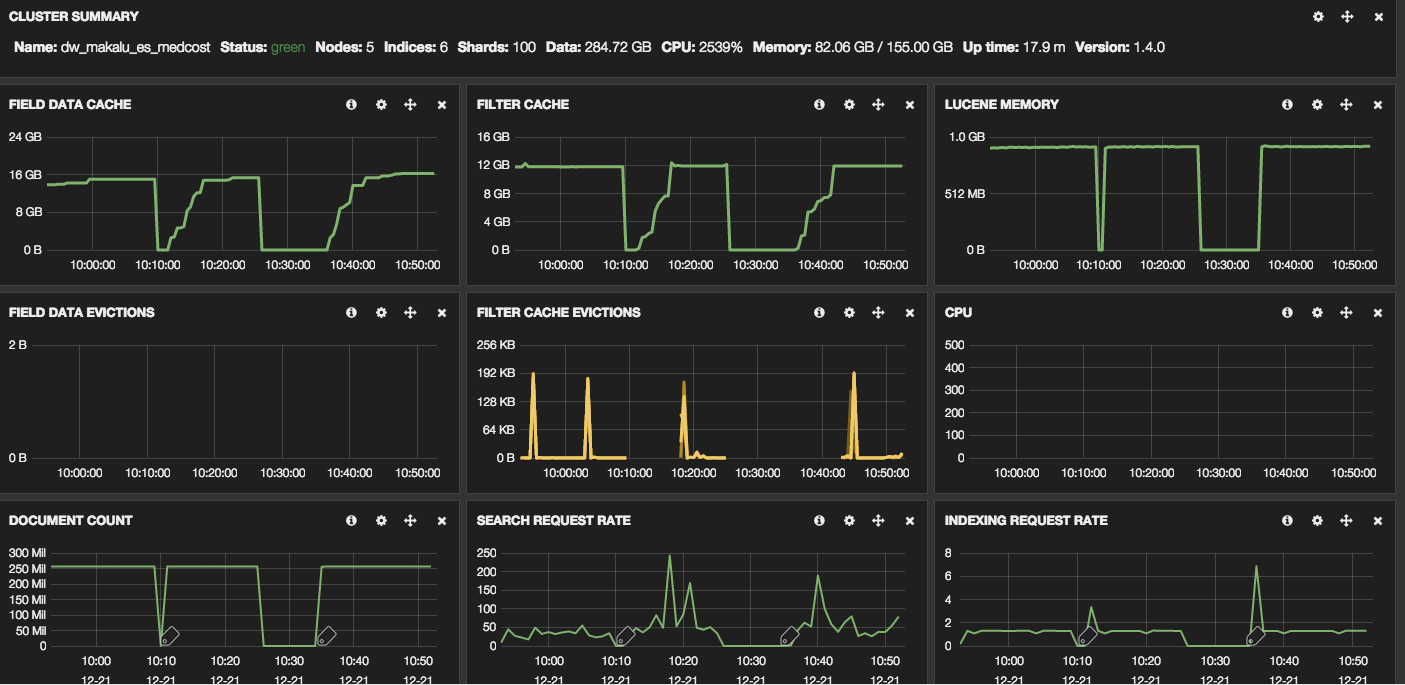
I am showing 82GB of heap used of 155GB total. The Field Data Cache is
using 16GB and the Filter Cache is using 12 GB with another 1GB being used
by Lucene. Query Cache on the data nodes is next to nothing and on the
query node it is a less than a GB. So what could be using the remaining
50GB?
You should reduce your heap to half your system RAM, ie 30GB, so it's not
more than 31GB. Above that your java pointers aren't compressed and you get
less efficient heap use.
What sort of data is it, how many shards in your index, are your queries
heavy (ie lots of aggs), are you using parent+child relationships?
So we have a small development cluster that we are doing some sizing tests
with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB per
node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) - 32GB
per node for heap
We have around 280GB of data and 250M documents in a single index. This
index is a readonly index, we do no indexing. My question is what is using
the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache is
using 16GB and the Filter Cache is using 12 GB with another 1GB being used
by Lucene. Query Cache on the data nodes is next to nothing and on the
query node it is a less than a GB. So what could be using the remaining
50GB?
You should reduce your heap to half your system RAM, ie 30GB, so it's not
more than 31GB. Above that your java pointers aren't compressed and you get
less efficient heap use.
What sort of data is it, how many shards in your index, are your queries
heavy (ie lots of aggs), are you using parent+child relationships?
On 21 December 2014 at 16:10, Jeff Rick jeffrick@gmail.com wrote:
Hi,
So we have a small development cluster that we are doing some sizing tests
with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB per
node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) - 32GB
per node for heap
We have around 280GB of data and 250M documents in a single index. This
index is a readonly index, we do no indexing. My question is what is using
the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache is
using 16GB and the Filter Cache is using 12 GB with another 1GB being used
by Lucene. Query Cache on the data nodes is next to nothing and on the
query node it is a less than a GB. So what could be using the remaining
50GB?
That's way too many shards, you only really need 1 shard per node, unless
you're expecting to dramatically increase your node count in the near
future.
More info on what data it is would be useful; are the docs large, numerous,
are you using relationships as I mentioned?
What about your querying? Lots of aggregations/facets?
And as I mentioned, you lose performance by having a 32GB heap, I'd
strongly recommonend you reduce it.
You should reduce your heap to half your system RAM, ie 30GB, so it's
not more than 31GB. Above that your java pointers aren't compressed and you
get less efficient heap use.
What sort of data is it, how many shards in your index, are your queries
heavy (ie lots of aggs), are you using parent+child relationships?
So we have a small development cluster that we are doing some sizing
tests with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB per
node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) -
32GB per node for heap
We have around 280GB of data and 250M documents in a single index. This
index is a readonly index, we do no indexing. My question is what is using
the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache is
using 16GB and the Filter Cache is using 12 GB with another 1GB being used
by Lucene. Query Cache on the data nodes is next to nothing and on the
query node it is a less than a GB. So what could be using the remaining
50GB?
That's way too many shards, you only really need 1 shard per node, unless
you're expecting to dramatically increase your node count in the near
future.
More info on what data it is would be useful; are the docs large, numerous,
are you using relationships as I mentioned?
What about your querying? Lots of aggregations/facets?
And as I mentioned, you lose performance by having a 32GB heap, I'd
strongly recommonend you reduce it.
On 21 December 2014 at 20:04, Jeff Rick jeffrick@gmail.com wrote:
So each node has 60gb of memory and heap is set to 32gb.
This is Medical data, we do lots of aggregations but no parent child
relationships. We currently have 36 shards for the index.
You should reduce your heap to half your system RAM, ie 30GB, so it's
not more than 31GB. Above that your java pointers aren't compressed and you
get less efficient heap use.
What sort of data is it, how many shards in your index, are your queries
heavy (ie lots of aggs), are you using parent+child relationships?
So we have a small development cluster that we are doing some sizing
tests with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB per
node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) -
32GB per node for heap
We have around 280GB of data and 250M documents in a single index. This
index is a readonly index, we do no indexing. My question is what is using
the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache is
using 16GB and the Filter Cache is using 12 GB with another 1GB being used
by Lucene. Query Cache on the data nodes is next to nothing and on the
query node it is a less than a GB. So what could be using the remaining
50GB?
My original response has a suggestion on heap setting.
Are you using Oracle or OpenJDK? The former has better performance so it
might be worth changing if you're not using it. What version of ES are you
using?
Given this is dev, I'd suggest you also install the Marvel plugin to give
you some insights into what is happening.
That's way too many shards, you only really need 1 shard per node,
unless you're expecting to dramatically increase your node count in the
near future.
More info on what data it is would be useful; are the docs large,
numerous, are you using relationships as I mentioned?
What about your querying? Lots of aggregations/facets?
And as I mentioned, you lose performance by having a 32GB heap, I'd
strongly recommonend you reduce it.
You should reduce your heap to half your system RAM, ie 30GB, so it's
not more than 31GB. Above that your java pointers aren't compressed and you
get less efficient heap use.
What sort of data is it, how many shards in your index, are your
queries heavy (ie lots of aggs), are you using parent+child relationships?
So we have a small development cluster that we are doing some sizing
tests with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB
per node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) -
32GB per node for heap
We have around 280GB of data and 250M documents in a single index.
This index is a readonly index, we do no indexing. My question is what is
using the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache
is using 16GB and the Filter Cache is using 12 GB with another 1GB being
used by Lucene. Query Cache on the data nodes is next to nothing and on
the query node it is a less than a GB. So what could be using the
remaining 50GB?
My original response has a suggestion on heap setting.
Are you using Oracle or OpenJDK? The former has better performance so it
might be worth changing if you're not using it. What version of ES are you
using?
Given this is dev, I'd suggest you also install the Marvel plugin to give
you some insights into what is happening.
That's way too many shards, you only really need 1 shard per node,
unless you're expecting to dramatically increase your node count in the
near future.
More info on what data it is would be useful; are the docs large,
numerous, are you using relationships as I mentioned?
What about your querying? Lots of aggregations/facets?
And as I mentioned, you lose performance by having a 32GB heap, I'd
strongly recommonend you reduce it.
You should reduce your heap to half your system RAM, ie 30GB, so
it's not more than 31GB. Above that your java pointers aren't compressed
and you get less efficient heap use.
What sort of data is it, how many shards in your index, are your
queries heavy (ie lots of aggs), are you using parent+child relationships?
So we have a small development cluster that we are doing some sizing
tests with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB
per node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge) -
32GB per node for heap
We have around 280GB of data and 250M documents in a single index.
This index is a readonly index, we do no indexing. My question is what is
using the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache
is using 16GB and the Filter Cache is using 12 GB with another 1GB being
used by Lucene. Query Cache on the data nodes is next to nothing and on
the query node it is a less than a GB. So what could be using the
remaining 50GB?
My original response has a suggestion on heap setting.
Are you using Oracle or OpenJDK? The former has better performance so it
might be worth changing if you're not using it. What version of ES are you
using?
Given this is dev, I'd suggest you also install the Marvel plugin to give
you some insights into what is happening.
That's way too many shards, you only really need 1 shard per node,
unless you're expecting to dramatically increase your node count in the
near future.
More info on what data it is would be useful; are the docs large,
numerous, are you using relationships as I mentioned?
What about your querying? Lots of aggregations/facets?
And as I mentioned, you lose performance by having a 32GB heap, I'd
strongly recommonend you reduce it.
You should reduce your heap to half your system RAM, ie 30GB, so
it's not more than 31GB. Above that your java pointers aren't compressed
and you get less efficient heap use.
What sort of data is it, how many shards in your index, are your
queries heavy (ie lots of aggs), are you using parent+child relationships?
So we have a small development cluster that we are doing some sizing
tests with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) - 32GB
per node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge)
32GB per node for heap
We have around 280GB of data and 250M documents in a single index.
This index is a readonly index, we do no indexing. My question is what is
using the heap?
I am showing 82GB of heap used of 155GB total. The Field Data Cache
is using 16GB and the Filter Cache is using 12 GB with another 1GB being
used by Lucene. Query Cache on the data nodes is next to nothing and on
the query node it is a less than a GB. So what could be using the
remaining 50GB?
So this is all good but I guess I am still trying to figure out what is
taking the heap space other than Field Data Cache and Filter Cache. Does
anyone know the answer to that?
Thanks
On Sunday, December 21, 2014 5:39:32 PM UTC-5, Mark Walkom wrote:
Woops, got my threads crossed there
On 21 December 2014 at 22:00, Jeff Rick <jeff...@gmail.com <javascript:>>
wrote:
Hi Mark,
I really appreciate the advice and sorry I missed the earlier suggestion
on heap.
We are running 1.4.0 and Oracle:
java version "1.7.0_55"
Java(TM) SE Runtime Environment (build 1.7.0_55-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.55-b03, mixed mode)
We have installed Marvel on the cluster and on the original message I
posted a screen shot from the dashboard.
Thanks
On Sun, Dec 21, 2014 at 4:45 PM, Mark Walkom <markw...@gmail.com
<javascript:>> wrote:
My original response has a suggestion on heap setting.
Are you using Oracle or OpenJDK? The former has better performance so it
might be worth changing if you're not using it. What version of ES are you
using?
Given this is dev, I'd suggest you also install the Marvel plugin to
give you some insights into what is happening.
On 21 December 2014 at 21:26, Jeff Rick <jeff...@gmail.com <javascript:>
wrote:
Larger documents maybe 1-2k a piece. We do aggregations/facets with
some search.
What heap should we have on a node with 60gb of memory?. Right now we
get an occasional out of memory and long GCs.
—
Thanks
On Sun, Dec 21, 2014 at 3:47 PM, Mark Walkom <markw...@gmail.com
<javascript:>> wrote:
That's way too many shards, you only really need 1 shard per node,
unless you're expecting to dramatically increase your node count in the
near future.
More info on what data it is would be useful; are the docs large,
numerous, are you using relationships as I mentioned?
What about your querying? Lots of aggregations/facets?
And as I mentioned, you lose performance by having a 32GB heap, I'd
strongly recommonend you reduce it.
On 21 December 2014 at 20:04, Jeff Rick <jeff...@gmail.com
<javascript:>> wrote:
So each node has 60gb of memory and heap is set to 32gb.
This is Medical data, we do lots of aggregations but no parent child
relationships. We currently have 36 shards for the index.
—
Thanks
On Sun, Dec 21, 2014 at 2:53 PM, Mark Walkom <markw...@gmail.com
<javascript:>> wrote:
You should reduce your heap to half your system RAM, ie 30GB, so
it's not more than 31GB. Above that your java pointers aren't compressed
and you get less efficient heap use.
What sort of data is it, how many shards in your index, are your
queries heavy (ie lots of aggs), are you using parent+child relationships?
On 21 December 2014 at 16:10, Jeff Rick <jeff...@gmail.com
<javascript:>> wrote:
Hi,
So we have a small development cluster that we are doing some
sizing tests with. The make-up of the cluster as is follows:
4 Data Nodes - 60GB of memory and 108 cores (aka c3.8xlarge) -
32GB per node for heap
1 Query / Master Node - 61GB memory and 26 cores (aka r3.2xlarge)
32GB per node for heap
We have around 280GB of data and 250M documents in a single index.
This index is a readonly index, we do no indexing. My question is what is
using the heap?
I am showing 82GB of heap used of 155GB total. The Field Data
Cache is using 16GB and the Filter Cache is using 12 GB with another 1GB
being used by Lucene. Query Cache on the data nodes is next to nothing and
on the query node it is a less than a GB. So what could be using the
remaining 50GB?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.
{kind=link}