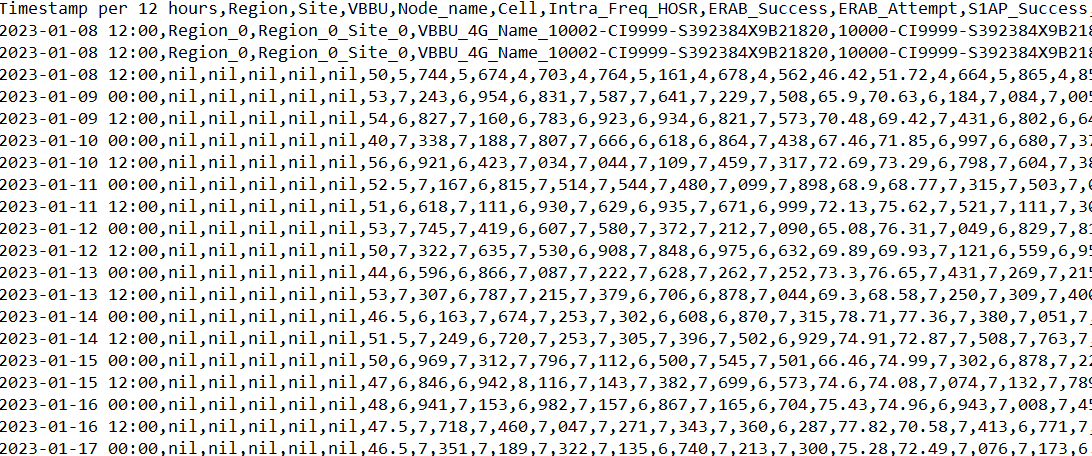
When Downloading CSV from Tabular format, each variable is getting separated with Comma (,). Due to this variable which are numerical values (for e.g., 2,946) are also getting in different columns.
As shown in below image, Intra_Freq value was 4,678. But due to getting separated with comma, the values are getting split as 4 and 678.
can you share some more information here to reproduce the issue?
What version of the ELK stack are you using?
Is this a CSV coming from a visualization (Lens, Agg-based, etc...) or from a search CSV report (Discover, etc...)?
Hello @Marco_Liberati
I am using v8.6.1 for ES, and Kibana.
the CSV is getting exported from Lens (tabular format)
and when CSV is opened, it applies TEXT TO COLUMN based on Comma (,) as all variables are separated with Comma only. In this process the values which more than hundred, i.e., thousands and have comma in between are getting shifted to next column
Please find screenshot of the text editor. All values are separated with comma. Even some values which are in thousands are also having Comma in between.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.