Hello,
There are 6 servers, and each have 64GB ram and 12 spinning disks (2 TB per disk. so 24TB in total).
When I give 32GB RAM to ES, It seems that maximum storable index size for a node is around 4TB.
So, If I set RAID 0, 20TB disks will be unused.
And I can not increase replica due to the ES heap limit.
How about,
Make 6 Raid1 array? I mean (raid1 = 2disk) * 6 ==> 6 path, 12TB available disk space.
Then one raid1 give to OS, /data0
Five raid1 will be configured for path.data=/data1,/data2,/data3,/data4,/data5
OK,
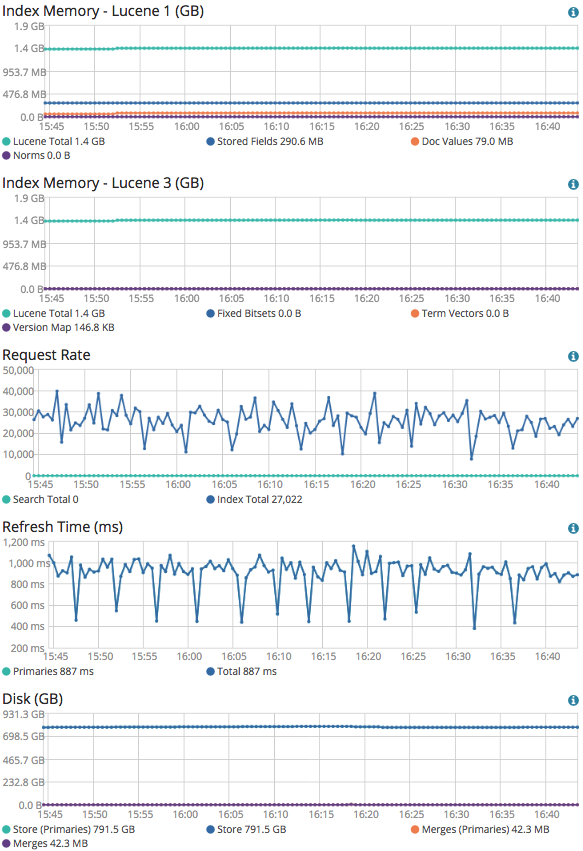
I store user click stream logs to ES, a index per a day, with 5 shard, no replica.
In a day, 2 billion logs indexed and it's index size is about 750GB.
I thinks, this click stream logs are not mission critical, so replica required not importantly.
Actually there are 6 hot-nodes, 2 warm-nodes, 3 master dedicated nodes
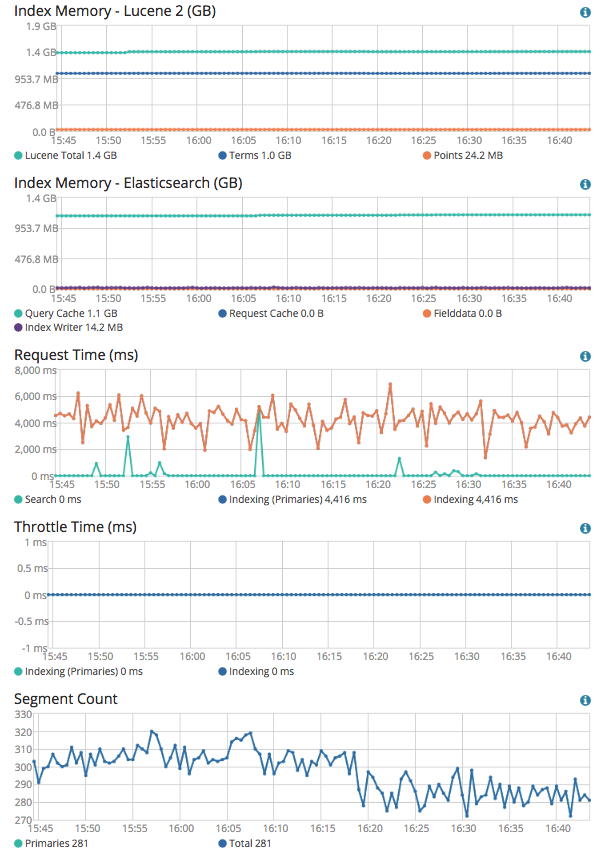
Mappings look fine and properly optimised, so no problem there. You do however have quite large shards and the terms heap usage is high. I would recommend trying to reduce the average shard size to closer to 50GB to see if this makes a difference, e.g. by increasing the number of primary shards to between 15 and 18.
Now reindexing ongoing with 15 shards.
It might takes 6 hours...
It seems that even though 15 shards reduces heap usage by 2-30% compared to 5 shards, I still cannot have replica. If 50% reduced I can have 1 replica.
Anyway I will check out the 15 shards index's stats.
Raid configuration, what I asked first, seems a little independent from the this 15 shard test. Because disk space quietly large. How do you think about set raid up regardless of heap optimizing if multiple raid1 make sense.
If a single daily index is nearly 750GB, I would consider writing hourly indices rather than daily. That will reduce them to a far more manageable ~30GB/index.
If a single daily index is nearly 750GB, I would consider writing hourly indices rather than daily. That will reduce them to a far more manageable ~30GB/index.
It is a shame it did help, but I have to admit it was a long shot. As the mappings look good I am not sure I have any other suggestions apart from tweaking the circuit breaker thresholds a bit, but this is unlikely to give any massive improvement and could cause instability if pushed too far.
There is one thing I forgot to ask earlier: Do you allow Elasticsearch to automatically assign document IDs or do you set them yourself? If you set them yourself, what do the IDs look like and how are they generated?
@Christian_Dahlqvist
Could you tell me the technical background of 'more shards to reduce terms heap'? for next time when I meet similar situation and need heap optimizing. : )
Do you allow Elasticsearch to automatically assign document IDs or do you set them yourself?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.