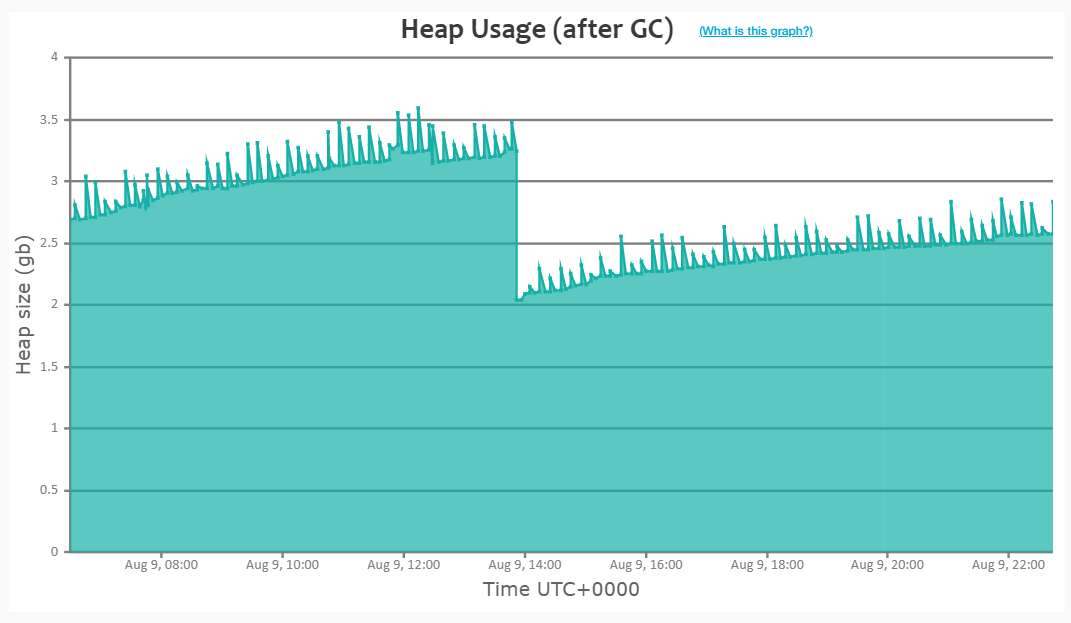
Please find my output below for the above API
{
"_nodes" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"cluster_name" : "mainelk",
"cluster_uuid" : "6yfpVUZYRVWFdeHWYU6tqg",
"timestamp" : 1632487383878,
"status" : "green",
"indices" : {
"count" : 235,
"shards" : {
"total" : 470,
"primaries" : 235,
"replication" : 1.0,
"index" : {
"shards" : {
"min" : 2,
"max" : 2,
"avg" : 2.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 1.0,
"max" : 1.0,
"avg" : 1.0
}
}
},
"docs" : {
"count" : 187619472,
"deleted" : 10941
},
"store" : {
"size" : "162.9gb",
"size_in_bytes" : 174951161873
},
"fielddata" : {
"memory_size" : "177.3kb",
"memory_size_in_bytes" : 181584,
"evictions" : 0
},
"query_cache" : {
"memory_size" : "1.8mb",
"memory_size_in_bytes" : 1979421,
"total_count" : 276530139,
"hit_count" : 252442544,
"miss_count" : 24087595,
"cache_size" : 284,
"cache_count" : 579947,
"evictions" : 579663
},
"completion" : {
"size" : "0b",
"size_in_bytes" : 0
},
"segments" : {
"count" : 4830,
"memory" : "166.8mb",
"memory_in_bytes" : 174921722,
"terms_memory" : "139.9mb",
"terms_memory_in_bytes" : 146741392,
"stored_fields_memory" : "4.1mb",
"stored_fields_memory_in_bytes" : 4370304,
"term_vectors_memory" : "0b",
"term_vectors_memory_in_bytes" : 0,
"norms_memory" : "18.2mb",
"norms_memory_in_bytes" : 19123584,
"points_memory" : "0b",
"points_memory_in_bytes" : 0,
"doc_values_memory" : "4.4mb",
"doc_values_memory_in_bytes" : 4686442,
"index_writer_memory" : "1.8gb",
"index_writer_memory_in_bytes" : 2006032040,
"version_map_memory" : "0b",
"version_map_memory_in_bytes" : 0,
"fixed_bit_set" : "107.8kb",
"fixed_bit_set_memory_in_bytes" : 110464,
"max_unsafe_auto_id_timestamp" : 1632441621559,
"file_sizes" : { }
},
"mappings" : {
"field_types" : [
{
"name" : "alias",
"count" : 374,
"index_count" : 11
},
{
"name" : "text",
"count" : 14031,
"index_count" : 233
}
]
},
"analysis" : {
"char_filter_types" : [ ],
"tokenizer_types" : [ ],
"filter_types" : [ ],
"analyzer_types" : [ ],
"built_in_char_filters" : [ ],
"built_in_tokenizers" : [ ],
"built_in_filters" : [ ],
"built_in_analyzers" : [ ]
}
},
"nodes" : {
"count" : {
"total" : 3,
"coordinating_only" : 0,
"data" : 3,
"ingest" : 0,
"master" : 3,
"ml" : 0,
"remote_cluster_client" : 0,
"transform" : 3,
"voting_only" : 0
},
"versions" : [
"7.7.0"
],
"os" : {
"available_processors" : 36,
"allocated_processors" : 36,
"names" : [
{
"name" : "Linux",
"count" : 3
}
],
"pretty_names" : [
{
"pretty_name" : "Red Hat Enterprise Linux",
"count" : 3
}
],
"mem" : {
"total" : "188.2gb",
"total_in_bytes" : 202160398336,
"free" : "3.7gb",
"free_in_bytes" : 4024860672,
"used" : "184.5gb",
"used_in_bytes" : 198135537664,
"free_percent" : 2,
"used_percent" : 98
}
},
"process" : {
"cpu" : {
"percent" : 1
},
"open_file_descriptors" : {
"min" : 1779,
"max" : 1840,
"avg" : 1817
}
},
"jvm" : {
"max_uptime" : "120.9d",
"max_uptime_in_millis" : 10447587500,
"versions" : [
{
"version" : "14",
"vm_name" : "OpenJDK 64-Bit Server VM",
"vm_version" : "14+36",
"vm_vendor" : "AdoptOpenJDK",
"bundled_jdk" : true,
"using_bundled_jdk" : true,
"count" : 3
}
],
"mem" : {
"heap_used" : "21.4gb",
"heap_used_in_bytes" : 23056379088,
"heap_max" : "60gb",
"heap_max_in_bytes" : 64424509440
},
"threads" : 595
},
"fs" : {
"total" : "1.1tb",
"total_in_bytes" : 1287860256768,
"free" : "1tb",
"free_in_bytes" : 1109414490112,
"available" : "1tb",
"available_in_bytes" : 1109414490112
},
"plugins" : ,
"network_types" : {
"transport_types" : {
"security4" : 3
},
"http_types" : {
"security4" : 3
}
},
"discovery_types" : {
"zen" : 3
},
"packaging_types" : [
{
"flavor" : "default",
"type" : "rpm",
"count" : 3
}
],
"ingest" : {
"number_of_pipelines" : 2,
"processor_stats" : {
"gsub" : {
"count" : 0,
"failed" : 0,
"current" : 0,
"time" : "0s",
"time_in_millis" : 0
},
"script" : {
"count" : 0,
"failed" : 0,
"current" : 0,
"time" : "0s",
"time_in_millis" : 0
}
}
}
}
}