The server is 5 physical machines and the operation system is ubuntu18.04
Es old cluster version: 7.3.1
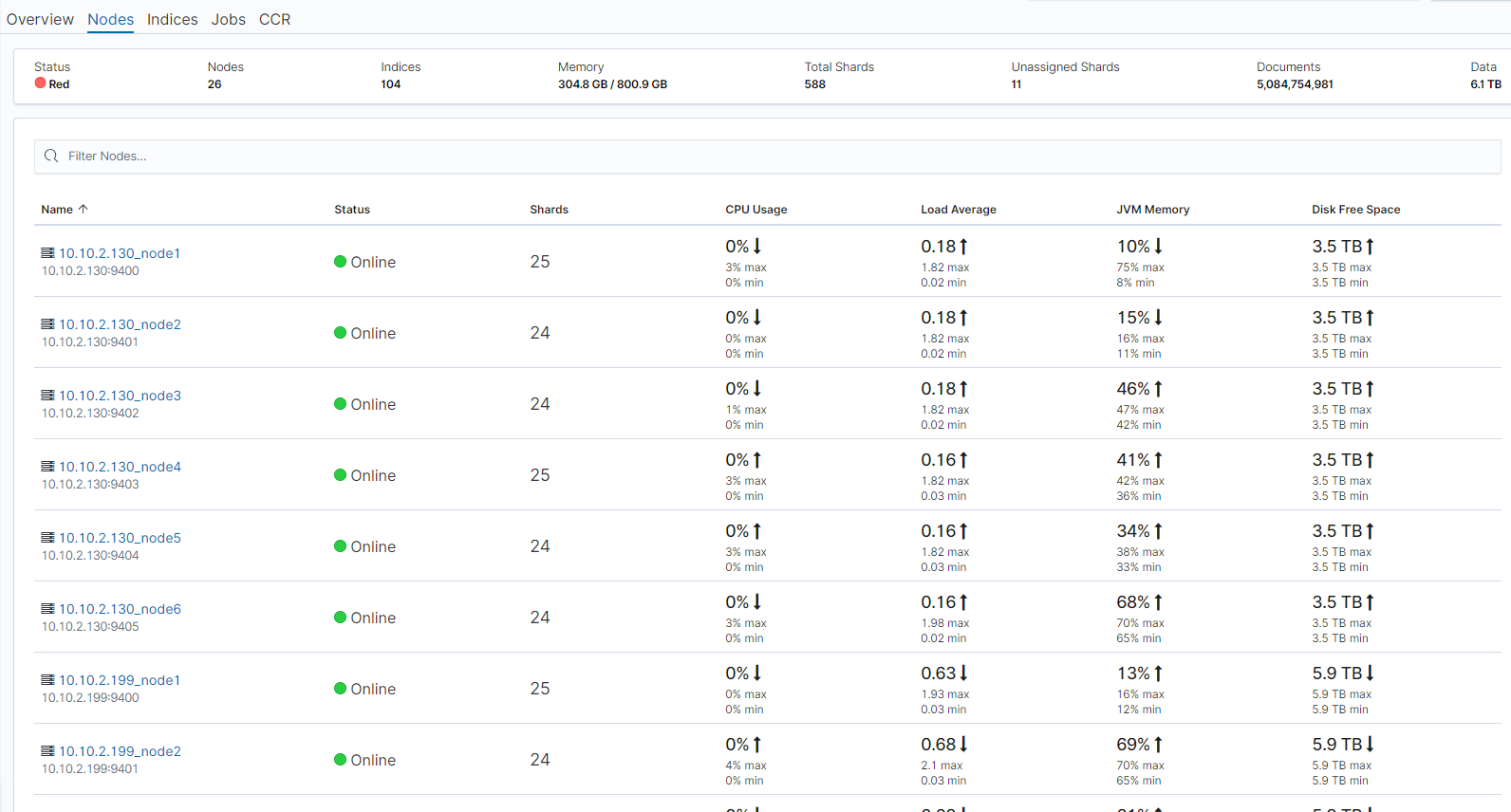
The related nodes, indexes, memory, and sharding cases are as follows
The main Settings information of the old index is as follows:
"settings" : {
"index" : {
"search" : {
"slowlog" : {
"level" : "info",
"threshold" : {
"fetch" : {
"warn" : "1s",
"trace" : "200ms",
"debug" : "500ms",
"info" : "800ms"
},
"query" : {
"warn" : "10s",
"trace" : "500ms",
"debug" : "2s",
"info" : "5s"
}
}
}
},
"refresh_interval" : "60s",
"indexing" : {
"slowlog" : {
"threshold" : {
"index" : {
"warn" : "10s",
"trace" : "500ms",
"debug" : "2s",
"info" : "5s"
}
}
}
},
"number_of_shards" : "20",
"blocks" : {
"read_only_allow_delete" : "false"
},
"provided_name" : "geo_info_polygon_v1",
"merge" : {
"scheduler" : {
"max_thread_count" : "1"
}
},
"number_of_replicas" : "0"
}
}
Es new cluster version: 7.5.1
One entity machine, there are two nodes in total, the disk and memory are normal, and the mapping and setting of the new index and the old index are the same
To synchronize more than 170,000 data under an old index to the new cluster, remote Reindex is used, and the whiteList of the new cluster has been configured in the old cluster. The corresponding REindex statement is as follows:
POST _reindex?slices=1&refresh
{
"conflicts": "proceed",
"source": {
"index": "geo_info_polygon_v1",
"size": 10000,
"remote": {
"host": "https://xx.xx.2.43:9210",
"username": "elastic",
"password": "******"
},
"query": {
"match_all": {}
}
},
"dest": {
"index": "geo_info_polygon_latest"
}
}
I tried to change the value of size to be: 4000, 8000, 10000, the result is the value of size set to what, just migrate the data of the corresponding value, why is that?