I noticed that the document says it need 1000 iterations or more in order to calculate 99.9th percentile. here
I wonder that why it has to base on number of iterations but not the actual amount of requests.
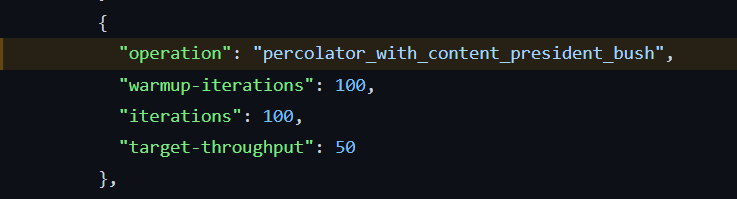
In many tracks, including Rally default tracks, define iteration and target-throughput. For example, one of the percolator track's operation,
According to the document, I understand that the operation will make 50 requests per iteration for 100 times. Result in total of 5000 requests. Which is more than enough for calculating 99.9th percentile since the sample size is more than 1000.
(Honestly this specific number of percentile is not really important to me. But this is the shortest question that will help answer many other questions in my mind)
Thank you.
Hi! Thank you for your interest in Rally. We appreciate that you take the time to read our documentation and ask questions about it, as it's the best way to get reliable benchmarks.
According to the document, I understand that the operation will make 50 requests per iteration for 100 times. Result in total of 5000 requests. Which is more than enough for calculating 99.9th percentile since the sample size is more than 1000.
Setting target-throughput to 50 means 50 iterations per second, not per iteration. So with that example you shared you will only get 100 requests. This is currently considered enough for 99% percentile: https://github.com/elastic/rally/blob/846b8e404b4b4c324cc95e6621f4992d0023da81/esrally/metrics.py#L1714-L1729.
Is there anything we could clarify in the docs?
Thank you for your answer! Now I can understand more clearly.
From your info, it means that Rally will make 50 requests per second and will take roughly 2 seconds to finish the task, sending 100 requests in total.
So the iteration is actually the numbers of request to be sent to Elasticsearch. Is it correct?
If so, it would be great if this can be more clarified in the docs. When I read through these words, there is no apparent relation between them.
To be specific, the latency section in summary report only mention about request, not iteration. Although the FAQ can give me some clue about iteration being the request itself, I started to confuse again when I read at the throughput-throttled mode section and target-throughput definition since they did not really explain me enough how to interpret the meaning of iteration. Leading to this misunderstanding.
(I actually went skimming through the code (include the part that you mentioned) but gave up after few hours  )
)
It's more complicated than that.  While apparently true in your case, it depends on the operation you're using (it could make multiple requests per iteration) and the number of clients you have (as iterations are defined per-client).
While apparently true in your case, it depends on the operation you're using (it could make multiple requests per iteration) and the number of clients you have (as iterations are defined per-client).
I see. So there are reasons behind using these terms.
Thank you very much for your answers