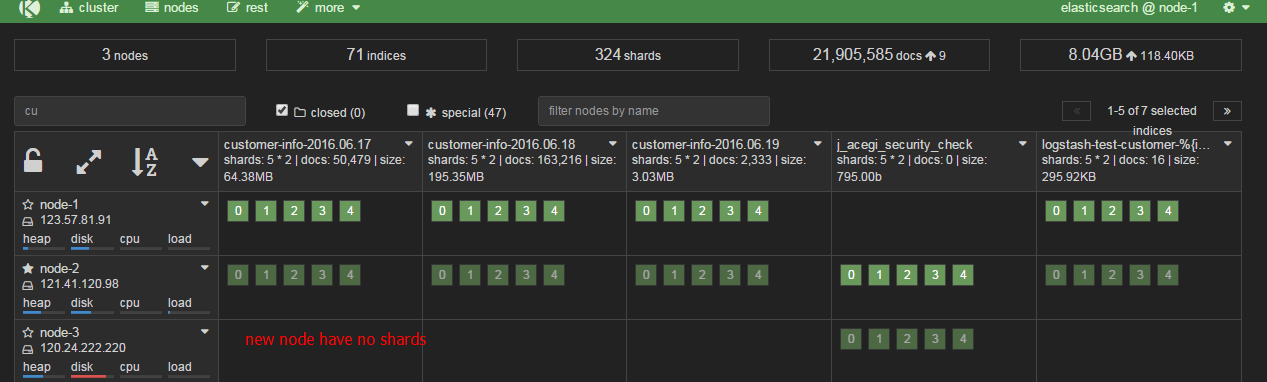
Hi,I have a question, when I add two nodes to my es cluster, the shards then relocate at once.
But the issue is the shards including replica of most index(lighter ones in the graph) are not distributed averagely in the three nodes. I don't know why?
ES tries to divide all the cluster's shards evenly among the nodes. This means that a given index might be unevenly distributed but as a whole the cluster should be balanced. Still, it looks like your node-3 might be underutilized but judging by your screenshot it might be because its available disk space is above the low watermark level, i.e. the node won't accept shard allocations until the free space goes below the watermark.
What should be of concern to you is that your shards are very small. Each shard in a cluster has a fixed RAM overhead, so you're wasting a lot of memory by having an average shard size of just 25 MB. You should strongly consider reducing the number of shards per index to one. Once your daily index reaches a few gigabytes I'd look into increasing the number of shards.
The optimal shard size depends on other factors, though. If the vast majority of your searches are for data in the last 24 hours it might give better performance to have more than one shard, but if searches often span a couple of days chances are that the workload will be distributed across the cluster's nodes anyway.
Planned cluster growth also plays in. If it's unlikely you'll ever have more than three nodes it's almost certainly wasteful to have more than three shards per index.
Thanks a lot magnusbaeck. I am reducing the nodes count back to 1. but the issue now is the shards of the important index "logstash-live" were balanced to three nodes, the new single node just have no shards, I want to ask why and how to move back? copy the /data/ folder to the new one?It seems the structure of data folder of the three nodes are different, one have 1 2 3 4 , one have 0 1 2. so what I can do now?
And the log have below output when I query "logstash-live":
Once shards have been allocated to a node with higher version, it may no longer be possible to later relocate them to a lower version, as the Lucene version may differ. It is therefore possible it could affect your scenario. You should always aim to have all nodes in a cluster on the same version.
so upgrade node-1 will solve the issue? but why other indices had all their shards assigned.
If upgrading can work? so how to do that with node-1?
unzip 2.3.3 tar and copy the /data folder from 2.3.1 to 2.3.3 ?
Will the operation be secure enough to singlely copy ?
I am not sure it will solve the issue, but I would upgrade anyway to eliminate it as a possible cause. The best way to upgrade depend on how you initially installed Elasticsearch, so follow the upgrade guide.
I upgrade the node-1 to 2.3.3, still, 2 shards are not allocated, I don't know why.
It is said it might be caused by translog file under /data folder which has conflict . Do you know the /data folder structure among the nodes that may help on solving this?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.