- In fact, the ES version of target machine is 8.18.2, not 8.14 - I got confused.
I think you may find it more interesting to compare to our latest 9.x version, I believe right now that's 9.0.4. As Xeraa mentioned there's potentially a lot of improvements particularly if you are trying to benchmark against a current version of Milvus, which is the same folks that make VectorDBBench.
Otherwise I would want to know the reason you are on 8.18.x or if there's some reason you are focused on this result on 8.18.x as in can you help us understand what you are trying to achieve.
The mappings config I used is the default params of VectorDBBench
My benchmark dataset is 1 million & 1024 Dims, any recommendation for the params?
It looks like VectorDBBench being part of a Milvus is potentially somewhat biased or misconfigured. I'm not sure, maybe just not maintained?
You should start with the default configuration and see what that looks like first.
m: 16
efConstruction: 100
What I see in the VectorDBBench is also not the defaults but different than what you stated above: VectorDBBench/tests/test_elasticsearch_cloud.py at 9ab7e3c594a456c3b78930835cc277bb9dc55e09 · zilliztech/VectorDBBench · GitHub
So you should be careful about benchmarking with any tool made by a competitor. Maybe somewhat ironically they have an article about having independent benchmarking tools but then don't use the defaults (recommended starting points) for other vector databases.
As an Engineer here's my opinion. I would personally hesitate to compare using VectorDBBench and instead setup an environment that mimics how you expect to scale and handle your use-case. If you want to do true evaluations, you shouldn't trust benchmarks or benchmarking tools from us or them. You have to do your own independent evaluations. Benchmarks are just hard and it's really hard to compare apples to apples, and no one wants to maintain truly independent tools (it's a lot of time and money). Often times I've told folks in the past you need to test on data that's production data and tune any systems you are baking off for your use-case (to be clear tune for your architecture/system not your dataset). And that may even involve, for ES, engaging our consulting team or for Milvus engaging them. I'd be curious how close Bioasq is to your use-case. But I have more thoughts down below on this.
Here's where you can find docs on those defaults for ES in case you need them though (and they have been this way for awhile now):
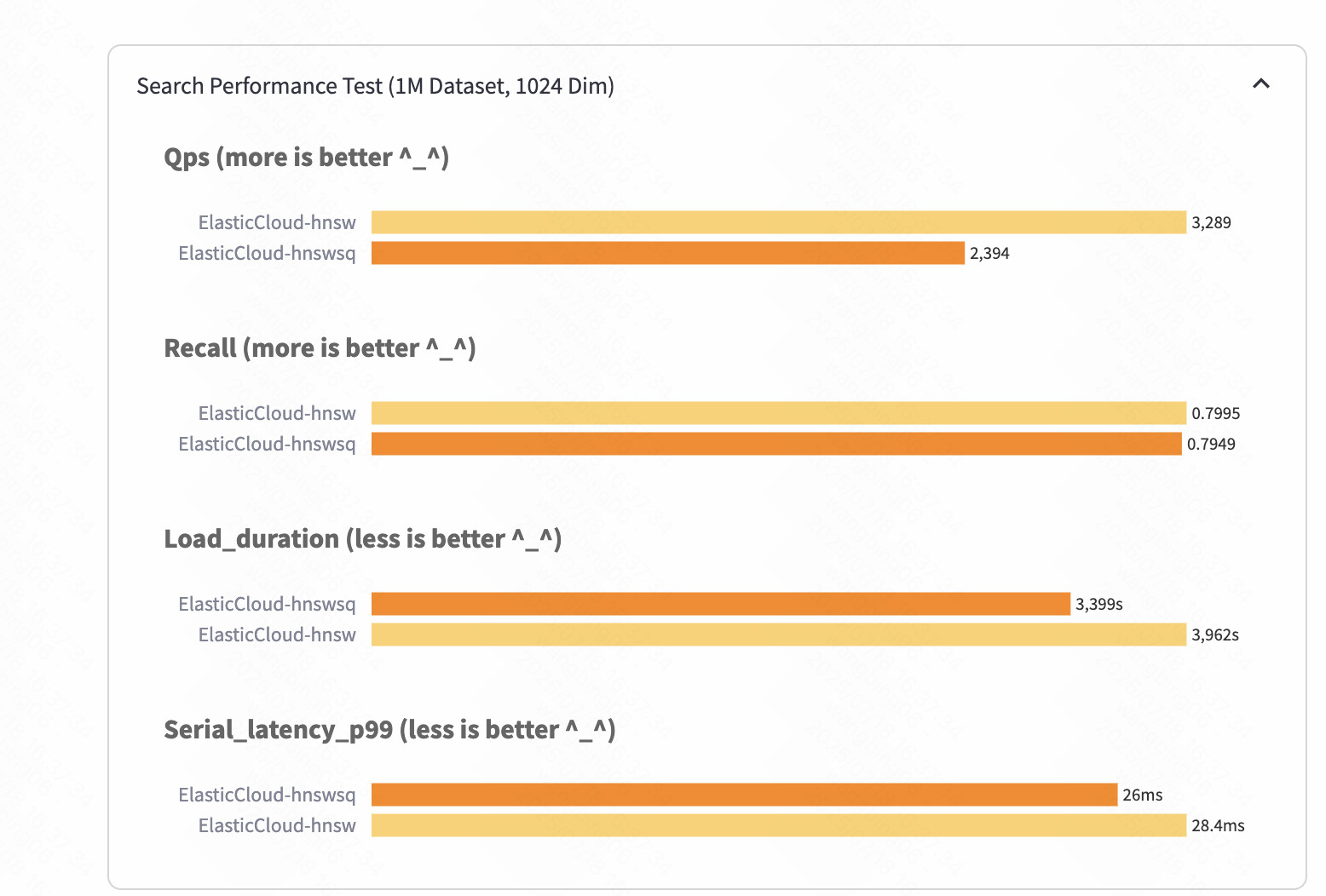
Still I'm wondering why SQ would make query slower, my colleague repeat that too
The result is surprising. However, there's a lot of reasons you can see slowdowns. It's hard to tell from this information. My gut reaction is that the two clusters were not in the same state when doing the evaluation. Be curious to see it run multiple times (not sure how many times VectorDBBench runs the eval or how that setup works as in are there warm up periods, etc). And curious whether the segments had been force merged prior to doing the evaluation or not. I assume the hardware being used is consistent but good to validate all the way up and down the stack that things are in the same state when using VectorDBBench to evaluate.
To say it outloud I think the two things you are evaluating are:
- hnsw (full float)
- int8_hnsw (quantized)
hnsw by default will do less oversample and candidate exploration in the graph. I would not have expected this big a change from this alone but worth eliminating this discrepancy.
Default oversample is 3x of k and num candidates to explore is max(15, k). So it's not clear what your k value is. VectorDBBench seems to default to k:100 so it may be for the sake of starting your comparisons good to explicitly set oversample and num_candidates. I would not have expected this to cause that level of difference though. So something else is likely different between the two runs.
Here's some more information here on that configuration: kNN search | Elastic Docs
Lastly I would recommend you include our new default here as well which is:
- bbq_hnsw (for vector sizes > 384 dims)
It will likely perform better.
Suffice it there's a lot of knobs you can turn. And full float hnsw is meant for small dataset, high accuracy. Any quantization method is primarily interested in reducing size so more of the vectors can be loaded on heap (in this case) and speed up query at large scale. But I would say start with getting on the latest version of ES with the default configuration and be explicit about all the params. Be explicit about whether segments are merged or not. Indicate which hardware is being used. And run multiple evaluations and provide outcomes from those runs so we can all review.
Feel free to ask additional questions and happy to help ya'll iterate.