This post also exists in English.

Construction d'un système de détection de phishing par email avec n8n et Elastic Agent Builder
Les attaques de phishing continuent de dominer le paysage des menaces en cybersécurité, les attaquants utilisant de plus en plus des techniques d'ingénierie sociale sophistiquées pour contourner les filtres traditionnels. En tant que praticien de la sécurité travaillant avec les technologies Elastic, j'ai construit un système automatisé de détection et d'analyse de phishing qui combine l'automatisation des workflows n8n avec l'Agent Builder d'Elastic alimenté par l'IA. Cet article de blog présente l'architecture, l'implémentation et les enseignements tirés de l'analyse de 44 emails de phishing sur trois mois.
Pourquoi cette approche fonctionne
Les filtres email basés sur des règles traditionnelles peinent face aux campagnes de phishing modernes qui utilisent un langage contextuel et des formats d'apparence légitime. En exploitant les grands modèles de langage (LLM) via le pipeline d'inférence d'Elastic, nous pouvons analyser la sémantique des emails, extraire les motifs malveillants et catégoriser les menaces avec une précision dépassant 95 %. L'intégration avec n8n offre une automatisation fluide, tandis qu'Elastic Agent Builder permet aux analystes de sécurité d'interroger les résultats en langage naturel.
Démarrage avec Elastic : Si vous débutez avec Elastic, consultez le guide de démarrage pour configurer votre déploiement et commencer à explorer les solutions de recherche, d'observabilité et de sécurité d'Elastic.
Composants de l'architecture
Automatisation des workflows n8n

Le workflow n8n orchestre l'ensemble du pipeline de traitement des emails en quatre étapes :
Le nœud déclencheur initie l'exécution lorsqu'il est activé manuellement ou selon un planning. Le nœud Gmail ("Get many messages") se connecte à votre compte Gmail et récupère les emails non lus via l'API Gmail. Le nœud Split in Batches traite les emails par lots de taille configurable (généralement 10 à 50) pour optimiser le débit et éviter la limitation de l'API. Le nœud HTTP Request envoie chaque email à Elasticsearch via une requête POST vers le point de terminaison du pipeline d'ingestion (https://[your-cluster]:9200/fishfish/_doc?pipeline=phishingornotphishing).
Après l'indexation réussie, le workflow marque les emails comme lus dans Gmail pour éviter un traitement en double. Cette conception modulaire suit les bonnes pratiques n8n en séparant les préoccupations et en permettant à chaque composant d'être testé indépendamment.
Vous pouvez trouver le modèle n8n ici
Pipeline d'ingestion Elasticsearch
Avant de configurer le pipeline d'ingestion, vous devez d'abord configurer un point de terminaison d'inférence qui se connecte à votre modèle d'IA. Elastic simplifie ce processus en fournissant une API unifiée pour gérer les services d'inférence, que vous utilisiez des modèles intégrés, Azure OpenAI, OpenAI, Cohere, Google AI, Anthropic ou d'autres fournisseurs.
Pour créer un point de terminaison d'inférence, utilisez l'API Elasticsearch pour enregistrer la configuration de votre service. Pour Azure OpenAI, la configuration du point de terminaison ressemble à ceci :
PUT _inference/completion/azure_openai_completion
{
"service": "azureopenai",
"service_settings": {
"resource_name": "test-ai",
"deployment_id": "gpt-4",
"api_version": "2024-02-01",
"api_key": "replacehere"
}
}
Une fois enregistré, le point de terminaison d'inférence devient disponible dans tout votre cluster Elasticsearch. Vous pouvez le référencer dans les pipelines d'ingestion, les requêtes de recherche ou toute autre opération Elasticsearch nécessitant une inférence IA. Cette approche centralisée élimine le besoin de gérer les identifiants API et les détails de connexion à plusieurs endroits—Elastic gère l'authentification, la limitation du débit et la gestion des erreurs de manière transparente.
Mapping d'index avec champs de recherche sémantique
Avant d'ingérer des données, vous devez définir un mapping d'index qui spécifie quels champs prennent en charge la recherche sémantique. Elastic simplifie ce processus avec le type de champ semantic_text, qui gère automatiquement la génération d'embeddings et l'inférence au moment de l'ingestion. Contrairement aux champs vectoriels traditionnels qui nécessitent une configuration manuelle du pipeline, les champs semantic_text fournissent des valeurs par défaut sensées et éliminent le besoin d'une configuration complexe du pipeline d'inférence.
Dans l'index fishfish, des champs clés comme content.semantic et subject.semantic sont configurés comme champs semantic_text, permettant des capacités de recherche sémantique. Ces champs génèrent automatiquement des embeddings en utilisant le point de terminaison d'inférence spécifié (dans ce cas, .multilingual-e5-small-elasticsearch pour l'embedding de texte multilingue) lors de l'indexation des documents. La configuration du mapping ressemble à ceci :
{
"fishfish": {
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"content": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
},
"date": {
"type": "date"
},
"extracted_data": {
"properties": {
"category": {
"type": "keyword"
},
"date": {
"type": "date"
},
"reasoning": {
"type": "text"
},
"urls": {
"type": "text"
}
}
},
"from": {
"type": "keyword"
},
"model_id": {
"type": "keyword"
},
"output": {
"type": "text"
},
"reasoning": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
},
"requirements_prompt": {
"type": "text"
},
"subject": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch"
}
}
},
"timestamp": {
"type": "date"
}
}
}
}
}
Avec les champs semantic_text, Elastic génère automatiquement des embeddings lors de l'ingestion sans nécessiter de processeurs de pipeline d'inférence explicites. Cela signifie que les documents indexés dans l'index fishfish ont automatiquement des embeddings sémantiques créés pour les champs content.semantic, subject.semantic et reasoning.semantic, permettant des requêtes de recherche sémantique qui comprennent le sens et le contexte plutôt que de simples correspondances de mots-clés exacts.
Le pipeline d'ingestion phishingornotphishing effectue ensuite une catégorisation intelligente en utilisant le modèle de complétion Azure OpenAI préconfiguré ci-dessus:
PUT _ingest/pipeline/phishingornotphishing
{
"description": "Catégoriser les emails en 3 catégories : valide, marketing, phishing",
"processors": [
{
"set": {
"field": "requirements_prompt",
"value": """
Vous êtes un analyste en cybersécurité. Extrayez et catégorisez les données d'email suivantes. Retournez UNIQUEMENT du JSON valide sans texte supplémentaire.
Données d'entrée :
- Contenu : {{content}}
- Sujet : {{subject}}
- Auteurs : {{from}}
- Date : {{date}}
Exigences :
1. Définissez le champ date au format ISO8601
2. Extrayez toutes les URL du champ Contenu. Extrayez-les du code HTML si nécessaire
3. Catégorisez l'email comme l'un des suivants : "valide", "marketing" ou "phishing" en fonction du Contenu, du Sujet et des auteurs
4. Expliquez votre raisonnement
5. Retournez du JSON avec ces champs : date, urls, category
Format JSON :
{
"date": "date_ISO8601_ici",
"urls": ["url1", "url2"],
"category": "valide|marketing|phishing",
"reasoning": "raisonnement_ici"
}
""",
"ignore_failure": true
}
},
{
"inference": {
"model_id": "azure_openai_completion",
"input_output": [
{
"input_field": "requirements_prompt",
"output_field": "output"
}
]
}
},
{
"json": {
"field": "output",
"target_field": "extracted_data",
"ignore_failure": false
}
},
{
"set": {
"field": "category",
"value": "{{extracted_data.category}}",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "timestamp",
"value": "{{extracted_data.date}}",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "urls",
"copy_from": "{{extracted_data.urls}}",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "reasoning",
"copy_from": "{{extracted_data.reasoning}}",
"ignore_empty_value": true,
"ignore_failure": true
}
}
]
}
Le processeur set construit un prompt détaillé instruisant le LLM à agir comme un analyste en cybersécurité. Il inclut les métadonnées de l'email (contenu, sujet, expéditeur, date) comme variables de contexte. Le processeur inference appelle le modèle Azure OpenAI, qui analyse l'email sémantiquement pour détecter les indicateurs de phishing comme l'urgence, les URL suspectes et les tactiques d'ingénierie sociale. L'IA extrait les URL à la fois du texte brut et du balisage HTML, normalise les dates au format ISO8601, attribue une catégorie (valide/marketing/phishing) et fournit un raisonnement lisible par l'homme. Enfin, le processeur json analyse la réponse de l'IA et mappe les champs aux propriétés de document consultables. Cette approche sémantique surpasse les filtres basés sur des mots-clés en comprenant le contexte, l'intention et les modèles linguistiques utilisés dans les campagnes de phishing.
Configuration d'Elastic Agent Builder
En savoir plus : Pour des instructions d'installation détaillées et les options de configuration, consultez le guide de démarrage d'Elastic Agent Builder.
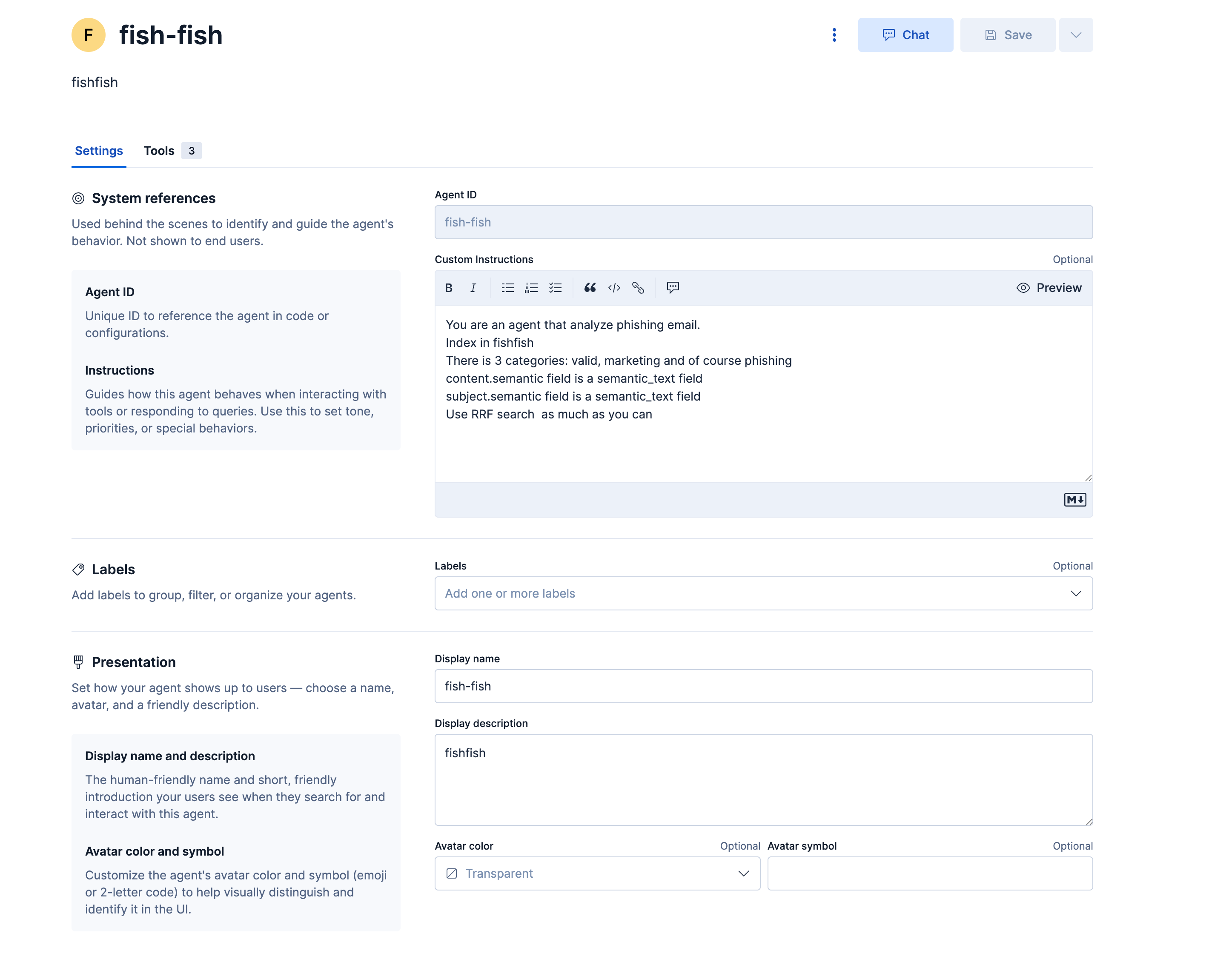
L'agent "fish-fish" fournit une interface interactive permettant aux analystes de sécurité d'interroger les données de phishing de manière conversationnelle :
Les instructions système définissent le rôle de l'agent : "Vous êtes un agent qui analyse les emails de phishing. Index dans fishfish. Il y a 3 catégories : valide, marketing et bien sûr phishing. Le champ content.semantic est un champ semantic_text. Le champ subject.semantic est un champ semantic_text. Utilisez la recherche RRF autant que possible".

L'agent a accès à trois outils de plateforme : platform.core.execute_esql exécute des requêtes ES|QL contre l'index fishfish, platform.core.generate_esql convertit les questions en langage naturel en syntaxe ES|QL, et platform.core.get_index_mapping récupère la structure de l'index et les types de champs.
Les champs de recherche sémantique (content.semantic et subject.semantic) permettent des recherches de similarité vectorielle qui trouvent des emails conceptuellement liés au-delà des correspondances exactes de mots-clés. Ces champs utilisent le type semantic_text configuré dans le mapping d'index, qui génère automatiquement des embeddings lors de l'ingestion des documents. L'agent utilise la Fusion de Rang Réciproque (RRF) pour combiner les résultats de plusieurs stratégies de recherche afin d'améliorer la précision.
Serveurs d'intégration intégrés
Elastic Agent Builder est livré avec deux serveurs d'intégration intégrés qui permettent une connectivité transparente avec les clients IA externes et la communication agent-à-agent :
Le serveur Model Context Protocol (MCP) fournit une interface standardisée pour que les clients externes accèdent aux outils d'Elastic Agent Builder. Le serveur MCP est disponible à {KIBANA_URL}/api/agent_builder/mcp et permet aux clients IA comme Claude Desktop, Cursor et les extensions VS Code d'interagir avec vos outils Elastic via JSON-RPC 2.0. Pour vous connecter, configurez votre client avec votre URL Kibana et une clé API qui inclut les privilèges d'application read_onechat et space_read. Cela permet aux analystes de sécurité d'interroger les données de phishing directement depuis leurs environnements de développement IA préférés sans changer d'outils.
Le serveur Agent-to-Agent (A2A) permet la communication agent-à-agent selon la spécification du protocole A2A. Il fournit des points de terminaison pour que les clients A2A externes interagissent avec les agents d'Elastic Agent Builder, facilitant la communication entre différents agents IA dans votre infrastructure de sécurité. Le point de terminaison Agent Card (GET /api/agent_builder/a2a/{agentId}.json) retourne les métadonnées pour un agent spécifique, tandis que le point de terminaison du protocole A2A (POST /api/agent_builder/a2a/{agentId}) gère les interactions agent-à-agent. Les deux points de terminaison nécessitent une authentification par clé API, garantissant une communication sécurisée entre les agents de sécurité distribués.
Ces serveurs intégrés éliminent le besoin de code d'intégration personnalisé, permettant aux organisations d'étendre leur système de détection de phishing en connectant Elastic Agent Builder avec d'autres outils de sécurité alimentés par l'IA, des plateformes d'automatisation de workflows et des systèmes multi-agents. Cela crée des opportunités pour des cas d'usage avancés comme le partage automatisé de renseignements sur les menaces, l'orchestration de sécurité multiplateforme et la collaboration d'agents distribués.
Analyses et enseignements du monde réel

Après avoir traité 44 emails de phishing sur trois mois, le système a révélé des modèles d'attaque et des tendances critiques.
Analyse des modèles d'attaque
Les arnaques de cadeaux/prix gratuits dominaient à 40 % de toutes les tentatives de phishing. Ces emails utilisaient des lignes d'objet en français comme "Récupérez votre cadeau" et "Vous avez gagné...". Les appâts courants comprenaient des ensembles d'outils Parkside/Lidl, des coffrets beauté Lancôme, des appareils Silvercrest, des produits de cuisine Tefal, l'iPhone 17 Pro Max et des packs d'outils RYOBI. Les attaques créaient un sentiment d'urgence en prétendant une disponibilité limitée ou des offres expirantes.
Les arnaques de livraison de colis représentaient 30 % des emails de phishing. Celles-ci présentaient des lignes d'objet comme "Vous avez (1) colis en attente de livraison". Les tactiques comprenaient la prétention de colis suspendus, la demande de frais de douane impayés, la demande d'action immédiate pour "planifier la livraison" et l'utilisation de codes de suivi fictifs pour paraître légitimes.
Les arnaques de confirmation de commande représentaient 15 % des tentatives. Celles-ci envoyaient de fausses confirmations de commande avec des numéros de commande comme "commande n°[48754-13] confirmée". Elles créaient de la confusion concernant des articles non achetés et incluaient une urgence à vérifier les commandes rapidement.
Les arnaques de vérification de compte comprenaient 10 % des emails de phishing. Celles-ci utilisaient des lignes d'objet comme "Vérification KYC" ou "Important : Confirmez votre compte". Elles demandaient une vérification immédiate du compte et menaçaient de suspension du compte si elle n'était pas effectuée.
Distribution par catégorie

La requête Agent Builder "Quel est le ratio entre le vrai phishing et le faux phishing ?" a révélé la composition globale des emails :
Emails de phishing : 51 (59,3 %) identifiés comme menaces malveillantes nécessitant une action immédiate. Emails marketing : 23 (26,74 %) contenu promotionnel légitime mais potentiellement indésirable. Emails valides : 12 (13,95 %) correspondance authentique provenant de sources de confiance.
Le ratio de 1,46:1 entre phishing et emails légitimes démontre la gravité du paysage des menaces. Pour chaque email légitime, le système a détecté environ 1,46 tentatives de phishing.
Conclusion
Cette intégration de n8n, Elasticsearch et d'analyse alimentée par l'IA crée un pipeline robuste de détection de phishing qui traite les emails en temps réel, catégorise les menaces avec une compréhension sémantique et fournit des renseignements exploitables via des requêtes conversationnelles. La conception modulaire du système permet à chaque composant d'être optimisé indépendamment tout en maintenant une automatisation de bout en bout. Les organisations mettant en œuvre des architectures similaires peuvent s'attendre à des temps de réponse aux incidents réduits grâce au triage automatisé, à des taux de faux positifs plus faibles via l'analyse sémantique, à une meilleure visibilité sur les modèles d'attaque et les tendances, et à une charge de travail réduite pour les analystes en automatisant les tâches de classification de routine. Alors que les attaques de phishing continuent d'évoluer, combiner l'automatisation des workflows avec l'inférence IA fournit une approche évolutive et maintenable de la sécurité email qui s'adapte aux menaces émergentes.