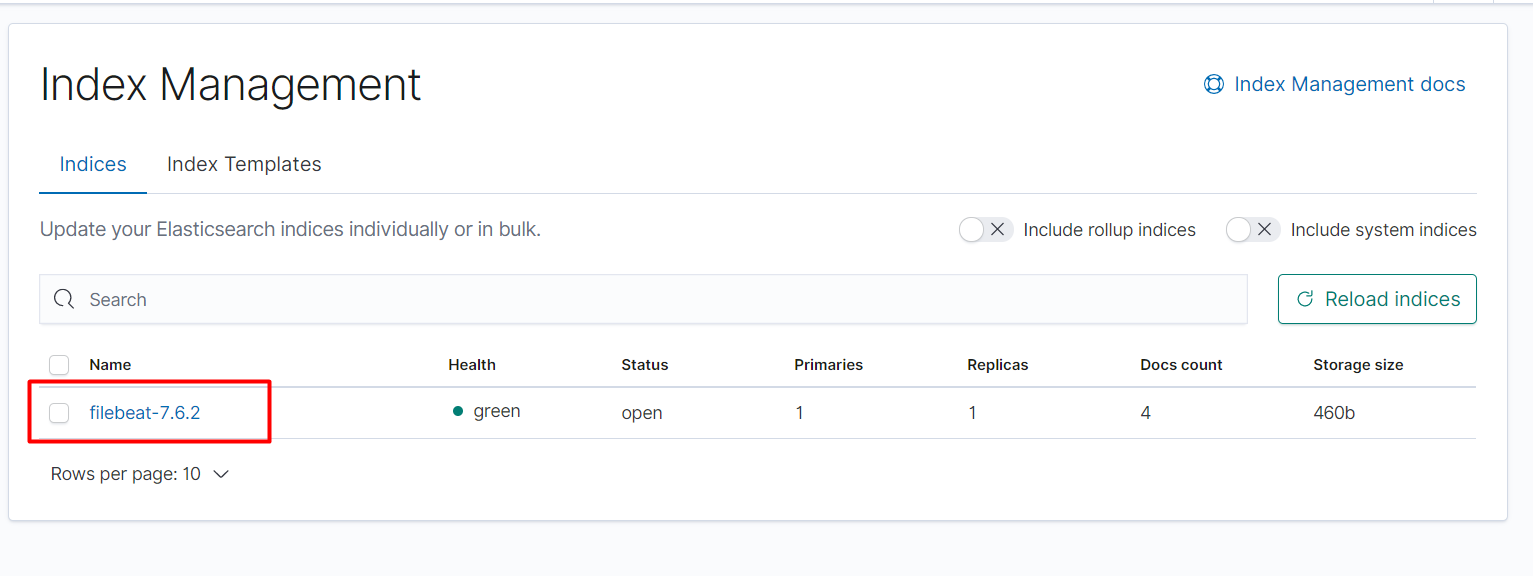
We are running into an issue where setting the ILM policy via filebeat config with the default index pattern of filebeat-7.6.1-%{now/d}<del>000001</del> but instead the index gets the name filebeat-7.6.1 and that seems to ruin the ILM setup, as the index template doesn't match (it's looking for filebeat-7.6.1*) and thus the ILM policy doesn't get applied to the index.
Reproduce steps : Need to delete current correct index on running filebeat and it recreate index with wrong name.
What were you trying to achieve when deleting these indexes? It is usually not needed to delete filebeat-<version>.
The issue you mention is somehow expected. filebeat-7.6.1 is an alias, not an actual index, maintained by ILM for the rollups. Filebeats write to this alias, and the alias redirects the data to the actual indexes (the ones with format filebeat-7.6.1-<timestamp>-<number>). Deleting this alias while filebeat is running leads to problems. Filebeats will continue sending data, but as there is no index or alias with this name, Elasticsearch will create a new index with without any kind of mapping or configuration.
If you want to remove indexes with filebeat data, you have to remove the actual indexes (filebeat-7.6.1-*), but not the aliases where Filebeats write to. If you want to remove old data, you can consider adding a rule to your ILM policy for that, so it is done automatically.
If for some reason you also really want to remove the alias where filebeats are writing, you need to stop filebeat, or somehow stop accepting data from them, so new indexes are not unexpectedly created.
Without ILM, removing the indexes where Filebeat is writing to them can be also problematic, because Elasticsearch will create new indexes without mappings.
@jsoriano So you don't recommend to delete index manually to avoid this bug?
In our case ILM not worked properly and index grows dramatically that why we deleted it.
And I expected another behavior, doesn't I?
By the way I deleted an index filebeat-7.6.1-<timestamp>-<number>, not an alias.
Well, I would say that deleting the alias where filebeats are actively writting on is not supported There is little that can be done if the data destination is removed. Imagine what would happen in a database where you remove the tables where you are writting to, expect problems
If this really happened after deleting one of the indexes, and not the alias where filebeats are writing to, then there would be something to investigate.
I see in the first screenshot that Kibana was reporting lifecycle erros, what were these errors? Maybe these could help to diagnostic the problems.
Something you can do when having problems with ILM is to query the explain endpoint:
GET filebeat-7.6.1/_ilm/explain
You can do it on the rollup alias or on any on the indexes. If you do it on the alias, it will show the current state of all the indexes managed by this alias.
In the second screenshot filebeat-7.6.2 is an index, not an alias, this is why I thought that the alias created for ILM was removed.
If you are using ILM as is used by default, the way to fix this situation would be to:
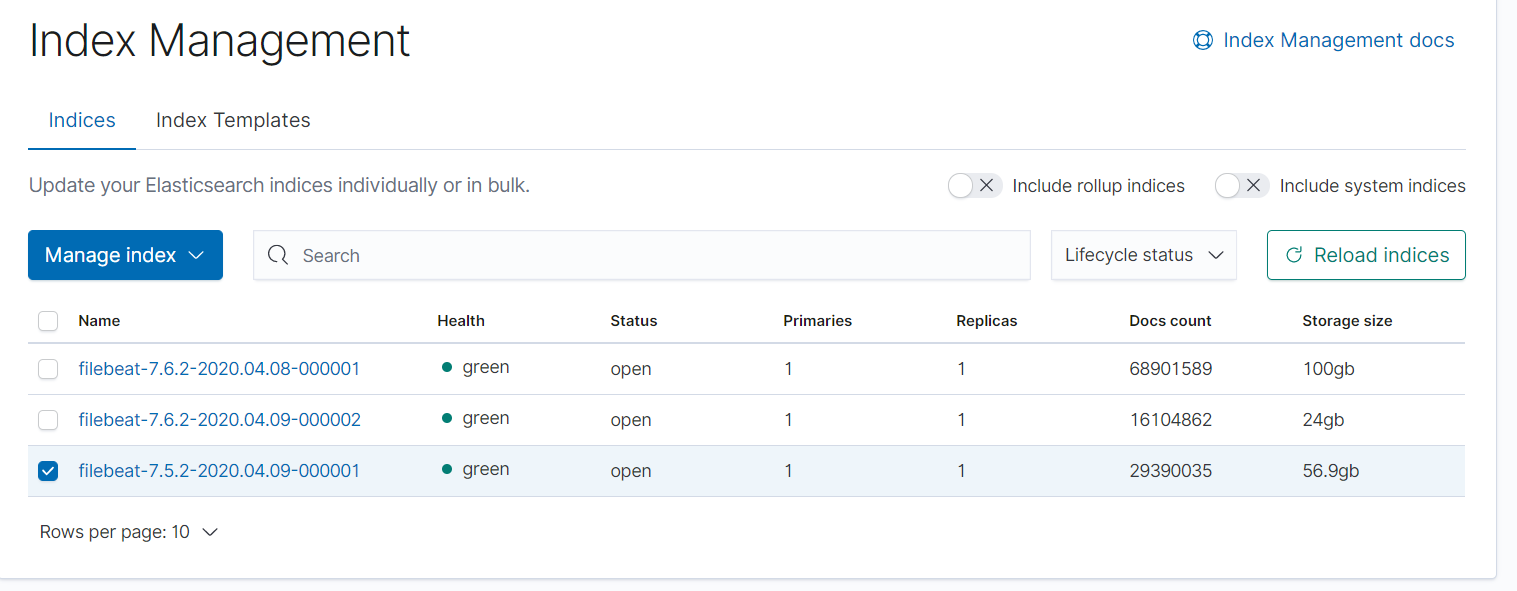
Stop all filebeats writing to filebeat-7.6.2.
Remove or rename filebeat-7.6.2 index.
Start filebeats again.
Then if ILM is not creating new indexes when they are 30 days old, or they contain more than 50GB, then let's investigate from there without removing anything.
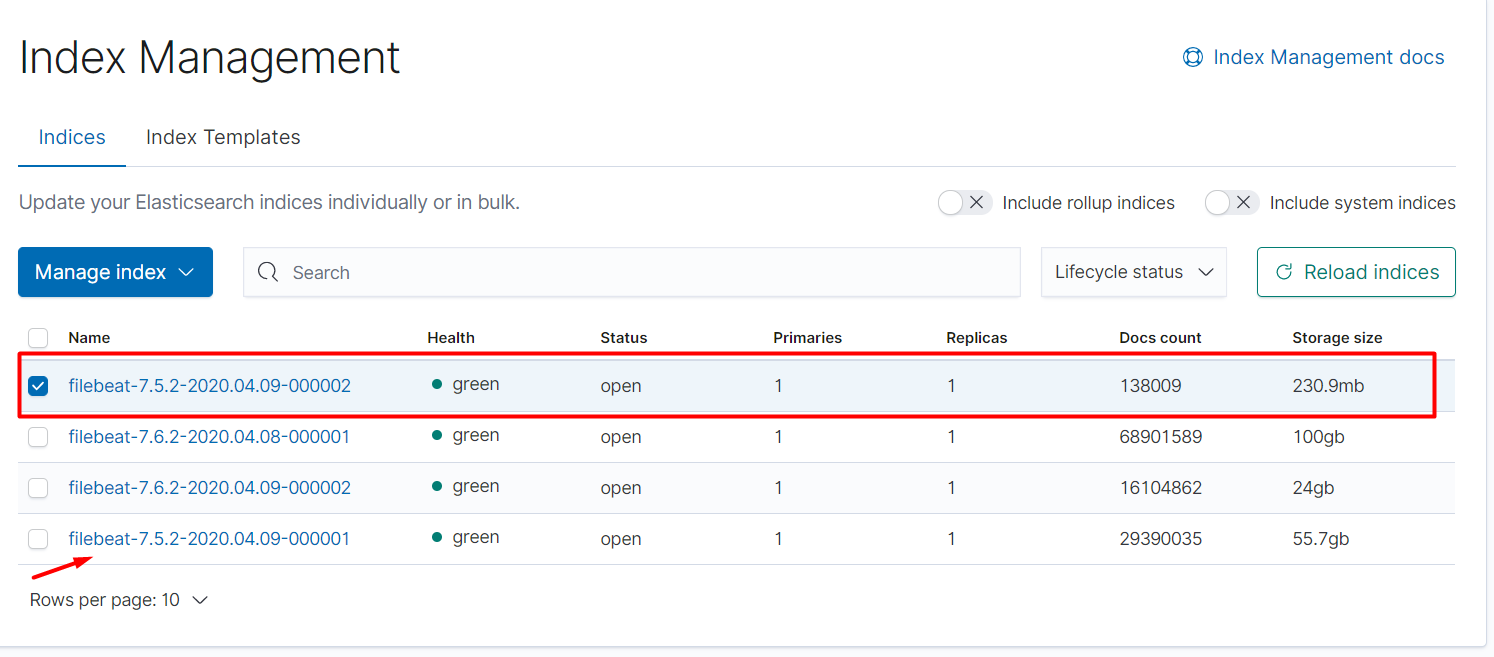
@jsoriano Let me explain more detailed: Filebeat starts and created index filebeat-7.6.2-<timestamp>-<number>, for ex. filebeat-7.6.2-2020.04.03-000001, then it grows to 300Gb and we reach the limit on storage, than I deleted index and filebeat recreated it but with name filebeat-7.6.2. It was not expected by me, I expected to see filebeat-7.6.2-2020.04.08-000001 again or smth like this.
So why filebeat can't recreate index regarding it's pattern? Why I need start/stop it for correct work?
Your fix works but this is not that everyone expects I guess.
Ok, my mistake, I have been doing some tests, and an alias cannot exist without any index. So if you only had a filebeat index, when you removed it, the alias was removed too, and then Elasticsearch created the empty index when more data was received. I agree that it can be quite unexpected (I also get confused by that here), but in principle indexes shouldn't need to be manually removed.
This looks more worrying, because this shouldn't happen. Default configuration sets a size limit of 50GB. If it is reached, a new index should be created. It'd be good to see the lifecycle errors reported by Kibana that can be seen in your first screenshot, do they appear now?
Can you also execute the following request in the developer console and paste here the response?
GET filebeat-7.6.2/_ilm/explain
If you need to remove the current write index, you can do it, but you need to do a rollover first, this can be done with:
POST filebeat-7.6.2/_rollover
This will create a new index, and keep the old one as part of the same alias, but for read only. Then this old index can be deleted.
Sorry, actually answering this question now Filebeat only sets up ILM on startup, the rest of the time it is only sending data to the alias that should be there. The stop is needed to avoid Elasticsearch creating new indexes when new data is received, the start is needed to create the ILM setup. Alternatively filebeat setup could be used too to configure ILM, but it won't do anything if there is already an index with the same name as the alias, thus the stop (or some way to prevent Elasticsearch receiving new data) is needed in this situation.
If it is reached, a new index should be created. It'd be good to see the lifecycle errors reported by Kibana that can be seen in your first screenshot, do they appear now?
Unfortunately it was different ELK cluster, so the screen only shows how healthy index should be named.
Could you please advise how index should be rollover if there is there is no free space on ES storage?
Well, the idea would have been to avoid reaching this point In any case a rollover doesn't create more data, it creates a new empty index and starts using it to write, keeping the old one for read only. But yes, I don't think this would have worked if there was no available space at all.
@jsoriano I have checked filebeat version 7.5.2 and it has same problem.
By the way the problem is next:
We started filebeat, and it configure ILM by default:
Your index templates and index lifecycle policies look good. The names of the index lifecycle policies don't have anything to do with the index patterns, so it is ok if they don't match (actually they don't match with the default config).
You see two index lifecycle policies because before 7.6.0, index lifecycle policies were created for each version. This has the problem that custom modifications to the policy have to be done after every upgrade, what is quite cumbersome. Since 7.6.0 filebeat policy is used, so users can modify the policy and changes persist after upgrades.
When you say that you do rollover index, do you mean that you do it manually because it is not done automatically? I think that this is the main issue to investigate here, rollover should be done automatically.
When this happens, please run:
GET filebeat-<version>/_ilm/explain
And post here the result.
It seems that your 7.6.2 indexes roll over when they reach 100GB, did you modify the ILM policy for that? The default is at 50GB.
The *-000002 is the new index, where filebeat is writing at this point. Usually in these cases you want to delete the old indexes. Deleting the index where filebeat is currently writing leads to unexpected behaviours. It seems that in your case filebeat gets back to write to the old *-000001 index after removing the new one. It could be also good to see the output of GET filebeat-7.5.2/_ilm/explain at this point.
I agree that doing all this manually is error-prone, but it is really very rare that it has to be done this way, and when done the most important thing to take into account is to avoid removing the index where filebeat is writing to.
I don't know the reason but it doesn't work as I expected, please look at index filebeat-7.6.2-2020.04.10-000005, it was not rollovered in time, as some others.
You are right, this filebeat-7.6.2-2020.04.10-000005 index should have been rolled over earlier. Is it working now for current indexes? Does it work for some indexes and not for others?
If it is still happening, could you run this command to see if there is some ILM pending task?
GET /_cluster/pending_tasks
Is it possible that your server is under heavy load?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.