After bulk indexing for 10 minutes on a 7.4.1 cluster, it will suddenly become completely unresponsive to any cluster state requests.
It still index's and still responds to queries, but the cluster state itself is unresponsive. After a while nodes will start to leave the cluster if it's left in this state, however, we find if we stop ingestion, it will recover.
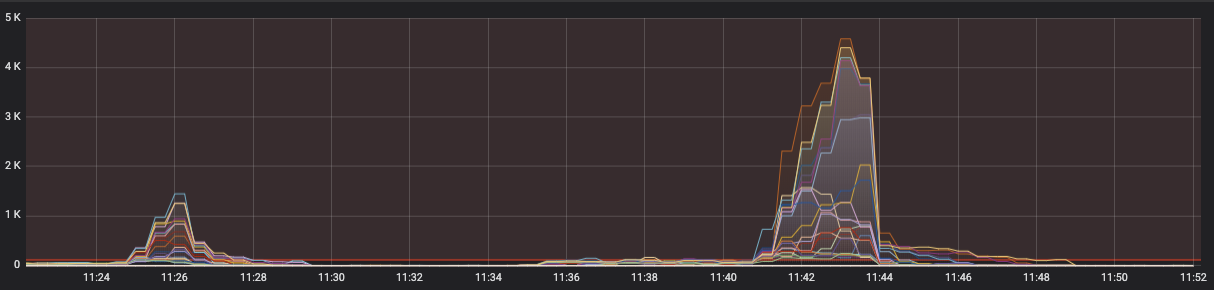
This is the sudden increase in CPU we see across all data nodes in the cluster:
Once we stop ingestion, we find we can go the Data Node with the largest queue and restart ES on it and we are back in business.
Big questions: Why doesn't ES rate limit bulk ingestion? We get no rejections, no 429's, nothing on the write queues. We know these clusters can ingest a lot more, on ES 2 we are doing 50k docs per second on the same hardware and 7.4.1 seems to fall over at 25k per second.
How can we get these management cluster state queues to relax?
As I mentioned in another thread, it would be useful to see what these nodes are so busy doing. I'd try the nodes hot threads API: GET /_nodes/hot_threads?threads=99999. However, this runs on the management threadpool, so if that threadpool is where the problem is then it won't work. If so, please use jmap to grab a thread dump directly from the JVM. Also, of course, if there are any messages in the logs from the time of the problem then they would be helpful.
When you say "nodes leave the cluster" this sounds very bad, but I can't yet see how that is related. We definitely need to see logs from at least (a) the elected master and (b) the node that left for a few minutes either side of its departure. Look for a log message from the MasterService containing the string node-left, and a log message from the ClusterApplierService saying master node changed.
Yeah, we looked at hot threads previously (in another thread on here somewhere I started). It all STATS, completion stats, segment stats, etc. I'm not sure why CompletionStats is even running, we have no "suggesters" or anything like that. We do run with the xpack monitoring on though.
Currently we are trying bumping thread_pool.management.max: 8 to match the cores on the data nodes. We are finding that now they are averaging about 6 active during ingestion, 4 active during idle.
Which gave us the hint to turn off --es.indices from the exporter. But we are still seeing all these CompletionStats ... is there a way to turn off anything to do with completion completely? (Beside staying on ES 2 )
After switching to NVMe SSD storage my problem seems to be fixed. I had to allocate less JVM memory but still elasticsearch works flawlessly without any issues. I will be running this for another day to conclude it.
Yeah, over here still dealing with the app//org.elasticsearch.index.engine.Engine.completionStats(Engine.java:197) always running and sucking up my management threads ... going to attempt to turn off all monitoring tomorrow.
As far as I can tell there's something outside your cluster that is hitting an overly-broad stats API and requesting all completion stats, and the fix is to stop it from doing so. Completion stats are expensive to compute, even if you are not using completion, and you should avoid requesting them if possible. The indices stats API lets clients select the metrics they need, so if you do not need completion stats then you should stop requesting them. I think it's something outside the cluster because Elasticsearch's own monitoring does the right thing here, only requesting the stats it needs:
I think this is trappy, btw, and since there's a few similar cases on the issue I opened https://github.com/elastic/elasticsearch/issues/51915 to discuss a possible improvement. I do also think that we are missing documentation that these stats are expensive to compute.
Thanks David. That's the conclusion I'm coming to as well. Big cluster means big stats. Hopefully the load balancer on the coordinator nodes points me at what is doing it ...
I agree with the issue you posted, this was unexpected as we don't use any suggesters and I've also seen a lot of cases out there. I'll keep this ticket posted
I'm hoping to wind up with 0 completionStat mentions showing in my hot_threads. Currently I get about 250 occurrences curl -XGET localhost:9200/_nodes/hot_threads | grep completionStat | wc -l
@DavidTurner saved the day! So once that was confirmed started watching for who was calling /_cluster/stats and found "NetData" hang out on all our AMI's that we'd forgotten about. It saw Elasticsearch running locally and began calling _cluster/stats every 5 seconds! Per data node, * 24 data nodes. We removed the service and the CPU just started dropping. Thanks for watching the forums!
To give props where it's due: Elasticsearch 7.4.1 was dealing with a massive state query every 5 seconds from 32 different nodes and yet didn't stop ingesting data or responding to queries. Anything that didn't touch cluster state still responded. That's pretty awesome.
Yes, it would've been nice to have got rejection notices for cluster state, but at least it was doing it's core business.
Good catch, yes, that'd explain it. 5 cluster-wide stats calls per second is definitely on the abusive side. When you weren't indexing it looks like you had enough resources (particularly, IO bandwidth) to cope with the monitoring load, but it seems that the extra load from indexing pushed it over the edge.
I think we can generally do better here, optimisations of the completion stats calculation aside, so I opened https://github.com/elastic/elasticsearch/issues/51992 to discuss higher-level protection against this.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.





 )
)
