Hi 
So, we are currently performance testing our CCR setup to get some kind of understanding on how much more hardware we need to accomplish the same indexing numbers as without CCR.
As said in the title, we are running a CCR setup like this:
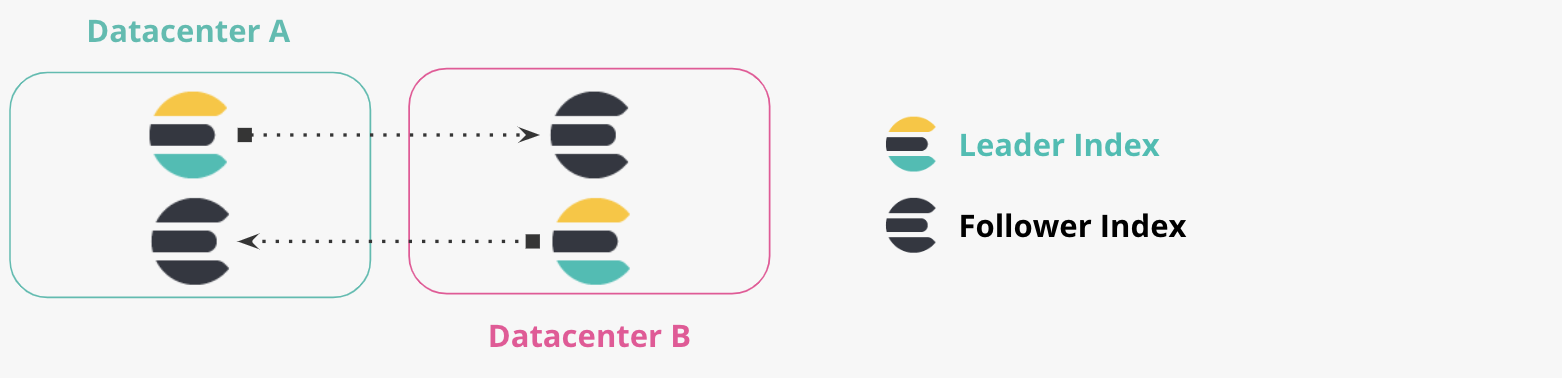
Where each datacenter (DC) has 3 ES nodes (3 primary shards one replica) on m5.large AWS machines.
Ok, when putting on an unbound load to index some documents (CCR disabled) we see a CPU consumption which looks like this:

As expected, indexing uses most of the CPU which is fine.
If we turn on CCR now, we see a consumption like this:
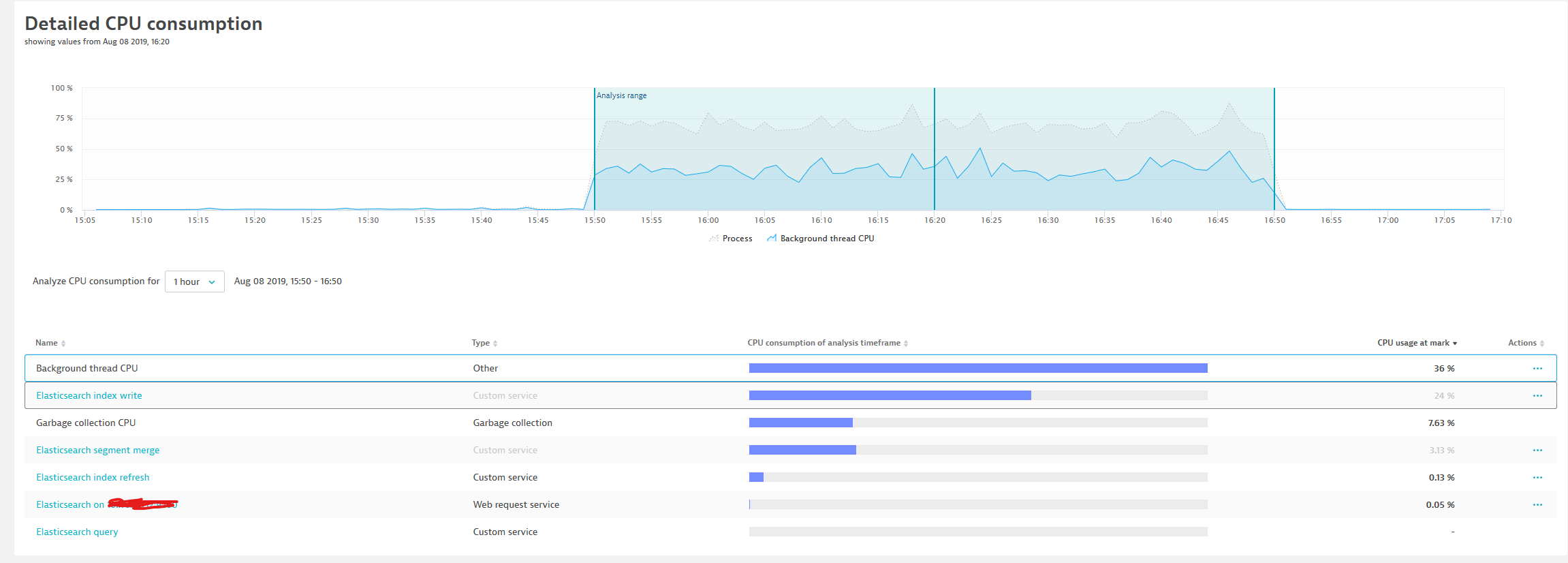
Way less "writing" but the Background thread CPU kicks in - which I assume are CCR related tasks like reading, unpacking lucene stored blocks and indexing (?) those.
We did see, that the indexing rate is going down for like ~40-45% which is expected, just because of the nature of our BI-directional setup.
So, my two questions are:
- What steps in CCR are involved that generate such a high load for the CPU ?
- Is there a rule of thump for calculating on how much hardware we have to add that we can accomplish the same numbers as without CCR ? Right now, we cannot tackle that one down. We increased the power of the AWS machines which basically had no impact at all.
Thank you in advance!
