I’ve upgraded from Elasticsearch 8.19 to 9.2.1. Since doing so none of the cluster nodes will start, the error message in the cluster log:
java.lang.IllegalStateException: The index [.reporting-2021-12-12/EzaQTB1HR8OZ5oH7RhbL0Q] created in version [7.16.1] with current compatibility version [7.16.1] must be marked as read-only using the setting [index.blocks.write] set to [true] before upgrading to 9.2.1.
I did use the Upgrade Assistant to remediate any problematic indexes prior to the upgrade, however I don’t remember it mentioning any .reporting-* indexes.
As the cluster will not start I can’t do anything with these indexes - is there anyway to force the cluster to start so I can simply delete these indexes?
There old indices that need upgrading are easy to miss when looking at Upgrade Assistant. I hit exactly same issue, just missed that I had to actually press a button. A couple of other people have also reported same.
I think best option is quickly re-install to 8.19.whatever, and check the Upgrade Assistant again.
Thanks for getting back to me; a quick search shows that Elasticsearch does not support downgrades - is it really a case of just removing the 9.x packages and installing the 8.x ones? According to the AI response on Google:
”The data path contains version information that prevents direct rollback.”
Thanks - yes they were on 8.19, the Elasticsearch service was shutdown on all nodes and then the packages were upgraded to the latest 9.x after which the cluster would not start
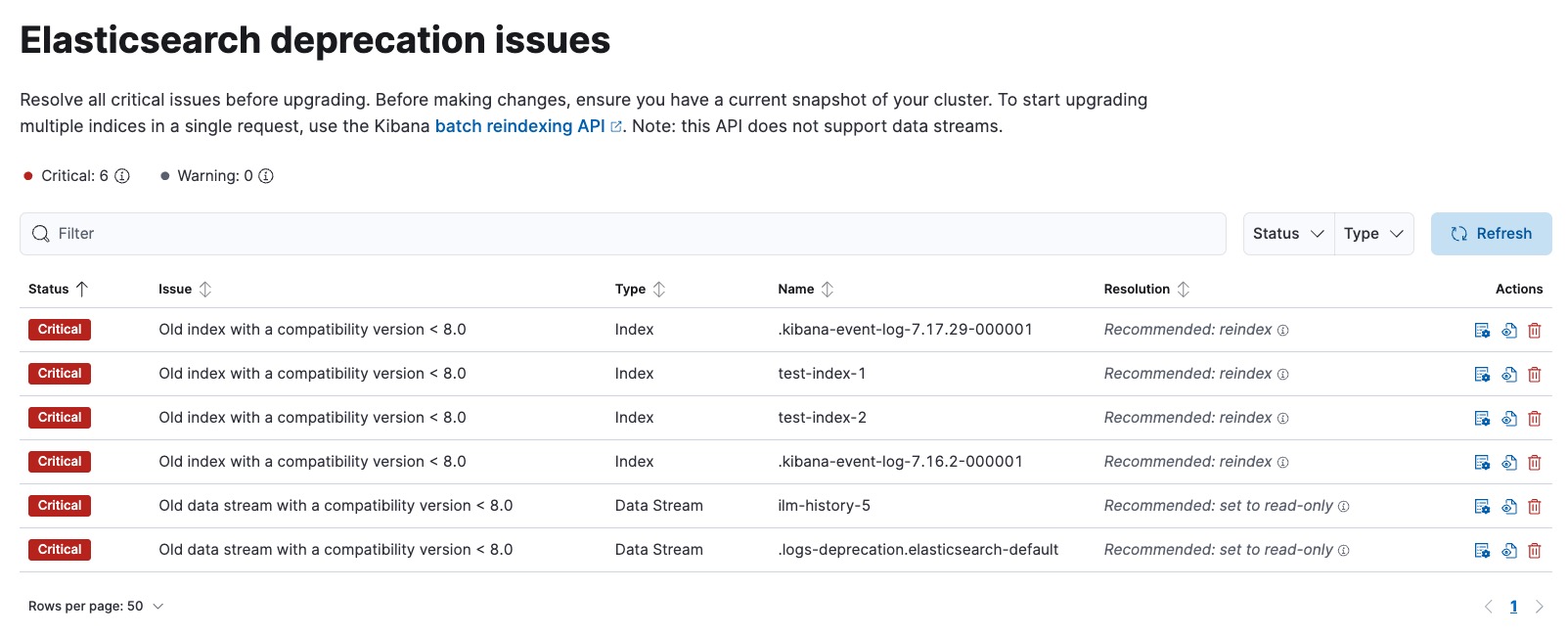
I did a fresh install on test system of 7.16.2, and created 2 test indices.
Then upgraded to 7.latest, did whatever the Upgrade Assistant told me to do.
Then upgraded to 8.latest, and see I need effective do 2 steps
migrate system indices
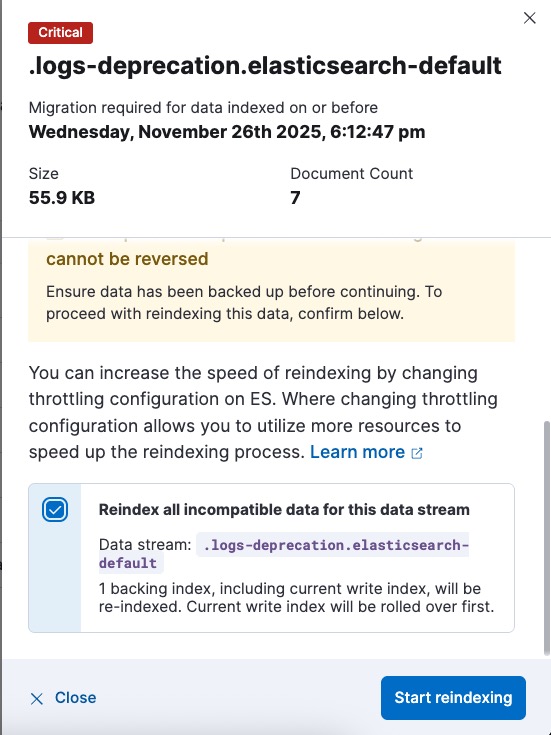
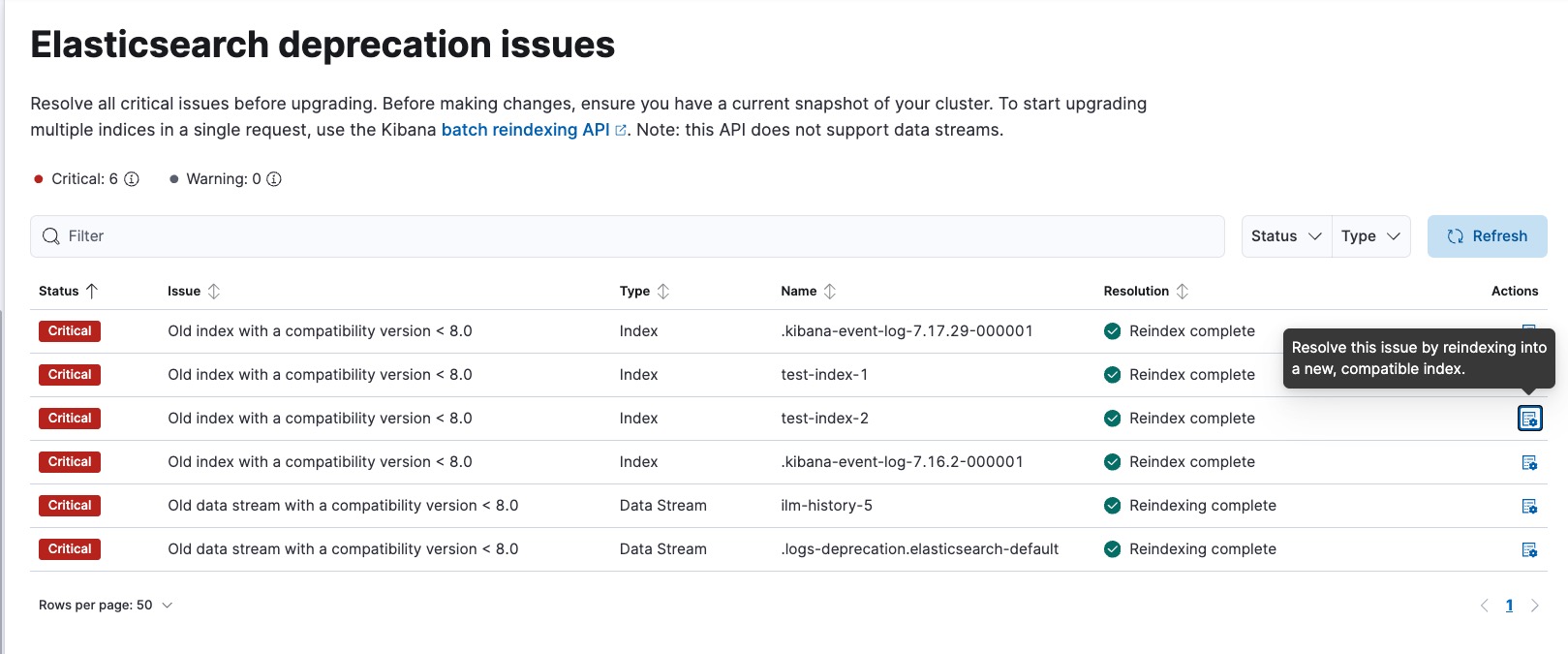
re-index (one option from 3, I could have deleted them or made read-only) 6 other indices, 2 of which were from data streams. I chose reindex for all of them
Then upgrade assistant was happy and I could upgrade to 9.latest
Thanks for your efforts Kevin - I suppose its just reverting the packages from 9.x to 8.x that worries me - yes the cluster doesn’t start (well it does for a few seconds until it sees indexes that it doesn’t like) but presumably the upgrade process to 9.x will have updated metadata and things like that, so when I go back down to 8.x it may not like it.
All I can do is snapshot the VMs and give it a go I suppose.
I did exactly that. Someone else on here who had same issue did same thing.
Yep. Good luck. I am pretty sure you will be fine. With a full VM snapshot you have little to lose. Obviously the Upgrade Assistant did prompt you (and me!) to make a snapshot backup before you embarked on the 8.x → 9.x upgrade, its in the screenshots
Yeah understand about the snapshots - I did snapshot one node as part of upgrading the OS but afterwards VMware said the snapshot size was 34 TB! As I have 5 nodes I balked at doing any more snapshots.
It is a strange that something like an index compatibility is enough to stop the cluster from starting; surely it would have been better for 9.x to just treat incompatible indexes as read-only and still allow you to start the cluster and then remediate these indexes.
Anyway will report back here on the reversion to 8.x
Here I meant elasticsearch snapshots. Not VM snapshots. These snapshot, well whatever you ask them to snapshot, but typically it’s dominated by the indices themselves.
Well, someone from elastic can maybe comment on that. But I really want (as a minimum) software to be consistent with its own documentation, and this aspect is documented.
As I thought, it’s not saying anything about the .reporting-* indexes that were stopping the 9.x version from starting - is there something I’ve missed?
System indices migration - no I hadn’t and as I’m typing this i’m seeing the “This is only required during major version upgrades. Any hidden indices that need to be reindexed are shown in the next step.” - and this obviously is a major version upgrade
I hit the same issue as @kernelpanic at some point, I made a somewhat similar oversight, and was a bit confused as I’d thought my cluster did not exist on 7.x.
I ran that once before clicking through all the Migration Assistant steps, then again after, and compared. Trust, but verify
Thanks for contributing guys - I think the problem here as me not following the Upgrade Assistant guidance on migrating system indices (which presumably includes the .reporting-* ones) - I just jumped straight to the indexes with warnings next to them and didn’t follow previous steps.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.