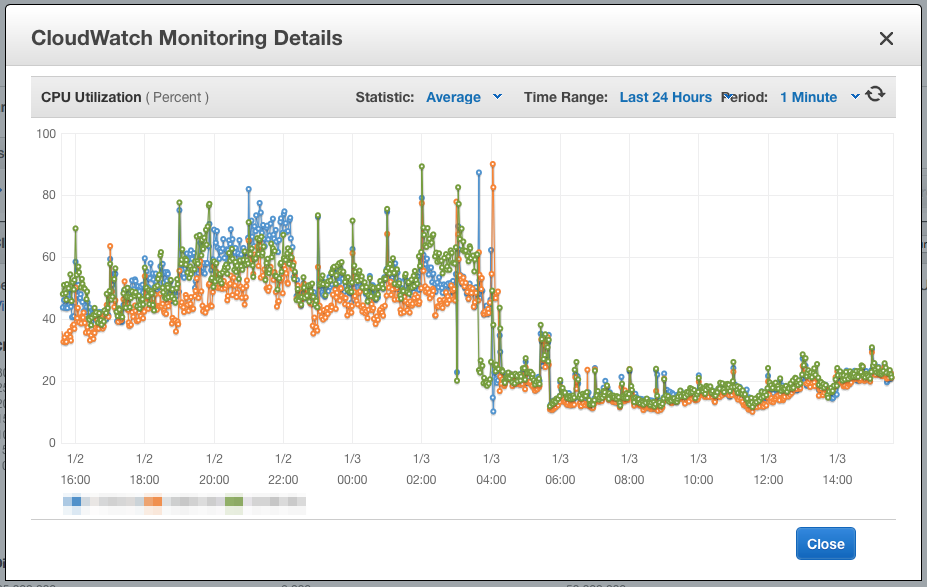
We're seeing kind of an annoying issue with our ES cluster which is that after 7-10 days (this is not a science, it's just whenever the problem becomes bad enough) the CPU ES is using is 2-3x more than after a service restart.
Let me put this a slightly other way just for clarity... ES runs fine for a while then all of a sudden we notice CPU usage start climbing even though the load (requests we're sending to ES) is the same. It climbs, and climbs and climbs until the latency of the search requests becomes high enough that is starts to affect availability. So we restart ES. Boom, just like that, with the same load as pre-restart we save 2-3x CPU and things will smooth out like this for again, 7-10 days until it all happens again. We've been in this loop now for 6 weeks.
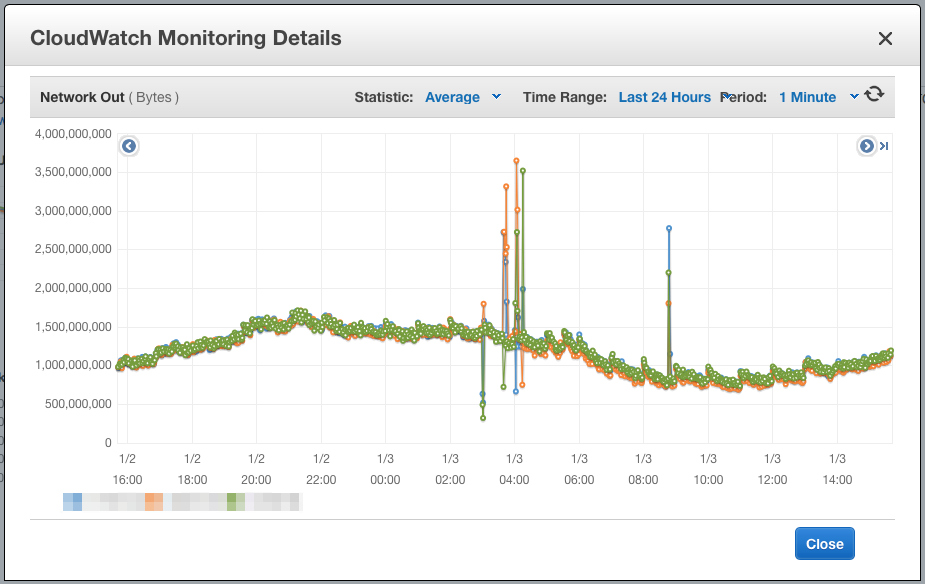
Has anyone seen anything like this? Here are some graphs of before/after a restart (~4:00 on the graph, you can see the network doesn't change but then look at that CPU difference!)
This is ES 1.7.3 (java 1.8.0_66) running on AWS c3.2xlarge's (15GB RAM) with a 7.5GB heap. I don't see Marvel reporting anything strange during these events. Aside from latency climbing with CPU, there is nothing out of the ordinary that I am able to discern.
Thanks in advance to anyone who can help shed some light, cheers!
What does the hot thread API show when the CPU utilisation is high? Is there anything in the logs that differ from when the cluster has been restarted?
I'll be sure to grab some snapshots when this happens next (in a week or so's time). We restarted the service last night so right now everything is running good. Here's a few grabs form right now, although ES is operating within the normal expectations right now.
For the sake of any other potential user searching around and finding this thread, over on this other post here it was mentioned that switching from G1 GC to CMS solved another user having a similar issue as this. We made this change on our stack and low and behold, this problem went away.
We even ran both GC's simultaneously on different nodes and the G1 nodes continued to act up while the CMS node was fine. It's been 15 days now and the CMS node hasn't needed a restart. Hope this can help any one who comes across this bizarre problem.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.