I'm new to Kibana and have an issue I'm trying to resolve.
I have some JSON that is similiar to the following:
"service": {
{
"protocol": "tcp",
"port": "80",
"address": "127.0.0.1"
},
{
"protocol": "tcp",
"port": "80",
"address": "192.168.0.1"
},
{
"protocol": "tcp",
"port": "80",
"address": "172.16.0.1"
}
}
It's my understanding that Kibana 4 doesn't support arrays so that data is displayed in Kibana as one big string value under the "service" key. I need to be able to use the "address" field for visualizations and other analytics so I modified the script that parses the source data to add an index field for each instance. For example:
"service": {
"0": {
"protocol": "tcp",
"port": "80",
"address": "127.0.0.1"
},
"1": {
"protocol": "tcp",
"port": "80",
"address": "192.168.0.1"
},
"2": {
"protocol": "tcp",
"port": "80",
"address": "172.16.0.1"
}
}
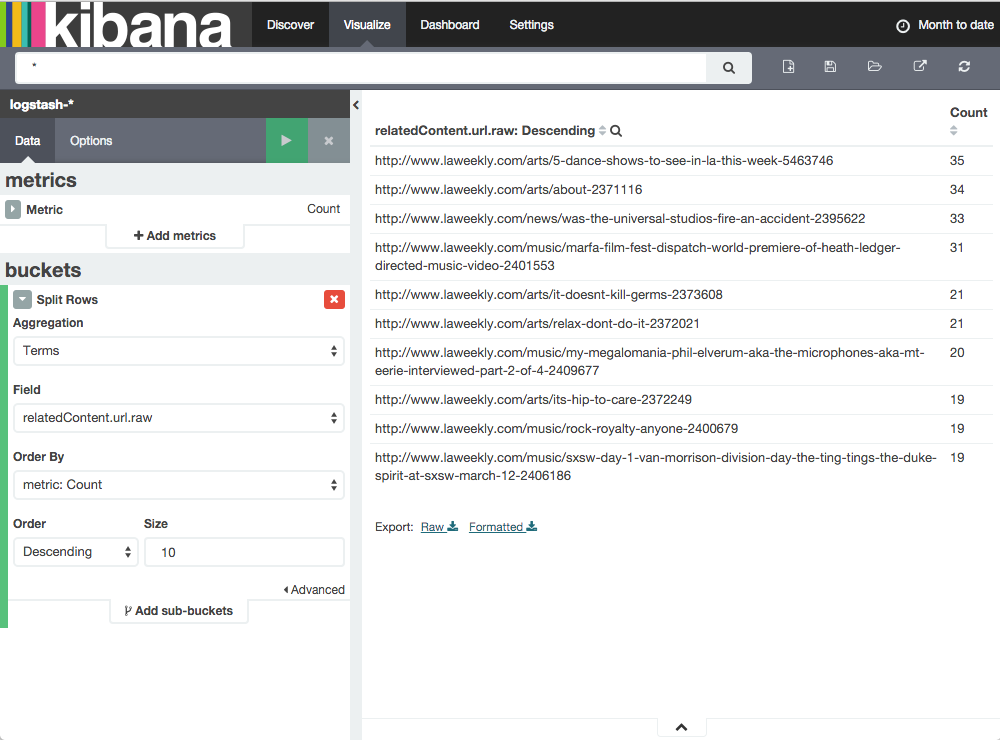
Now I have unique fields like "service.0.address" which is good, but I want to visualize in a data table. Is there anyway to use wildcards in a filter or something that would effectively merge the values into one table? For example, I'd like to display the top 10 addresses found in ANY "service.*.address" field given that the same address value could be located in any one of the address keys.