Cet article est aussi disponible en anglais.

AutoOps vous aide à diagnostiquer les problèmes de votre cluster Elasticsearch en collectant, analysant et corrélant des centaines de métriques en temps réel, fournissant ainsi une analyse des causes profondes et des solutions précises. À chaque détection de problème, AutoOps le suit et l'affiche sur une timeline comme celle ci-dessous. Vous pouvez facilement identifier les problèmes récurrents; les couleurs indiquent leur gravité et, plus la couleur est foncée, plus le nombre d'événements de ce type survenus pendant une période donnée est élevé.
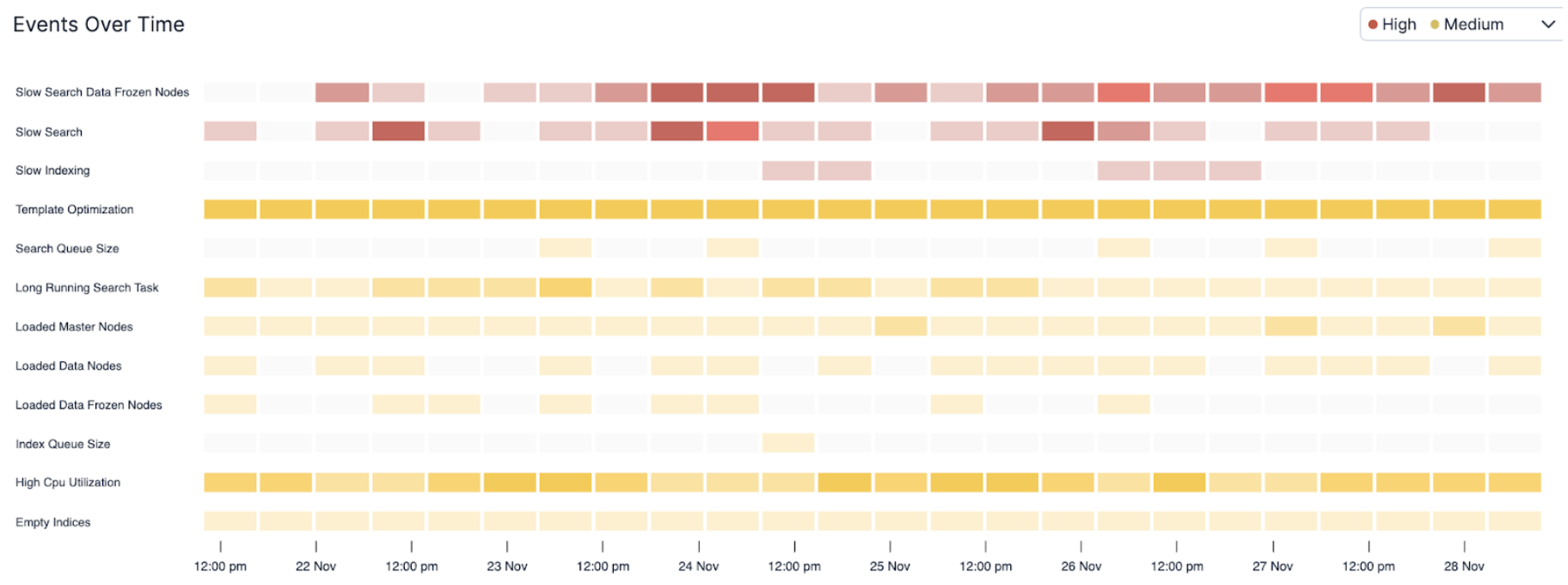
Face à un problème urgent à résoudre et lorsque le temps presse, un coup de pouce peut s'avérer très précieux pour identifier le point de départ de votre recherche et les éléments à considérer en priorité. Grâce à Elastic AI, nous avons pu relier les événements en cascade illustrés ci-dessus en une histoire cohérente, permettant d'identifier les causes profondes et les mesures correctives à prendre.
Nous avons opté pour une approche “chat-first” en déployant notre nouveau produit Elastic Agent Builder sur toutes les données AutoOps disponibles ci-dessus. Nous avons pu commencer à dialoguer avec nos données et voici comment cela s'est passé.
Tour de chauffe
Notre premier objectif était de résoudre les problèmes actuels qui nuisaient au cluster, nous avons donc entamé la conversation comme suit :

Après avoir rapidement examiné le mapping d'index pour déterminer comment interroger nos données, Elastic Agent Builder a créé quelques requêtes supplémentaires pour récupérer les problèmes de haute gravité détectés récemment et qui étaient encore actuellement ouverts, les a catégorisés par type et fréquence, a exploré leur contexte pour comprendre quelles instances ou index étaient impliqués, a récupéré d'autres informations liées à ces mêmes instances et index identifiés, et a enfin compulsé toutes les informations récupérées pour formuler sa réponse initiale affichée ci-dessous :

Bluffant ! Et il ne lui a fallu que 79 secondes pour analyser plus de dix mille événements et les relier en un narratif cohérent et surtout compréhensible. Allons un peu plus dans les détails.
Problème n°1 : High Search Queue on Node instance-368
En examinant le premier problème et l'index concerné, nous n'avons même pas eu besoin de consulter les slow logs, car nous savions que cela était lié aux alerting rules de Kibana. Nous pouvions facilement constater que Kibana avait également du mal à les exécuter, mais il y avait trop de règles pour rapidement identifier celles qui posaient problème. Par conséquent, puisque la recommandation était d'examiner les requêtes lentes et comme AutoOps les capture déjà, nous avons décidé de simplement déterminer laquelle pourrait être à l'origine de ce problème :

En quelques secondes, la requête DSL suivante est apparue et nous avons pu facilement repérer l'ID de la règle d'alerte dans l'en-tête HTTP X-Opaque-ID qu'AutoOps capture également (surligné en rouge ci-dessous).
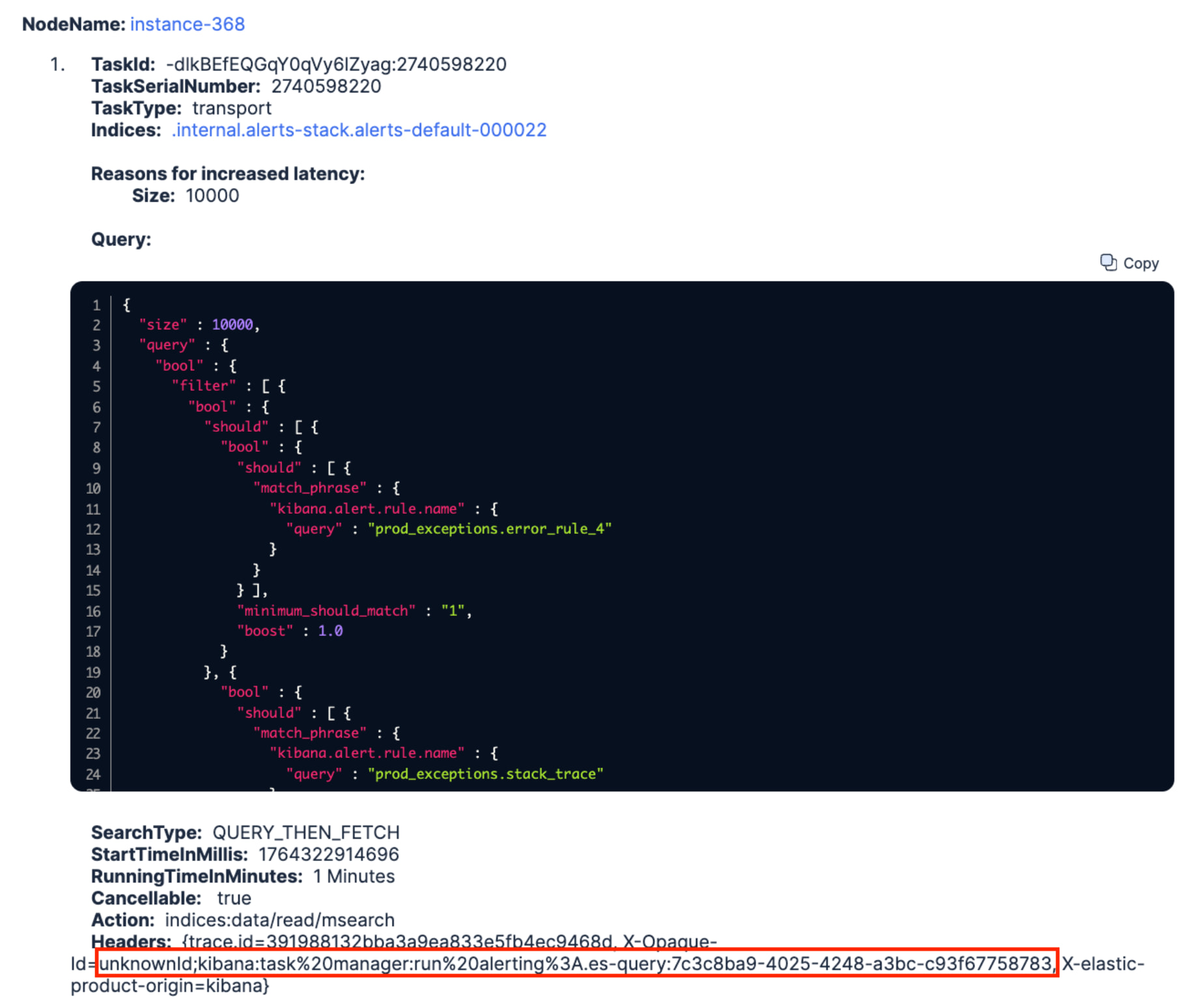
Nous sommes retournés dans Kibana et avons légèrement amélioré la requête (inutile de récupérer 10 000 résultats). Nous avons également revu sa fréquence d'exécution, qui était inutilement élevée, et nous avons finalement enregistré la règle. Quelques minutes plus tard, la file d'attente de recherche sur l'instance 368 était vide. Ça c’est fait ![]()
Problème n° 2 : Unbalanced Data Node Load
Très bien, et ensuite ? Le deuxième point était assez clair. Puisqu’il était recommandé d’examiner notre stratégie d’allocation des shards, un rapide coup d’œil à AutoOps Shards View nous a permis d’identifier facilement les trois index présentant une activité d'indexation élevée et de découvrir certains hot spots d'indexation sur les instances identifiées.
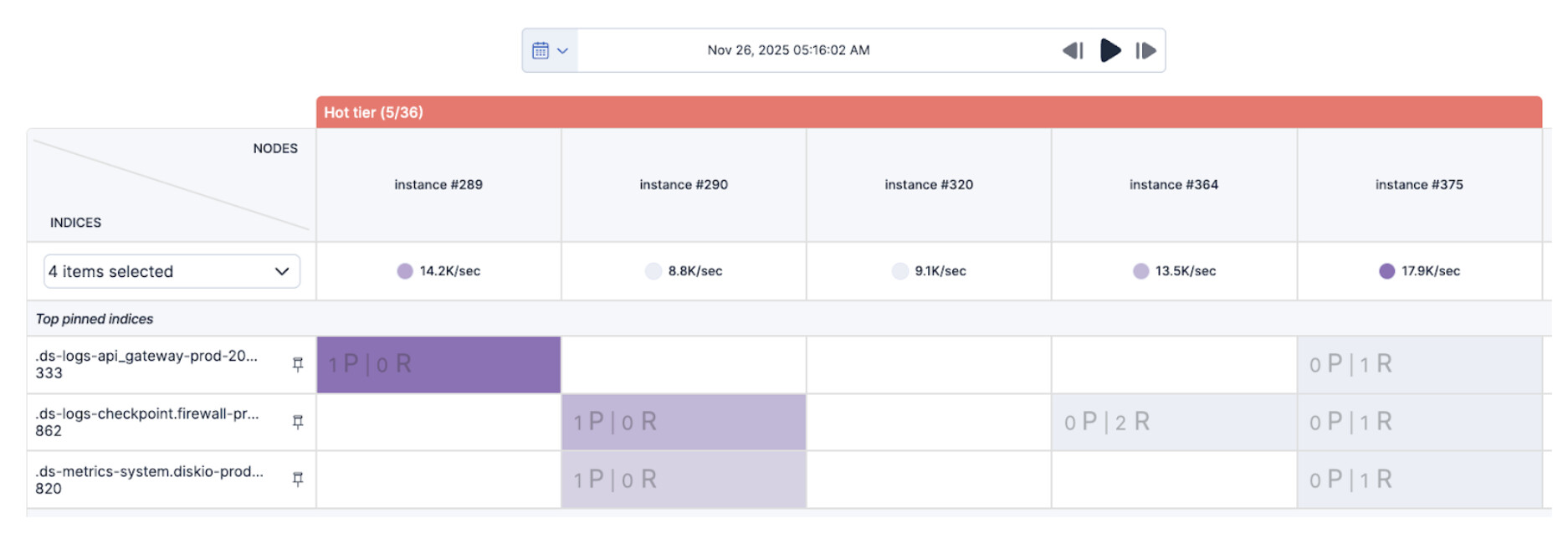
Comme ces index ne comportaient que trois shards primaires, tous alloués au même ensemble de nœuds, et que leur taille augmentait plus rapidement que prévu, nous avons décidé de doubler leur nombre, car il y avait suffisamment d’instances “hot” pour gérer les shards supplémentaires. Nous avons ensuite effectué une rotation des data streams respectifs et les hot spots ont disparu quelques minutes plus tard. Voilà, ça c’est fait également ![]()
Problème n° 3 : Unbalanced Data Frozen Node Load
Pour résoudre ce dernier problème, nous avons de nouveau fait appel à Elastic Agent Builder. Nous l'avons testé en utilisant ses propres recommandations et en lui demandant de rechercher s’il y avait des requêtes lentes en cours d’exécution sur les index identifiés. Il est clair qu'il y a des améliorations possibles, car il aurait dû appliquer automatiquement ses propres recommandations pour déterminer la provenance du trafic de recherche. Voyons voir ce qui s'est passé ensuite :

Quelques secondes plus tard, il a retourné une requête lente qui s'exécutait depuis 158 minutes (> 2 h 30) sur tous les indexes .partial-.ds-synthetics-http-defaut*. De même que pour le problème n°1, l'analyse de la requête a révélé qu'elle portait sur trois mois de données (dont deux avaient déjà atteint notre tier “frozen”) et qu'elle tentait d'agréger un nombre considérable de buckets.
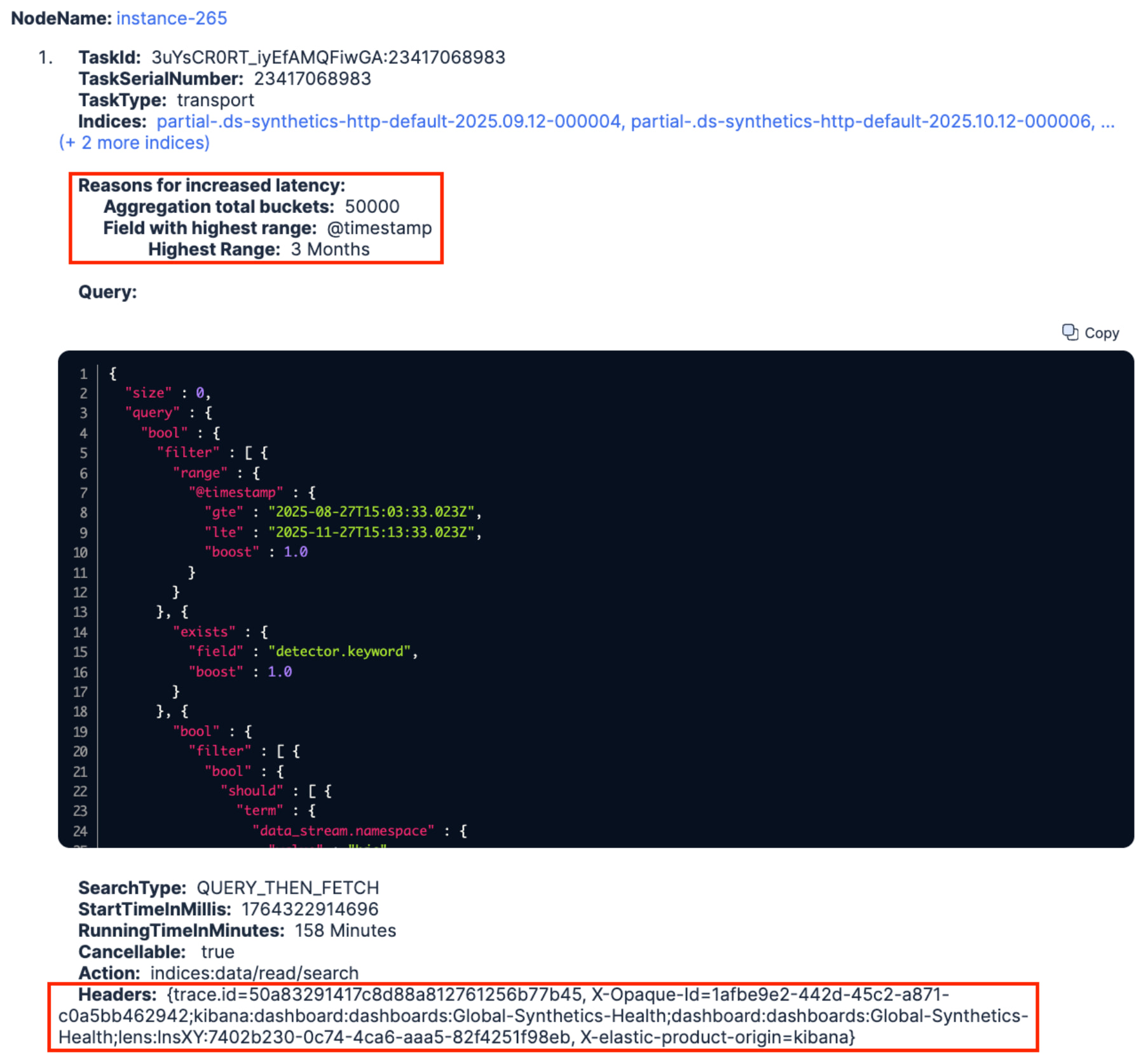
De plus, l'en-tête HTTP X-Opaque-ID a révélé l'identifiant d'un tableau de bord nommé Global-Synthetics-Health d’où cette requête provenait (surligné en rouge ci-dessus). En accédant à ce tableau de bord, nous avons constaté qu'il contenait de nombreuses visualisations de type Lens exécutées sur les mêmes vues de données. Ce n'est pas rare, mais la période de trois mois enregistrée en dur à l’intérieur du tableau de bord est plutôt handicapante, sachant qu'un seul mois de données était conservé dans dans notre “hot” tier. Nous avons donc réduit la période aux 10 derniers jours, stoppé les requêtes lentes et notre “frozen” tier a immédiatement pu respirer. Terminé ![]()
En conclusion
Bon, bon ! Regardons ce qui vient de se passer. Nous avions un problème urgent à résoudre et avons décidé d'utiliser AutoOps, car il conserve l'historique de tous les événements récents détectés sur notre cluster. Sachant qu'un problème survenant aujourd'hui peut souvent être causé par un ou plusieurs problèmes antérieurs, la capacité à corréler les événements et à comprendre comment ils s’enchaînent est essentielle pour identifier le problème originel et y remédier. En quelques minutes, grâce à Elastic Agent Builder et aux informations fournies par AutoOps, nous avons obtenu des indications rapides et pertinentes sur les points à améliorer et la manière de procéder. Notre cluster est de nouveau opérationnel, grâce à l'intelligence artificielle d'Elastic et aux informations fournies par AutoOps !
Certes, ce n'est pas encore parfait et il y a beaucoup de points à améliorer, mais nous avons pu démontrer que l'utilisation d’une IA conversationnelle pour corréler toutes ces informations et en tirer des recommandations concrètes permet de faire de grands progrès pour résoudre les problèmes de vos clusters de manière très rapide. Nous allons concrétiser tout cela très prochainement en intégrant un agent conversationnel dans AutoOps, restez à l’écoute !