Hi.
I got this error when using JavaClient+Elasticsearch(both version of them are 5.0.0alpha2)
Today morning I upgraded clinet/Server from alpha1 to alpha2.
This did not happen in 5.0.0 alpha1 I think.
client code and error log
client = builder.build() //
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("10.99.220.112"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("10.99.205.171"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("10.99.213.10"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("10.113.187.68"), 9300));
SearchRequestBuilder srb = client.prepareSearch();
srb.setIndices(targetIndices);
srb.setTypes(request.getServiceId());
srb.setQuery(masterQuery);
srb.addAggregation(ab);
srb.setSize(0);
ListenableActionFuture<SearchResponse> execute = srb.execute(); <--- this line claims..
NoNodeAvailableException[None of the configured nodes were available: [{dev-elastic204.ncl}{LKNBLbPRRLC6S-jN-5XJKQ}{10.113.187.68}{10.113.187.68:9300}, {dev-elastic202.ncl}{zi7dPFrWS3OyW-jZB5O6Dg}{10.99.205.171}{10.99.205.171:9300}, {dev-elastic201.ncl}{Vf60NeajSmyH82ZteANo1Q}{10.99.220.112}{10.99.220.112:9300}, {dev-elastic203.ncl}{DD0V1VZ_RzqpkXpbbJwWwQ}{10.99.213.10}{10.99.213.10:9300}]]; nested: NodeDisconnectedException[[dev-elastic204.ncl][10.113.187.68:9300][indices:data/read/search] disconnected];
at org.elasticsearch.client.transport.TransportClientNodesService$RetryListener.onFailure(TransportClientNodesService.java:253)
....
at java.lang.Thread.run(Thread.java:745)
Caused by: NodeDisconnectedException[[dev-elastic204.ncl][10.113.187.68:9300][indices:data/read/search] disconnected]
server log
[2016-05-04 09:16:44,910][WARN ][threadpool ] [dev-elastic201.ncl] failed to run org.elasticsearch.watcher.ResourceWatcherService$ResourceMonitor@3e8cb932
java.security.AccessControlException: access denied ("java.io.FilePermission" "/home1/apps/elasticsearch/config/scripts" "read")
at java.security.AccessControlContext.checkPermission(AccessControlContext.java:472)
at java.security.AccessController.checkPermission(AccessController.java:884)
....
[2016-05-04 14:16:05,316][WARN ][transport.netty ] [dev-elastic201.ncl] exception caught on transport layer [[id: 0x6fa39b9a, /10.75.17.101:49956 => /10.99.220.112:9300]], closing connection
java.lang.IllegalStateException: Message not fully read (request) for requestId [0], action [cluster:monitor/nodes/liveness], readerIndex [52] vs expected [52]; resetting
at org.elasticsearch.transport.netty.MessageChannelHandler.messageReceived(MessageChannelHandler.java:144)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
....
at java.lang.Thread.run(Thread.java:745)
[2016-05-04 14:16:05,350][WARN ][transport.netty ] [dev-elastic201.ncl] exception caught on transport layer [[id: 0x5ef09158, /10.75.17.101:49971 => /10.99.220.112:9300]], closing connection
java.lang.IllegalStateException: Message not fully read (request) for requestId [1], action [cluster:monitor/nodes/liveness], readerIndex [52] vs expected [52]; resetting
at org.elasticsearch.transport.netty.MessageChannelHandler.messageReceived(MessageChannelHandler.java:144)
at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70)
/_cluster/state
Every nodes seems ok.

/_cluster/health
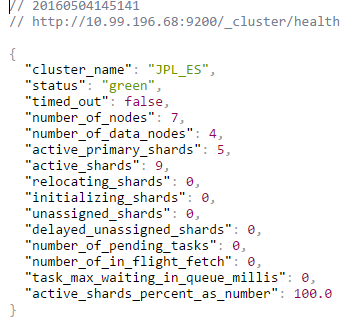
What should I check?
REST _search returns the result well.

