I have 12 servers running logstash. They are sending data to 4 ES nodes. Each ES node has 24 cores, 36TB of spinning disks and 128GB RAM. The 12 logstash machines are sending round robin to the 4 ES nodes. All going into one index, with no replication and 16 shards (4 shards per ES node). Everything has been upgraded to 6.0.
Performance is poor and nothing I can do seems to change anything.
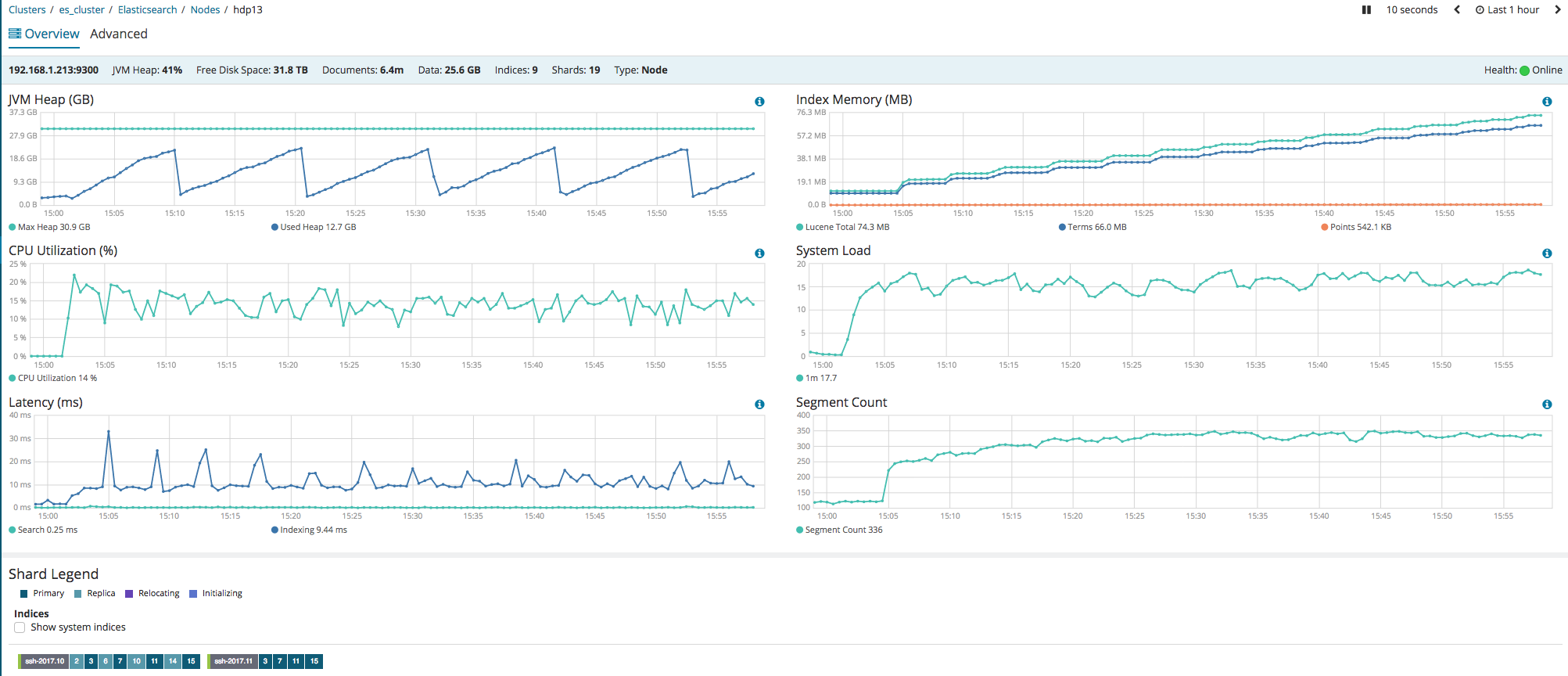
For example here is a snapshot of the thread pool:
Queue is set to 600 but there are lots of rejects so the ES nodes can not keep up.
Attached are some screenshots of an ES node. Any ideas on how I might explore increasing the performance. I only care about bulk ingesting. I don't care about search performance at this stage.
On the last graph, it's clear that the number of index segments expolded once you started ingestion. As you on spinning media, segments merging can impact performance badly, so have a look how to tune this.
Also, given that you don't care about search during the indexing, consider changing index.refresh_interval, so you have fewer segments created in the first place, see doc.
Thanks for the reply.
Unfortunately that has all been removed in 6.0
Store throttling has been removed. As a consequence, the indices.store.throttle.type and indices.store.throttle.max_bytes_per_sec cluster settings and the index.store.throttle.type and index.store.throttle.max_bytes_per_sec index settings are not recognized anymore.
How many disks do you have per node? Are these set up as multiple data paths or using some RAID configuration? With only 4 active shards per node, are you utilizing all disks when indexing?
What does disk I/O and iowait look like?
What is the average size of your documents? Are you using the default Logstash settings around batch and bulk size?
You seem to have a fair bit of await across quite a few of the disks. Did you change the index.merge.scheduler.max_thread_count parameter to 1? Did it make any difference?
How many documents are you sending per bulk request? It might be worth to try increasing the pipeline.batch.size to e.g. 1000, in order to get larger bulk requests sent to Elasticsearch.
Increasing the shard count might actually make your bulk rejection issues worse, as described in this blog post. You have a lot of Logstash instances sending data to the cluster in parallel, so it may make a lot of sense to increase the pipeline batch size to get fewer, but larger, bulk requests.
How come you have so many Logstash instances for so few Elasticsearch nodes? Generally just a few Logstash instances can saturate a cluster that size unless they are doing very heavy or inefficient processing of events.
I am sending the data from a hadoop cluster which has 12 nodes. I use the reduce part of a MR job to send the data to the 4 ES nodes. If I set the number of reducers down to 4 then it would only ever have 4 nodes sending to the 4 ES nodes. I will experiment with this, starting with reducers=1!
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.