Hi All,
I can't increase the indexing more than 10000 event/second no matter what I do. I am getting around 13000 events per second from kafka in a single logstash instance. I am running 3 Logstash in different machines reading data from same kafka topic.
I have setup a ELK cluster with 3 Logstash reading data from Kafka and sending them to my elastic cluster.
My cluster contains 3 Logstash, 3 Elastic Master Node, 3 Elastic Client node and 50 Elastic Data Node.
All Citrix VM having same configuration of :
Red Hat Linux-7
Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz 6 Cores
32 GB RAM
2 TB spinning media
Logstash Config file :
output {
elasticsearch {
hosts => ["dataNode1:9200","dataNode2:9200","dataNode3:9200" upto "**dataNode50**:9200"]
index => "logstash-applogs-%{+YYYY.MM.dd}-1"
workers => 6
user => "uname"
password => "pwd"
}
}
Elasticsearch Data Node's elastcisearch.yml File:
cluster.name: my-cluster-name
node.name: node46-data-46
node.master: false
node.data: true
bootstrap.memory_lock: true
path.data: /apps/dataES1/data
path.logs: /apps/dataES1/logs
discovery.zen.ping.unicast.hosts: ["master1","master2","master3"]
network.host: hostname
http.port: 9200
The only change that I made in my **jvm.options** file is
-Xms15g
-Xmx15g
System config changes that I did are as follows:
vm.max_map_count=262144
and in /etc/security/limits.conf I added :
elastic soft nofile 65536
elastic hard nofile 65536
elastic soft memlock unlimited
elastic hard memlock unlimited
elastic soft nproc 65536
elastic hard nproc unlimited
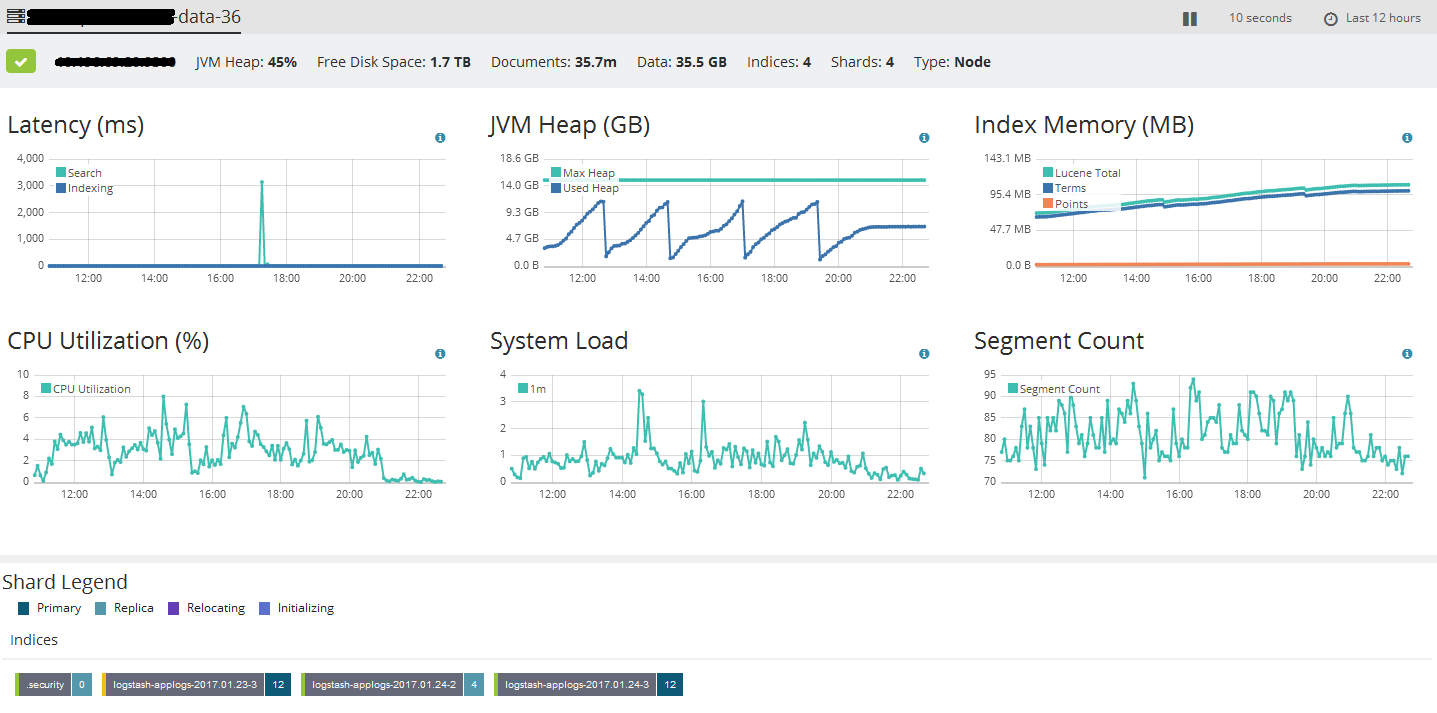
Indexing Rate


One of the active data node:
$ sudo iotop -o
Total DISK READ : 0.00 B/s | Total DISK WRITE : 243.29 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 357.09 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
5199 be/3 root 0.00 B/s 3.92 K/s 0.00 % 1.05 % [jbd2/xvdb1-8]
14079 be/4 elkadmin 0.00 B/s 51.01 K/s 0.00 % 0.53 % java -Xms15g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSIni~h-5.0.2/lib/* org.elasticsearch.bootstrap.Elasticsearch
13936 be/4 elkadmin 0.00 B/s 51.01 K/s 0.00 % 0.39 % java -Xms15g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSIni~h-5.0.2/lib/* org.elasticsearch.bootstrap.Elasticsearch
13857 be/4 elkadmin 0.00 B/s 58.86 K/s 0.00 % 0.34 % java -Xms15g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSIni~h-5.0.2/lib/* org.elasticsearch.bootstrap.Elasticsearch
13960 be/4 elkadmin 0.00 B/s 35.32 K/s 0.00 % 0.33 % java -Xms15g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSIni~h-5.0.2/lib/* org.elasticsearch.bootstrap.Elasticsearch
13964 be/4 elkadmin 0.00 B/s 31.39 K/s 0.00 % 0.27 % java -Xms15g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSIni~h-5.0.2/lib/* org.elasticsearch.bootstrap.Elasticsearch
14078 be/4 elkadmin 0.00 B/s 11.77 K/s 0.00 % 0.00 % java -Xms15g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSIni~h-5.0.2/lib/* org.elasticsearch.bootstrap.Elasticsearch
Index Details :
index shard prirep state docs store
2017.01.24-3 3 p STARTED 5382409 5.4gb
2017.01.24-3 3 r STARTED 5382409 10.1gb
2017.01.24-3 8 r STARTED 5383699 10.1gb
2017.01.24-3 8 p STARTED 5383699 10.2gb
2017.01.24-3 15 r STARTED 5379509 10.1gb
2017.01.24-3 15 p STARTED 5379509 5.5gb
2017.01.24-3 5 p STARTED 5386820 10.3gb
2017.01.24-3 5 r STARTED 5386820 5.4gb
2017.01.24-3 13 r STARTED 5386149 6.1gb
2017.01.24-3 13 p STARTED 5386149 5.4gb
2017.01.24-3 11 r STARTED 5383620 10.2gb
2017.01.24-3 11 p STARTED 5383620 10.2gb
2017.01.24-3 19 r STARTED 5383770 5.7gb
2017.01.24-3 19 p STARTED 5383770 5.5gb
2017.01.24-3 6 r STARTED 5389052 10.2gb
2017.01.24-3 6 p STARTED 5389052 5.8gb
2017.01.24-3 9 p STARTED 5382316 10gb
2017.01.24-3 9 r STARTED 5382316 5.6gb
2017.01.24-3 1 p STARTED 5384850 10.3gb
2017.01.24-3 1 r STARTED 5384850 10gb
2017.01.24-3 2 p STARTED 5384110 10.3gb
2017.01.24-3 2 r STARTED 5384110 5.4gb
2017.01.24-3 14 r STARTED 5382046 5.4gb
2017.01.24-3 14 p STARTED 5382046 5.8gb
2017.01.24-3 10 p STARTED 5383007 10.3gb
2017.01.24-3 10 r STARTED 5383007 7.7gb
2017.01.24-3 4 r STARTED 5385397 5.4gb
2017.01.24-3 4 p STARTED 5385397 5.4gb
2017.01.24-3 7 p STARTED 5382244 5.5gb
2017.01.24-3 7 r STARTED 5382244 10.2gb
2017.01.24-3 16 r STARTED 5381232 10.2gb
2017.01.24-3 16 p STARTED 5381232 5.5gb
2017.01.24-3 18 r STARTED 5379792 6.3gb
2017.01.24-3 18 p STARTED 5379792 5.4gb
2017.01.24-3 12 p STARTED 5380705 5.4gb
2017.01.24-3 12 r STARTED 5380705 6.7gb
2017.01.24-3 17 r STARTED 5382108 5.5gb
2017.01.24-3 17 p STARTED 5382108 5.8gb
2017.01.24-3 0 r STARTED 5385285 10.2gb
2017.01.24-3 0 p STARTED 5385285 10.1gb
I tested the incoming data in logstash by dumping data into a file. I got a file of 290 MB with 377822 lines in 30 seconds. So there is no issue from Kafka as at a given time I am receiving 35000 events per second in my 3 Logstash servers but my Elasticsearch is able to index maximum of 10000 events per second.
Can someone please help me with this issue?