Topbeat 1.3
elasticsearch 5.1
kibana 5.1
Red Hat Enterprise Linux Server
Version : 7.2 (Maipo)
Installing Topbeat
curl -L -O https://download.elastic.co/beats/topbeat/topbeat-1.3.1-x86_64.rpm
sudo rpm -vi topbeat-1.3.1-x86_64.rpm
Loading the Index Template In Elasticsearch
curl -XPUT 'http://IP:9200/_template/topbeat' -d@/etc/topbeat/topbeat.template.json
I have not started Topbeat on linux
I have configured topbeat 1.2 topbeat.yml to point to linux server
topbeat 1.2 is installed on windows 7 machine.
Now the issue begins================
When I configure the index pattern topbeat-* on kibana 5.1 there are some fields which are both non-searchable and non-aggregatable.

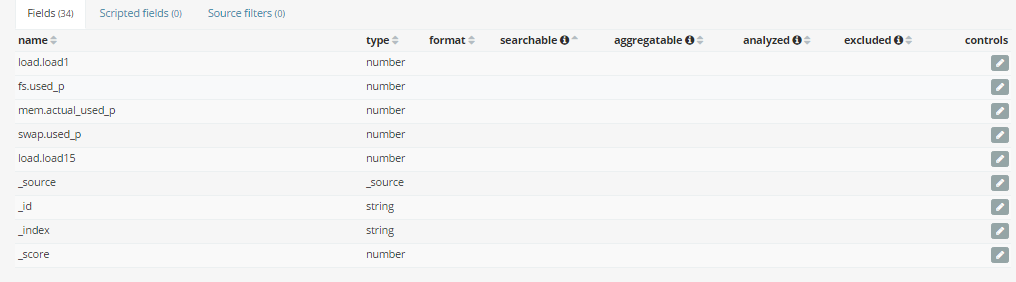
As you can see these fields are both non-searchable and non-aggregatable.
I am not able to create charts on these fields as they do not appear

How to make them searchable and aggregatable ??
