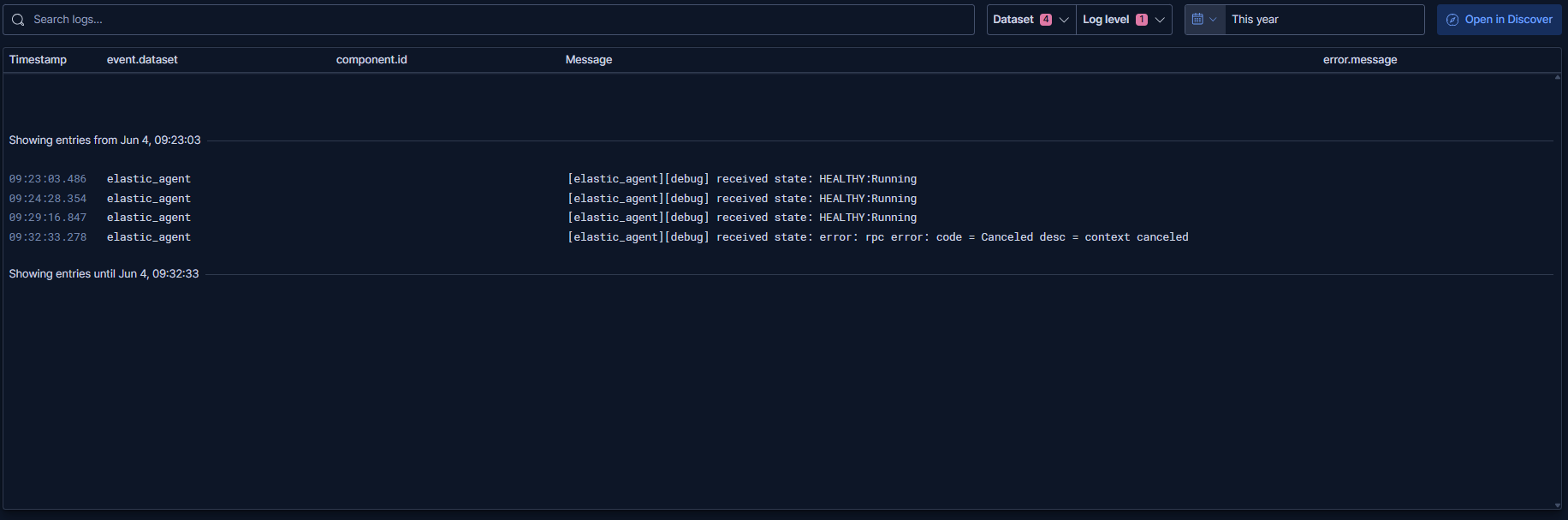
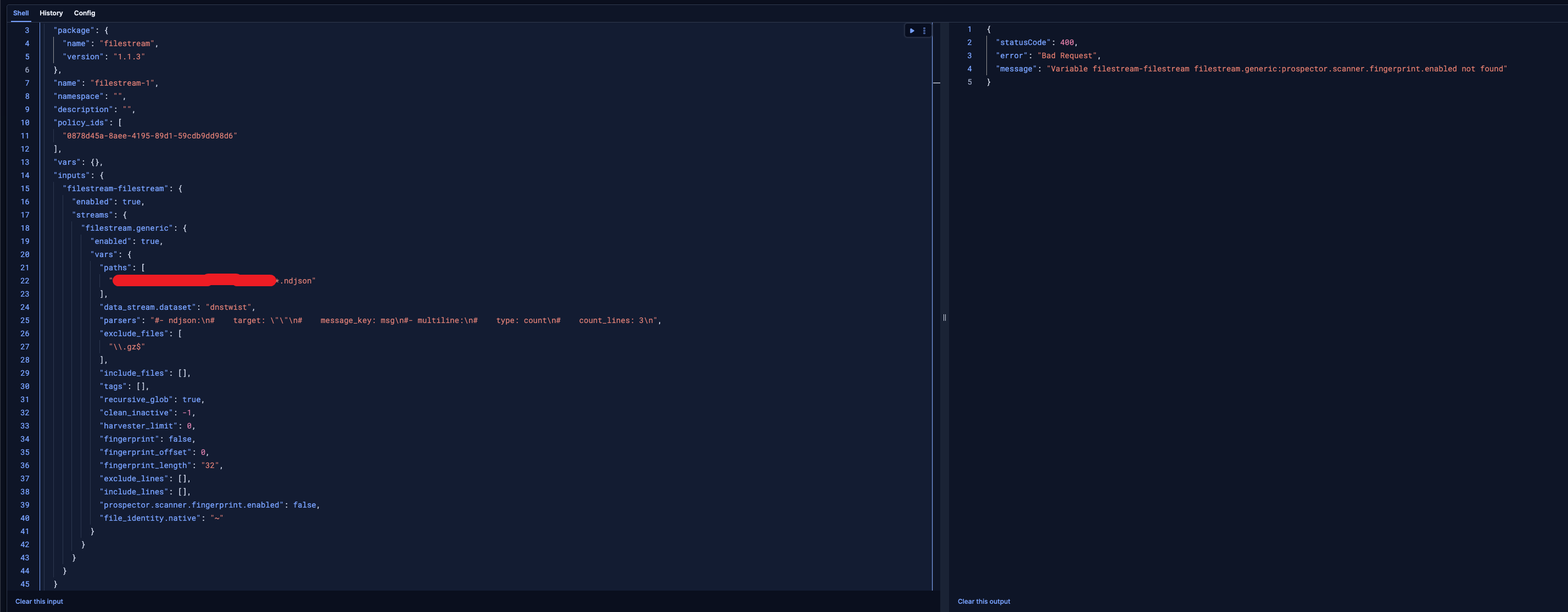
gistfile1.txt
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.195Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/cmd.runElasticAgent","file.name":"cmd/run.go","file.line":193},"message":"Elastic Agent started","log":{"source":"elastic-agent"},"process.pid":1905,"agent.version":"9.0.2","agent.unprivileged":false,"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.425Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/application/upgrade.InvokeWatcher","file.name":"upgrade/rollback.go","file.line":154},"message":"Starting upgrade watcher","log":{"source":"elastic-agent"},"path":"/opt/Elastic/Agent/elastic-agent","args":["/opt/Elastic/Agent/elastic-agent","watch","--path.config","/opt/Elastic/Agent","--path.home","/opt/Elastic/Agent"],"env":[],"dir":"","ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.426Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/application/upgrade.InvokeWatcher","file.name":"upgrade/rollback.go","file.line":168},"message":"Upgrade Watcher invoked","log":{"source":"elastic-agent"},"agent.upgrade.watcher.process.pid":50167,"agent.process.pid":1905,"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.437Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/cmd.runElasticAgent","file.name":"cmd/run.go","file.line":282},"message":"APM instrumentation disabled","log":{"source":"elastic-agent"},"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.480Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/application.New","file.name":"application/application.go","file.line":73},"message":"Gathered system information","log":{"source":"elastic-agent"},"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.520Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/application.New","file.name":"application/application.go","file.line":79},"message":"Detected available inputs and outputs","log":{"source":"elastic-agent"},"inputs":["gcp-pubsub","mongodb/metrics","stan/metrics","packet","aws-cloudwatch","benchmark","cometd","http_endpoint","o365audit","synthetics/http","mysql/metrics","syslog","awsfargate/metrics","nginx/metrics","cloudfoundry/metrics","gcs","log","netflow","iis/metrics","kafka/metrics","panw/metrics","salesforce","linux/metrics","system/metrics","cloudfoundry","entity-analytics","unifiedlogs","kibana/metrics","syncgateway/metrics","audit/auditd","azure-eventhub","udp","filestream","synthetics/browser","oracle/metrics","memcached/metrics","zookeeper/metrics","audit/file_integrity","container","etw","kubernetes/metrics","redis/metrics","pf-host-agent","azure-blob-storage","kafka","lumberjack","streaming","synthetics/icmp","beat/metrics","mssql/metrics","apache/metrics","journald","openai/metrics","prometheus/metrics","cel","mqtt","redis","unix","docker/metrics","postgresql/metrics","uwsgi/metrics","aws/metrics","azure/metrics","containerd/metrics","activemq/metrics","gcp/metrics","haproxy/metrics","rabbitmq/metrics","statsd/metrics","endpoint","audit/system","aws-s3","tcp","windows/metrics","etcd/metrics","jolokia/metrics","nats/metrics","httpjson","winlog","elasticsearch/metrics","logstash/metrics","vsphere/metrics","synthetics/tcp","http/metrics","meraki/metrics","sql/metrics","traefik/metrics","osquery","docker"],"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.520Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/capabilities.LoadFile","file.name":"capabilities/capabilities.go","file.line":48},"message":"Capabilities file not found in /opt/Elastic/Agent/capabilities.yml","log":{"source":"elastic-agent"},"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.520Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/application.New","file.name":"application/application.go","file.line":85},"message":"Determined allowed capabilities","log":{"source":"elastic-agent"},"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:34.520Z","log.origin":{"function":"github.com/elastic/elastic-agent/internal/pkg/agent/application.New","file.name":"application/application.go","file.line":100},"message":"Loading baseline config from /opt/Elastic/Agent/elastic-agent.yml","log":{"source":"elastic-agent"},"ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2025-06-04T07:22:35.422Z","log.origin":{"function":"github.com/elastic/elastic-agent/pkg/component/runtime.NewManager","file.name":"runtime/manager.go","file.line":164},"message":"GRPC comms socket listening at localhost:6789","log":{"source":"elastic-agent"},"address":"localhost:6789","ecs.version":"1.6.0"}
This file has been truncated. show original