Hi,
i have deployed on prems elasticsearch,kibana and fleet (version 8) on a Centos 8 distro, now every time i boot up the server i see the fleet service is up and running, but, once i go to the fleet sheet i see the agent itself on the localhost as offline. I then restart the service (systemctl restart elastic-agent.service) and the agent is back online. I made sure the port 9200,9300,8220,8221 and 5601 are all reachable.
Over the log i see this entry
[elastic_agent][info] Spawned new component fleet-server-default: Starting: spawned pid '1870'
[elastic_agent][info] Spawned new unit fleet-server-default-fleet-server-fleet_server-ed70d400-056e-11ee-bb2d-959895802987: Starting: spawned pid '1870'
[elastic_agent][info] Spawned new unit fleet-server-default: Starting: spawned pid '1870'
[elastic_agent][info] Component state changed fleet-server-default (STARTING->HEALTHY): Healthy: communicating with pid '1870'
[elastic_agent][error] Unit state changed fleet-server-default (STARTING->FAILED): Error - dial tcp 192.168.1.67:9200: connect: connection refused
[elastic_agent][error] Unit state changed fleet-server-default-fleet-server-fleet_server-ed70d400-056e-11ee-bb2d-959895802987 (STARTING->FAILED): Error - dial tcp 192.168.1.67:9200: connect: connection refused
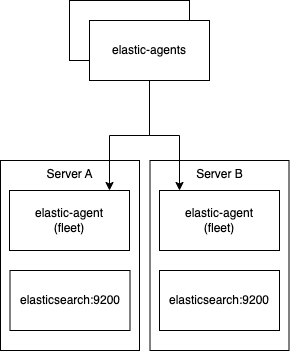
The Elastic Agents are managed with two Elastic-Fleet Servers. They connect to the one that is reacable. When i restart a Fleet Server they connect to the other. So far so good. Now if the Backend of the Elastic Agents with the fleet integration restarts (Elasticsearch), the Elastic Agents with the fleet role do not reconnect if the elasticsearch nodes are available again.
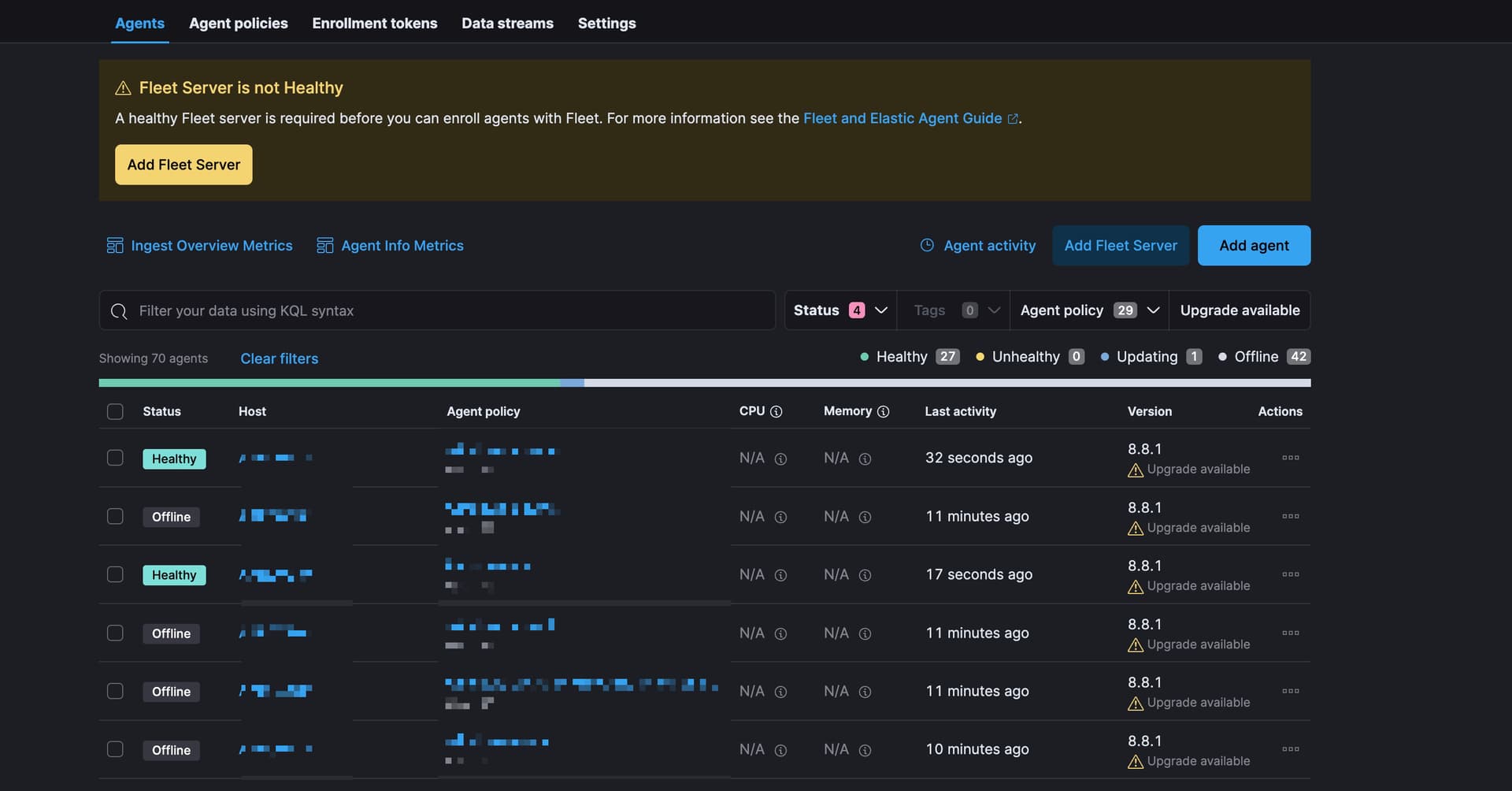
We need to manually restart the elastic agents with the fleet role (systemctl restart elastic-agent). Otherwise the agents are displayed as offline. In the following screenshot we have restarted manually one elastic agent with the fleet role and agents start to reconnect.
(ignore the version 8.8.1 its a bit older screenshot)
The fix might seem easy: Increase the timeout for the backend for the elastic agent with the fleet role or create a reconnect routine that tries to reconnect to the backend from time to time.
I'm asking myself the same. I don't know where to increase the timeout. It could be hardcoded in the routine of the fleet integration that is applied to the elastic-agent. This would mean this should be tracked as an official optimization or bug.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.