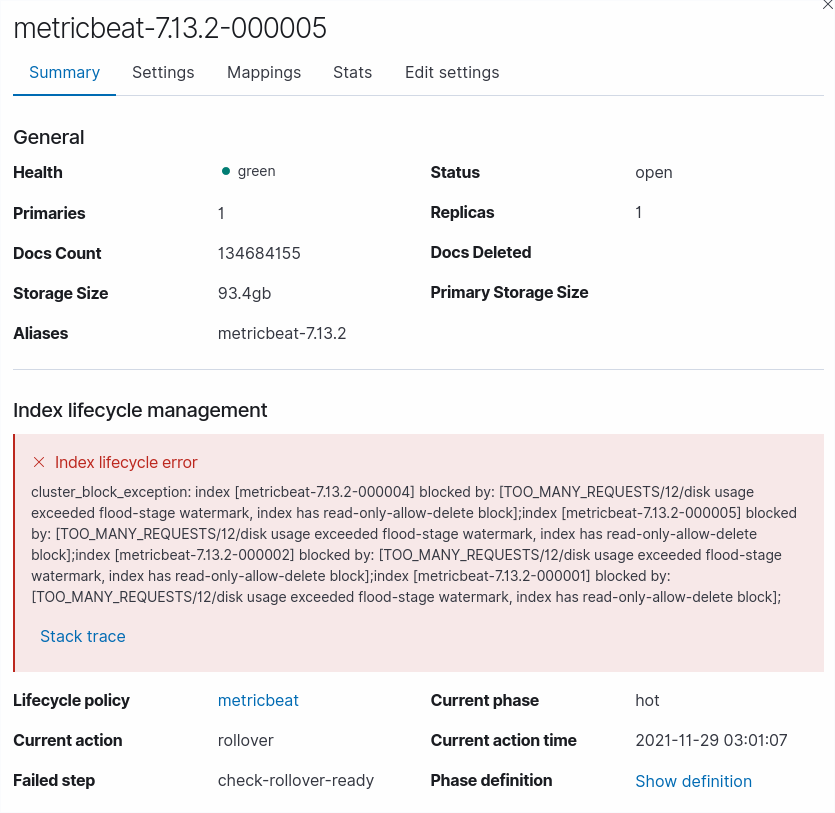
How do I troubleshoot this error-message? What does it mean?
What is the solution? We never got this error when we used the old daily indices. Now we get them after transitioning to ILM indices with default settings.
Index Lifecycle Error: cluster_block_exception: index [filebeat-7.13.2-000001] blocked by: [TOO_MANY_REQUESTS/12/disk usage exceeded flood-stage watermark, index has read-only-allow-delete block];
Is the problem simply that my storage is running full? I tried lowering the ILM time from 30 days to 7 days, and deleting the old indices and retrying lifecycle step. Hopefully that will work. Seems to work so far.
Probably yes, if your cluster went into flood stage, this mean that 95% of the available space was in use, when this happens elasticsearch force the indices to be read-only. [documentation]
You may also need to manually reset the read-only in your indices.
PUT /index-name/_settings
{
"index.blocks.read_only_allow_delete": null
}
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.