Good morning.
I am using elasticsearch 7.10 and kibana 7.10.
I'm having some issues with scattering column values in kibana.
I am new to elk.
The following contents were worked on kibana dev tool.
Contents of the issue: The data of the bikeId column is normally entered in elasticsearch, but the column value is split based on specific characters when inquiring in the kibana data table. (Appears to split 1 line into 2 lines based on a specific character)
- The index was created using the script below.
PUT bike_location2
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern_split",
"pattern": ""
}
}
}
}
}
- We have added a mapping to the index as shown below.
PUT /bike_location2/_mapping
{
"properties" : {
"partnerId" : {"type" : "text", "fielddata": true},
"bikeId" : {"type" : "text", "fielddata": true},
"gps_measure_time" : {"type" : "date", "format" : "yyyy-MM-dd HH:mm:ss"},
"gps_measure_time_micro_second" : {"type" : "integer"},
"gps_location" : {"type" : "geo_point"},
"battery" : {"type" : "float"},
"speed" : {"type" : "float"},
"mode" : {"type" : "float"}
}
}
- I put 3 data.
put bike_location2/_doc/1
{
"partnerId" : "test",
"bikeId" : "bike::test0001",
"gps_measure_time" : "2021-06-16 16:58:44",
"gps_measure_time_micro_second" : "832756",
"gps_location" : "37.497236, 127.034078",
"battery" : "89.5",
"speed" : "30",
"mode" : "5"
}
put bike_location2/_doc/2
{
"partnerId" : "test",
"bikeId" : "BIKE-test0001",
"gps_measure_time" : "2021-06-16 16:58:44",
"gps_measure_time_micro_second" : "832756",
"gps_location" : "37.497236, 127.034078",
"battery" : "89.5",
"speed" : "30",
"mode" : "5"
}
put bike_location2/_doc/3
{
"partnerId" : "test",
"bikeId" : "bike_test0001",
"gps_measure_time" : "2021-06-16 16:58:44",
"gps_measure_time_micro_second" : "832756",
"gps_location" : "37.497236, 127.034078",
"battery" : "89.5",
"speed" : "30",
"mode" : "5"
}
- When searching with get bike_location2/_search , the data is searched well.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "bike_location2",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"partnerId" : "test",
"bikeId" : "bike::test0001",
"gps_measure_time" : "2021-06-16 16:58:44",
"gps_measure_time_micro_second" : "832756",
"gps_location" : "37.497236, 127.034078",
"battery" : "89.5",
"speed" : "30",
"mode" : "5"
}
},
{
"_index" : "bike_location2",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"partnerId" : "test",
"bikeId" : "BIKE-test0001",
"gps_measure_time" : "2021-06-16 16:58:44",
"gps_measure_time_micro_second" : "832756",
"gps_location" : "37.497236, 127.034078",
"battery" : "89.5",
"speed" : "30",
"mode" : "5"
}
},
{
"_index" : "bike_location2",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"partnerId" : "test",
"bikeId" : "bike_test0001",
"gps_measure_time" : "2021-06-16 16:58:44",
"gps_measure_time_micro_second" : "832756",
"gps_location" : "37.497236, 127.034078",
"battery" : "89.5",
"speed" : "30",
"mode" : "5"
}
}
]
}
}
- Check if the data to be saved is partitioned
- All of them are not divided and are kept as they are.
(Can I test like this?)
POST bike_location2/_analyze
{
"analyzer": "my_analyzer",
"text": "BIKE-test0001"
}
POST bike_location2/_analyze
{
"analyzer": "my_analyzer",
"text": "bike_test0001"
}
POST bike_location2/_analyze
{
"analyzer": "my_analyzer",
"text": "bike::test0001"
}
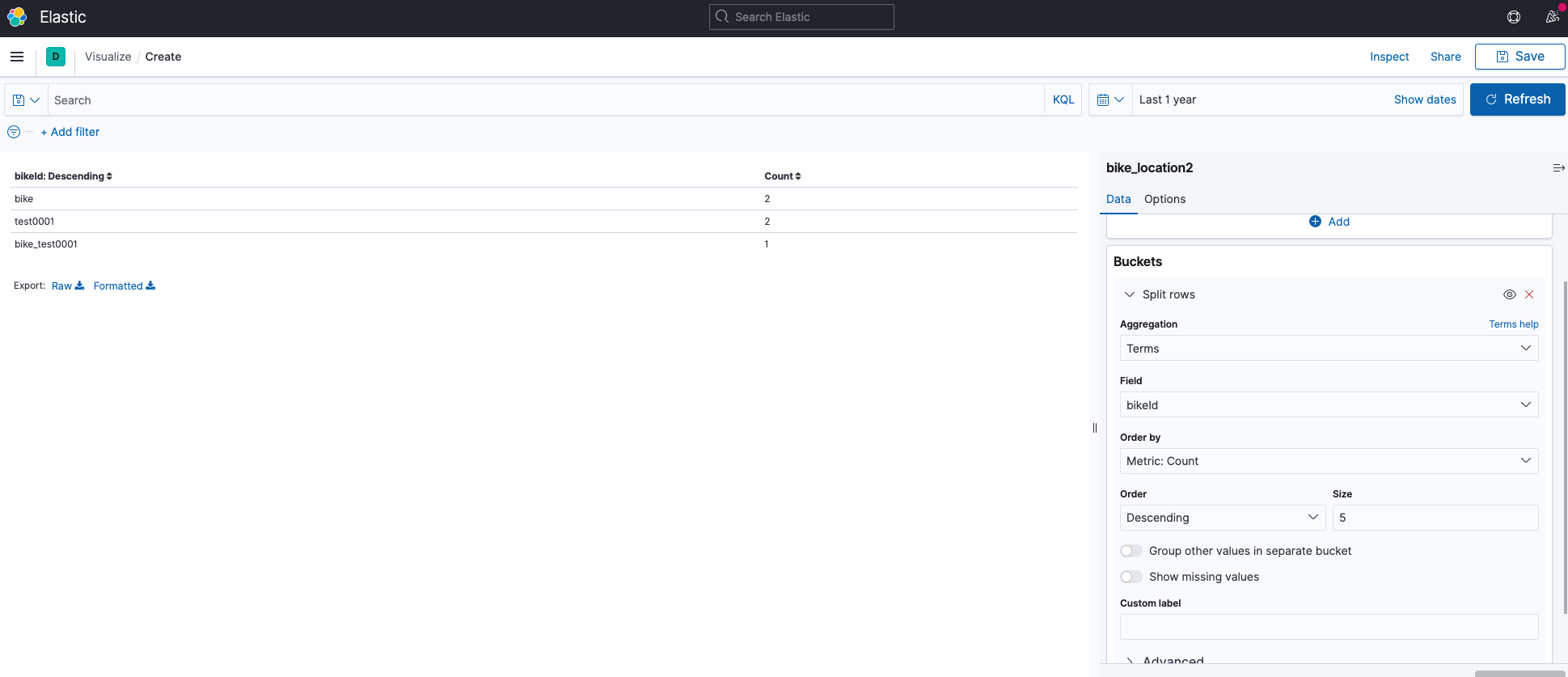
- If you search in kibana's data table, it is split like a capture at the bottom.
Seniors, please help I've been searching for days, but I can't find a way
I've been searching for days, but I can't find a way
As a reference (although the contents do not match the current configuration), it is the same even if you specify the following options.
PUT /my_index/_settings?pretty=true
{
"settings" : {
"analysis": {
"analyzer": {
"wordAnalyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"word_delimiter_for_phone","nGram_filter"
]
}
},
"filter": {
"word_delimiter_for_phone": {
"type": "word_delimiter",
"catenate_all": true,
"generate_number_parts ": false,
"split_on_case_change": false,
"generate_word_parts": false,
"split_on_numerics": false,
"preserve_original": true
},
"nGram_filter": {
"type": "nGram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter"
]
}
}
}
}
}