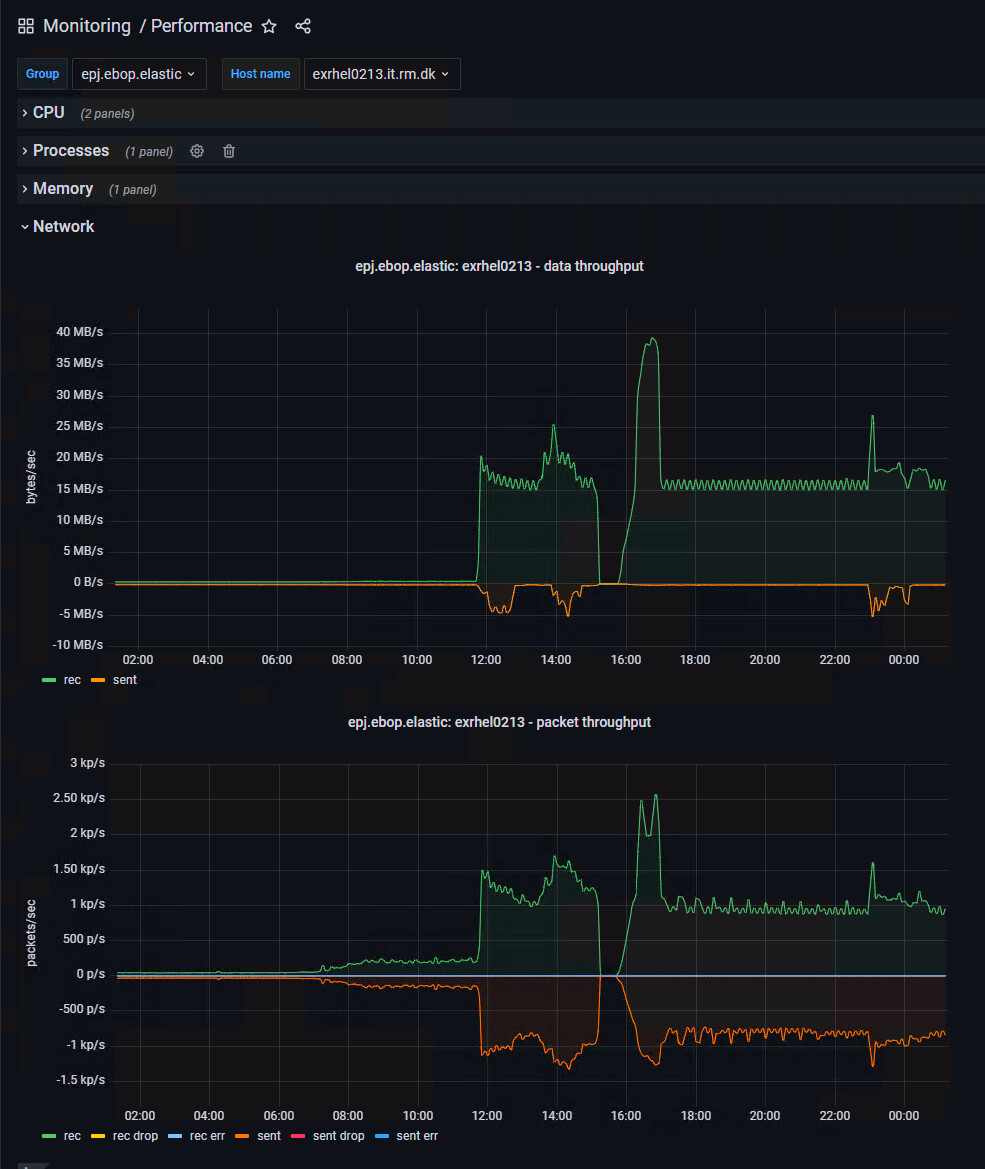
Know about 6.x EOL, v.7 is on the roadmap... 
{
"_nodes" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"cluster_name" : "RMElastic_prod",
"cluster_uuid" : "cB79gjmQRRG9Tw9RKbyZog",
"timestamp" : 1651133179324,
"status" : "green",
"indices" : {
"count" : 1809,
"shards" : {
"total" : 8490,
"primaries" : 4245,
"replication" : 1.0,
"index" : {
"shards" : {
"min" : 2,
"max" : 10,
"avg" : 4.693200663349917
},
"primaries" : {
"min" : 1,
"max" : 5,
"avg" : 2.3466003316749586
},
"replication" : {
"min" : 1.0,
"max" : 1.0,
"avg" : 1.0
}
}
},
"docs" : {
"count" : 1053840751,
"deleted" : 20366758
},
"store" : {
"size" : "282.6gb",
"size_in_bytes" : 303447749685
},
"fielddata" : {
"memory_size" : "106.2mb",
"memory_size_in_bytes" : 111398832,
"evictions" : 0
},
"query_cache" : {
"memory_size" : "41.4mb",
"memory_size_in_bytes" : 43444818,
"total_count" : 1186286,
"hit_count" : 1132270,
"miss_count" : 54016,
"cache_size" : 1996,
"cache_count" : 8684,
"evictions" : 6688
},
"completion" : {
"size" : "0b",
"size_in_bytes" : 0
},
"segments" : {
"count" : 63096,
"memory" : "1.1gb",
"memory_in_bytes" : 1220579609,
"terms_memory" : "910.2mb",
"terms_memory_in_bytes" : 954433089,
"stored_fields_memory" : "92.3mb",
"stored_fields_memory_in_bytes" : 96797568,
"term_vectors_memory" : "0b",
"term_vectors_memory_in_bytes" : 0,
"norms_memory" : "79.4mb",
"norms_memory_in_bytes" : 83277888,
"points_memory" : "32.2mb",
"points_memory_in_bytes" : 33850344,
"doc_values_memory" : "49.8mb",
"doc_values_memory_in_bytes" : 52220720,
"index_writer_memory" : "5.1mb",
"index_writer_memory_in_bytes" : 5414386,
"version_map_memory" : "1.1mb",
"version_map_memory_in_bytes" : 1250847,
"fixed_bit_set" : "258.8mb",
"fixed_bit_set_memory_in_bytes" : 271377488,
"max_unsafe_auto_id_timestamp" : 1651104004845,
"file_sizes" : { }
}
},
"nodes" : {
"count" : {
"total" : 5,
"data" : 4,
"coordinating_only" : 0,
"master" : 4,
"ingest" : 5
},
"versions" : [
"6.8.23"
],
"os" : {
"available_processors" : 18,
"allocated_processors" : 18,
"names" : [
{
"name" : "Linux",
"count" : 5
}
],
"pretty_names" : [
{
"pretty_name" : "Red Hat Enterprise Linux",
"count" : 5
}
],
"mem" : {
"total" : "254.7gb",
"total_in_bytes" : 273525952512,
"free" : "2.5gb",
"free_in_bytes" : 2708037632,
"used" : "252.2gb",
"used_in_bytes" : 270817914880,
"free_percent" : 1,
"used_percent" : 99
}
},
"process" : {
"cpu" : {
"percent" : 48
},
"open_file_descriptors" : {
"min" : 322,
"max" : 17637,
"avg" : 12823
}
},
"jvm" : {
"max_uptime" : "1.9d",
"max_uptime_in_millis" : 165952585,
"versions" : [
{
"version" : "1.8.0_322",
"vm_name" : "OpenJDK 64-Bit Server VM",
"vm_version" : "25.322-b06",
"vm_vendor" : "Red Hat, Inc.",
"count" : 5
}
],
"mem" : {
"heap_used" : "52.1gb",
"heap_used_in_bytes" : 55963970208,
"heap_max" : "105.8gb",
"heap_max_in_bytes" : 113659740160
},
"threads" : 568
},
"fs" : {
"total" : "807.9gb",
"total_in_bytes" : 867486879744,
"free" : "490.9gb",
"free_in_bytes" : 527122898944,
"available" : "490.9gb",
"available_in_bytes" : 527122898944
},
"plugins" : [ ],
"network_types" : {
"transport_types" : {
"security4" : 5
},
"http_types" : {
"security4" : 5
}
}
}
}