You can just copy the existing filebeat template and start from there it is pretty complete... or just use it as is... and change a few items like the index pattern matching ... and the write alias / ILM if you want to use them.
Also this is the first time you mentioned logstash, which is fine but can add complications... not done correct it can affect the index name / results etc... (usually I suggest getting filebeat -> elasticsearch first before adding logstash)
Not sure what you mean
That is correct, if you were on a newer version you could use a runtime field to "emit" a new field with the type you like.
You can also reindex the data if you like into a new index with the proper mappings.
It looks like the mapping was not applied... did you have the correct index pattern matching?
"index_patterns": ["foo*", "bar*"],
I don't know what that means... pre-determine how... based on what?... the host it is being collected from or from some data inside the actual log message...
Soooo here is my suggestion and it is just that...
It looks like you are 7.10... so this is 7.x suggestions (will change some in 8.x). Use the module AND get what you want too!
-
prefix your indices with filebeat- and the filebeat index template will apply for free so you don't need to worry about all that template and mapping stuff
 You will get it all for free... the pipelines, data types will be applied and everything.... funny the default dashboards should work too! then you can just add a control for customer-a vs customer-b
You will get it all for free... the pipelines, data types will be applied and everything.... funny the default dashboards should work too! then you can just add a control for customer-a vs customer-b -
You are right... with modules it is very hard and very easy at the same time... we will set these in the ngnix.yml. Modules set a lot of setting that overide the out put settings see here. So you can set any of those normal input setting with the prefix
input.see here and here You can add any filestream input setting...
That input.index setting will be carried through to the output.. now you can name it what every you like... ohh and where this is not set it will use the normal output so you don't need that conditional stuff in the output.
You could add your customer name in the index too... and create and matching index patter to just see them.
This sample I just added a tag
- module: nginx
# Access logs
access:
enabled: true
input.index: "filebeat-%{[agent.version]}-nginx-access-%{+yyyy.MM.dd}"
# Add customer tag if you like
input.tags: ["customer-a"]
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/Users/sbrown/workspace/sample-data/nginx/nginx-test.log"]
Walluhh!!! Now this is daily indexes not ILM based etc.. etc. .but should get you started...
GET _cat/indices/*
green open .kibana_task_manager_7.17.3_001 IohOxEOERYqR3ItEkebzCQ 1 0 17 1212 179.5kb 179.5kb
yellow open filebeat-7.17.3-nginx-access-2022.08.01 mFRSgBlHTfCap7a63LntYQ 1 1 9 0 43.6kb 43.6kb
Now you can set up an index pattern like this and everything should work
You can add the customer name in all this too if you want...
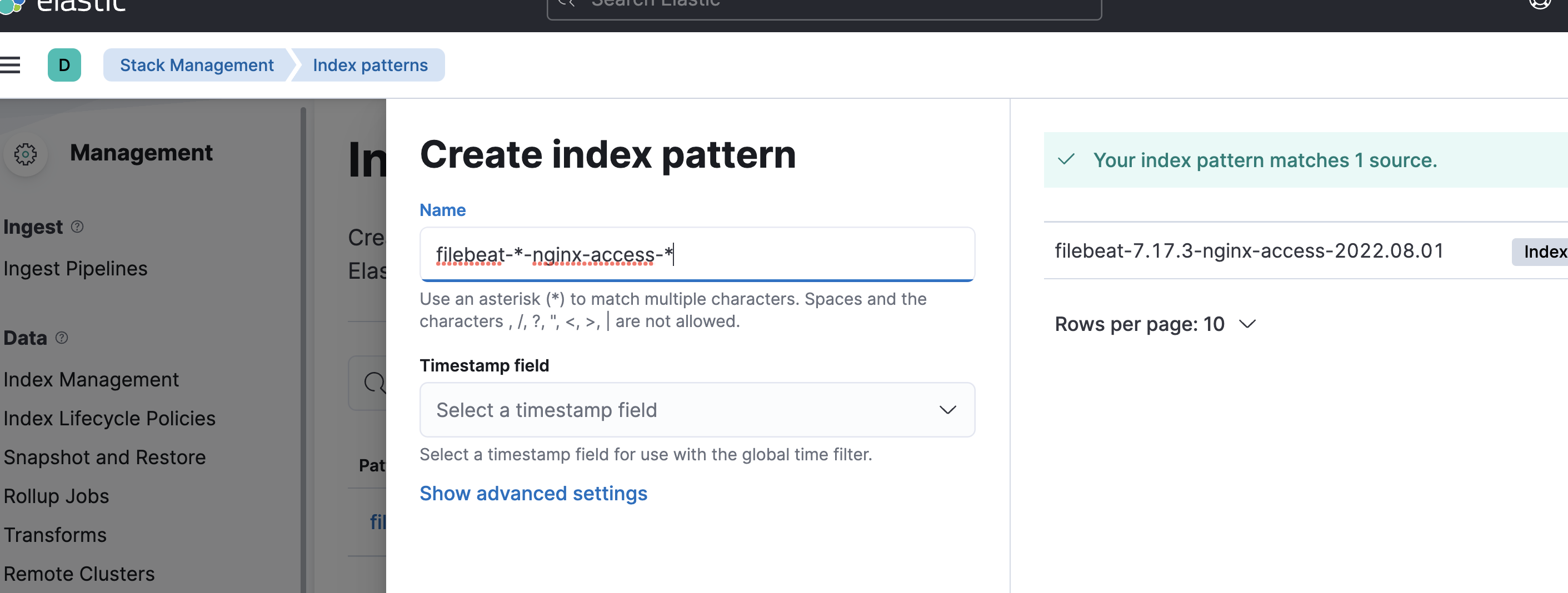
And the data types are correct!!!
