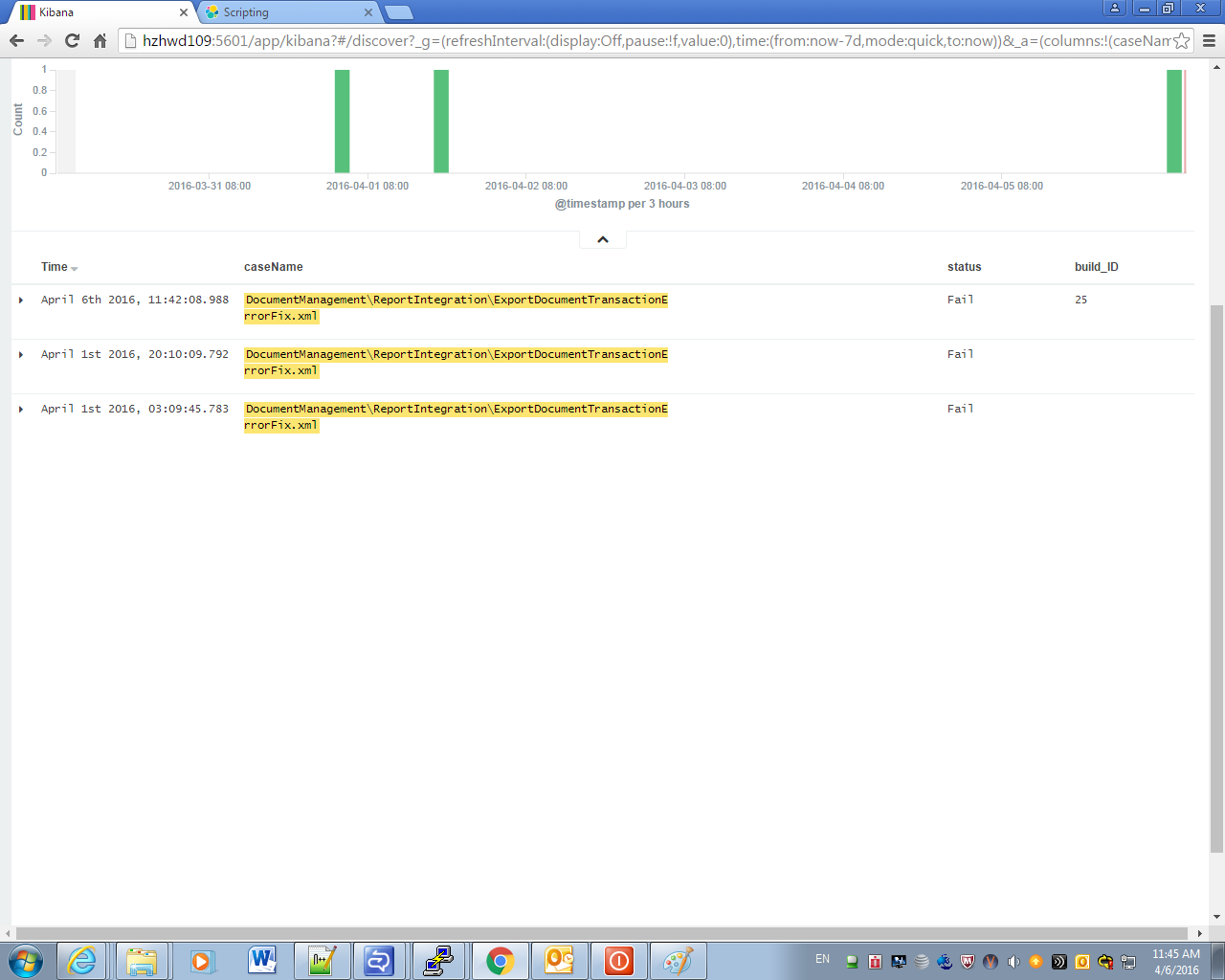
I have two questions about kibana 4 based on the following scenario : we index our acceptance test into elasticsearch ,including: caseName, status(fail or success), and buildID ( means the times run the case)
Question one: we want to get the latest failed cases during our selected period. Beause I often find that the past status of some case, the latest status of which is succeed , still can be find in kibana ,if I select a long period. I try to discover the dataset like this:
{
"query": {
"filtered": {
"query": { "match_all": { }},
"filter": { "term": { "tags": "Error Detail Message Report" }}
}
}
,
"aggs":{
"my_test":{
"terms":{"field":"caseName"},
"aggs" : {
"my_test01": {
"top_hits": {
"sort": [
{
"buildID": {
"order": "desc"
}
}
],
"size" : 1
}
}
}
}
}
}
But it seems that kibana not support aggs during discover
, so could you tell me how to implement the function?
Question two: I want to make statistics the fequence of case , if the latest status of the case is fail by data table in kibana 4. In order to implements the function , I want to do the following things:
First, group by caseName.
Second, select the caseName group , which the lastest status is fail.
Third, count the fail times during the selected caseName. I do not know how to implement the second step by data table in kibana 4
I don't have a set of test data like your scenario handy, but just thinking through it this is what I would suggest;
If you select to Visualize with a Data Table, you might want to aggregate on the caseName with the Metric being Max timestamp or Max buildID. I'm thinking that would give you only the latest pass or fail result (if that's what you want to see).
And then add a Sub-bucket aggregation on the Status so you get the actual pass/fail results of the last run of each test. I could have this backwards, but you can easily switch the order of those aggregations to see.
Let's see if we can get that first visualization working and then come back to the others. You might possibly have to use a custom script to get the results you want.
I want to make statistics of the frequency of failed for the same case with data table , not get the latest status with data table !
You know, we may run a same case many times during a period . we want to do the statistics: if the latest status of the same case is failed , we need to get the total times of failed for the case during the period. But if the latest status of the case is pass , we need to filter the case .
As you mean , I need to group by caseName first , second I need to find the group which meet the above condition, and finally I count the times of fail with metric and filter within a case group .
But I do not know how to implement the second step , in other words , add the condition for finds those case group with datatable.
The follow attachment just finish the first and the third step :
Another question about the latest status, I want to save in dataset in discover. Because I will find many entry for a same case in discover stage if I select a long period . That will cause our mistake and extra effort to fix the case , so I want to get the lastest entry for every case and filter in the failed case to fix.
But in discover stage , kibana seems that only support query , not aggs.
Yes , I am research the script . But currently , I am not sure how to implement my function by script . If you have some suggestion , I will very grateful to you!!
On your My_Test_VIZ issue, you say you have the first and third step but need the second. And the second step is to find ONLY the tests where the latest result is failed. I'm not sure that's possible. Or maybe only with the custom JSON scripting. At the bottom of the Split Rows aggregation, click the Advanced link and you should see the "JSON Input" field.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.