Apache logs a message for every request. So you get a separate entry for every image/js/css file on every page. How would you filter that down to only hits on actual pages?
As in, a user comes to /about. Apache logs hits to /about, /js/blah.js, /css/style.css, and so on. How would you make sure you only get /about?
You would need something to actually make that correlation before you insert the data into Elasticsearch - Kibana can't do that with no additional information.
Since, as you note, Apache logs are stateless and only contain individual HTTP requests, tracking performance of the whole webpage usually requires adding additional tracking code to your website and basing your analytics on that. I'm familiar with boomerang developed by Yahoo, but there are probably others. You can also do it using your own code, as this blog describes.
Sticking tracking code in is the normal way to do it. But I was mainly looking for something like a pattern that helps exclude the most obviously non-page hits.
Basically, parsing apache logs is how you would get stats if you couldn't insert tracking code. It also might be more accurate since many people block javascript and/or Google Analytics.Or if you can't put tracking code on a page for some other reason.
Anyway, I was just curious to know if anyone had done something like this.
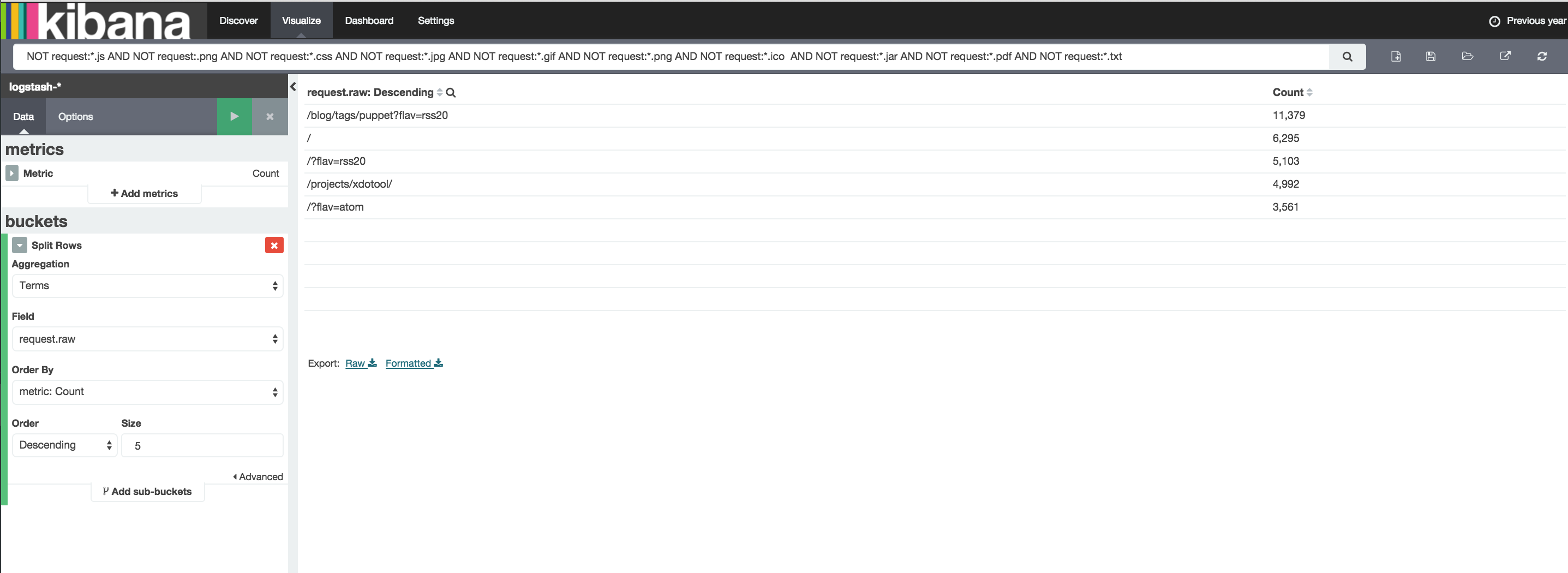
If you're looking to exclude files with certain extensions, you could exclude certain file types at the filter level (see attached). My worry is that the list might get quite long, though, so not sure how effective that'll be.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.