We are running a 3 node cluster to index logs from a firewall.
The nodes are VMs (8 Core CPUs, 8GB RAM). The host runs on Intel i7, and has SSD storage.
We have Kibana running on one of the nodes. The interface becomes slow to the point of being unresponsive.
We have ILM enabled and the number of shards stay around 125. Which is well within the limits if were to go by official documentation here - JVM Heap of 12GB (4GBx3 nodes). Max shard count of 240 (1220).*
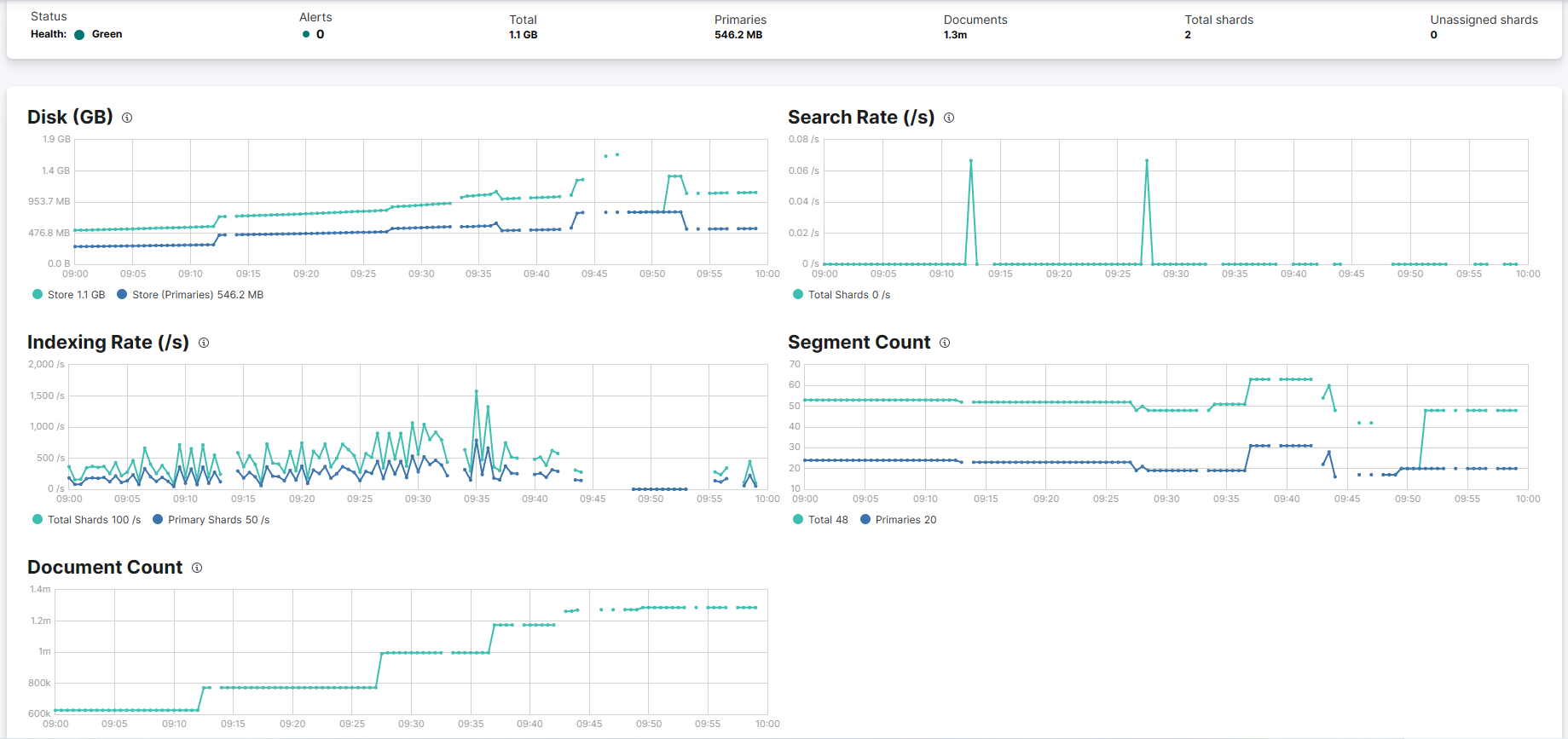
JVM memory allocation is done as per default, i.e, 50% of RAM. Some stats below:

There are frequent breaks in log ingestion visible in Kibana >> Observe

Breaks in indexing are also seen frequently while the system is unresponsive:
Elasticsearch logs:
Errors:
[2023-04-28T00:00:30,725][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:03:51,060][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:04:01,082][ERROR][o.e.x.m.c.i.IndexRecoveryCollector] [es-node121] collector [index_recovery] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:09:01,625][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:09:11,638][ERROR][o.e.x.m.c.i.IndexRecoveryCollector] [es-node121] collector [index_recovery] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:11:31,747][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:14:21,875][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:18:52,006][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:21:42,095][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:25:22,181][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:27:22,258][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:31:22,497][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:32:12,531][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:32:42,540][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:33:22,562][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:35:14,482][ERROR][o.e.x.m.c.i.IndexRecoveryCollector] [es-node121] collector [index_recovery] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:45:03,095][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:45:23,124][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T00:55:33,737][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:02:54,228][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:26:17,494][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:29:27,854][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:34:28,361][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:44:09,907][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:47:20,365][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T01:55:21,755][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T02:00:52,357][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T02:38:17,651][ERROR][o.e.x.m.c.i.IndexRecoveryCollector] [es-node121] collector [index_recovery] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T02:55:08,717][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T03:35:55,146][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T03:47:17,342][ERROR][o.e.x.m.c.i.IndexRecoveryCollector] [es-node121] collector [index_recovery] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T03:50:27,094][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T05:07:06,881][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T05:30:39,618][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T05:33:19,931][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T05:37:30,332][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
[2023-04-28T06:35:08,402][ERROR][o.e.x.m.c.c.ClusterStatsCollector] [es-node121] collector [cluster_stats] timed out when collecting data: node [LHj9iH-CTBesKk199fQHdA] did not respond within [10s]
WARN
[2023-04-28T00:04:02,217][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11s/11061ms] ago, timed out [1.1s/1132ms] ago, action [indices:monitor/recovery[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8893742]
[2023-04-28T00:04:38,077][WARN ][o.e.m.j.JvmGcMonitorService] [es-node121] [gc][640790] overhead, spent [674ms] collecting in the last [1s]
[2023-04-28T00:09:11,442][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [19.9s/19901ms] ago, timed out [9.8s/9808ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8897168]
[2023-04-28T00:09:17,934][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [16.2s/16229ms] ago, timed out [6.2s/6212ms] ago, action [indices:monitor/recovery[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8897222]
[2023-04-28T00:11:32,277][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.6s/10606ms] ago, timed out [629ms/629ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8898776]
[2023-04-28T00:13:38,539][WARN ][o.e.c.r.a.AllocationService] [es-node121] [firewall-2023.04.16][0] marking unavailable shards as stale: [3qtpYbc6TbiKhQMUWaGzJA]
[2023-04-28T00:14:00,151][WARN ][o.e.c.r.a.AllocationService] [es-node121] [.internal.alerts-security.alerts-default-000002][0] marking unavailable shards as stale: [m4T5zlUPQYihWTX4b0XAdw]
[2023-04-28T00:14:28,520][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [16.6s/16691ms] ago, timed out [6.6s/6628ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8900813]
[2023-04-28T00:18:53,008][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.9s/10924ms] ago, timed out [933ms/933ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8903910]
[2023-04-28T00:21:43,597][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.6s/11642ms] ago, timed out [1.6s/1625ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8905780]
[2023-04-28T00:25:22,785][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.7s/10770ms] ago, timed out [607ms/607ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8908324]
[2023-04-28T00:27:28,866][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [16.7s/16723ms] ago, timed out [6.5s/6567ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8909707]
[2023-04-28T00:30:09,163][WARN ][o.e.c.r.a.AllocationService] [es-node121] [firewall-2023.04.17][0] marking unavailable shards as stale: [KSPXN7khQ_i3tzwlXyUBjg]
[2023-04-28T00:30:42,354][WARN ][o.e.c.r.a.AllocationService] [es-node121] [admin_regions_lvl2_v2][0] marking unavailable shards as stale: [Kfw1vUjqRkCmjQATZ9J2Vw]
[2023-04-28T00:31:23,644][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.3s/11333ms] ago, timed out [1.3s/1307ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8912461]
[2023-04-28T00:31:51,062][WARN ][o.e.c.r.a.AllocationService] [es-node121] [world_map][0] marking unavailable shards as stale: [9oF8ed3qSwyJLlBVu_KU0A]
[2023-04-28T00:32:13,992][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.5s/11583ms] ago, timed out [1.4s/1436ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8912997]
[2023-04-28T00:32:20,448][WARN ][o.e.c.r.a.AllocationService] [es-node121] [.metrics-endpoint.metadata_united_default][0] marking unavailable shards as stale: [yeuNzJmbSzmJE4MPzvcS_A]
[2023-04-28T00:32:44,762][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [12.3s/12380ms] ago, timed out [2.3s/2339ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8913271]
[2023-04-28T00:33:03,772][WARN ][o.e.c.r.a.AllocationService] [es-node121] [.fleet-files-endpoint-000001][0] marking unavailable shards as stale: [YlTueFo_R1WXk84S3dbT4g]
[2023-04-28T00:33:24,902][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [12.4s/12492ms] ago, timed out [2.3s/2357ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8913633]
[2023-04-28T00:33:50,036][WARN ][o.e.c.r.a.AllocationService] [es-node121] [indicators-29032023_1][0] marking unavailable shards as stale: [27xh1i9iSZ2SfSdG9Ny5_g]
[2023-04-28T00:34:31,782][WARN ][o.e.c.r.a.AllocationService] [es-node121] [.ds-.logs-deprecation.elasticsearch-default-2023.03.25-000002][0] marking unavailable shards as stale: [yJI6RTv9SPqnhQJSpxgwig]
[2023-04-28T00:34:54,965][WARN ][o.e.c.r.a.AllocationService] [es-node121] [.internal.alerts-security.alerts-default-000001][0] marking unavailable shards as stale: [PXkKhiX9SBe2qAmC_UFURA]
[2023-04-28T00:35:15,653][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.1s/11111ms] ago, timed out [1.1s/1122ms] ago, action [indices:monitor/recovery[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8914782]
[2023-04-28T00:45:03,618][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.5s/10564ms] ago, timed out [402ms/402ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8921794]
[2023-04-28T00:45:23,912][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.8s/10863ms] ago, timed out [812ms/812ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8921957]
[2023-04-28T00:55:35,542][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.7s/11723ms] ago, timed out [1.7s/1709ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8929133]
[2023-04-28T01:01:58,932][WARN ][o.e.c.r.a.AllocationService] [es-node121] [firewall-2023.04.13][0] marking unavailable shards as stale: [zsUKGNvnTm-RXESlT0qsSw]
[2023-04-28T01:02:55,694][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.3s/11307ms] ago, timed out [1.3s/1336ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8934247]
[2023-04-28T01:26:18,177][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.6s/10692ms] ago, timed out [635ms/635ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8951734]
[2023-04-28T01:29:29,294][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.4s/11437ms] ago, timed out [1.4s/1436ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8953997]
[2023-04-28T01:34:30,799][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [12.4s/12412ms] ago, timed out [2.4s/2452ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8957642]
[2023-04-28T01:44:11,349][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.5s/11592ms] ago, timed out [1.5s/1578ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8964790]
[2023-04-28T01:47:20,869][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.4s/10470ms] ago, timed out [442ms/442ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8967044]
[2023-04-28T01:55:26,336][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [14.6s/14682ms] ago, timed out [4.4s/4472ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8972999]
[2023-04-28T02:00:54,597][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [12.2s/12280ms] ago, timed out [2.2s/2267ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [8977069]
[2023-04-28T02:38:21,185][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [13.5s/13551ms] ago, timed out [3.5s/3512ms] ago, action [indices:monitor/recovery[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9004840]
[2023-04-28T02:55:09,427][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [10.6s/10699ms] ago, timed out [643ms/643ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9017307]
[2023-04-28T03:35:56,912][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.5s/11588ms] ago, timed out [1.6s/1687ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9047555]
[2023-04-28T03:47:18,436][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.2s/11227ms] ago, timed out [1s/1080ms] ago, action [indices:monitor/recovery[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9056023]
[2023-04-28T03:50:30,175][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [13.1s/13115ms] ago, timed out [3s/3097ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9058360]
[2023-04-28T05:07:12,138][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [15.3s/15358ms] ago, timed out [5.3s/5321ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9115484]
[2023-04-28T05:30:41,369][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.7s/11795ms] ago, timed out [1.7s/1769ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9132816]
[2023-04-28T05:33:25,900][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [16s/16039ms] ago, timed out [5.9s/5939ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9134618]
[2023-04-28T05:37:35,064][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [14.6s/14686ms] ago, timed out [4.6s/4610ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9137522]
[2023-04-28T06:35:10,368][WARN ][o.e.t.TransportService ] [es-node121] Received response for a request that has timed out, sent [11.9s/11978ms] ago, timed out [2s/2040ms] ago, action [cluster:monitor/stats[n]], node [{es-node120}{LHj9iH-CTBesKk199fQHdA}{Hm_ohKVwQzO8muJEgvzKDw}{es-node120}{192.168.1.120}{192.168.1.120:9300}{cdfhilmrstw}{8.7.0}{ml.allocated_processors_double=10.0, xpack.installed=true, ml.machine_memory=11477852160, ml.allocated_processors=10, ml.max_jvm_size=5742002176}], id [9178981]
The strange thing about these messages is that they appear even at odd hours when the indexing/log rate is low. Peak log rate hovers around 1000-1200/s. The errors appearing at odd hours makes me wonder if it really is that the nodes are running out of RAM or the cause could be something else.
As a part of troubleshooting we have tried to increase the RAM on one of the VMs to 12GB, it didn't have any positive impact.
What else can be tried?




