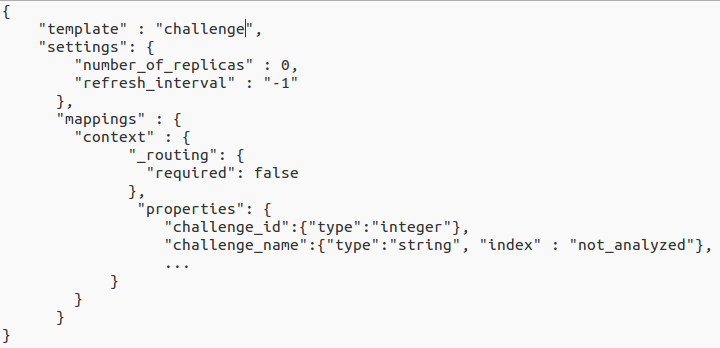
Executing the index process in 1 hour the total of indexed documents was only 2 millions which leads me to think that there is something wrong about logstash configuration, elasticsearch configuration or anything else.
Is there some configuration wrong? Have I change the ec2 instances configurations?
Someone could give me some insights about how to index a large bulk of data?
A quick test for logstash would be to send the data output to /dev/null just to see the CSV get read, parsed and outputed without disk speeds
replace your elasticsearch section with
output{
file{
path => "/dev/null"
}
}
for example I index about 10K docuements per second on 9 data nodes, each with 24 cpu's and 30GB heap, and EMC SAN. but my documents are also pretty complex.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.