We made the switch from G1 to CMS on the entire stack and not only has it indeed, solved the run away CPU problem, look at how much more stable the response times have:
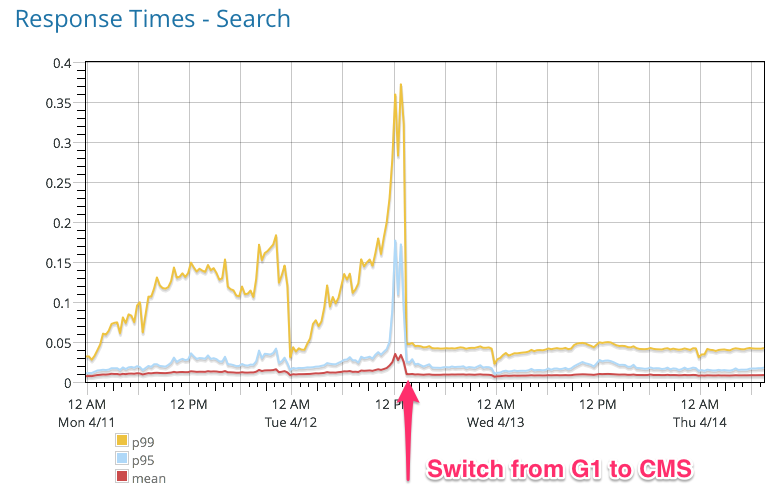
Crazy to see such a difference in the higher percentiles.
Thanks to everyone here who helped figure this out, I can stop complaining about ES now 