Hello, 
We are using Fluentbit to ingest Kubernetes cluster logs into Elasticsearch.
Not sure what I am setting wrong, but every day, as the index grows, ingestion is worsening from 550k op/s to 40k op/s...
Ingestion from fluentbit agent is constant but at some point ES will slow down, starting to queue more and more, using less cpu and rejecting new write

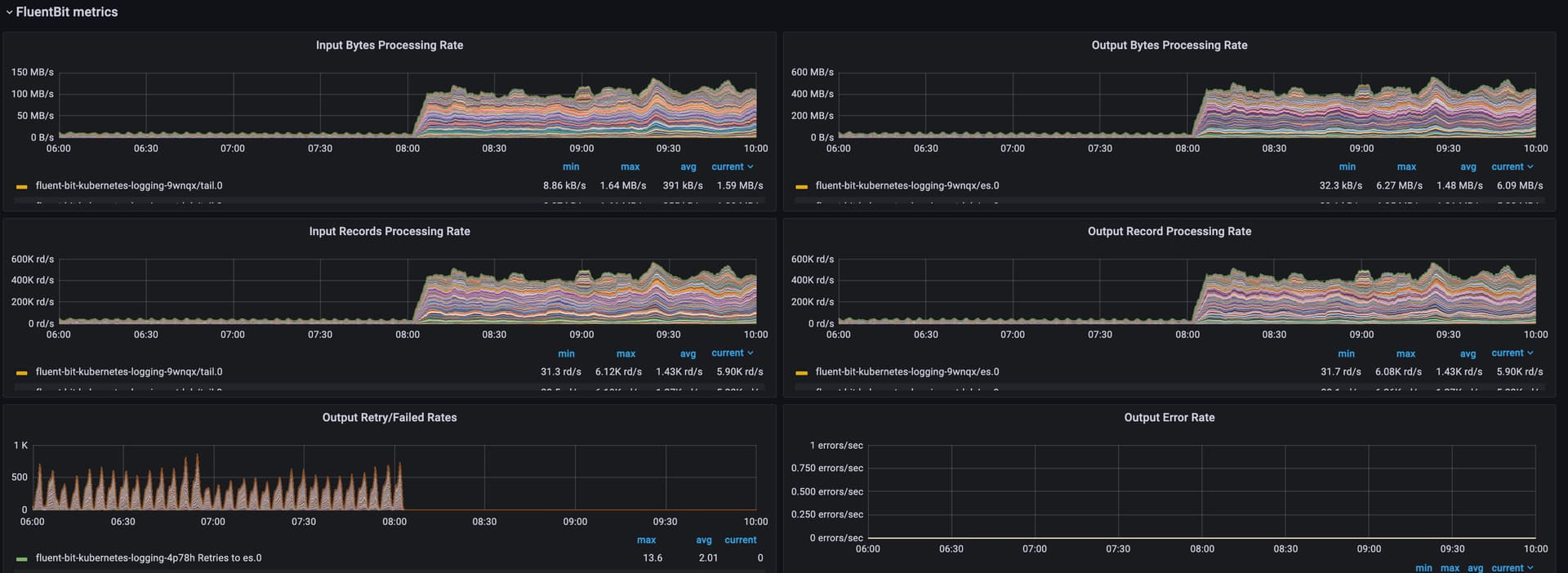
Setup:
Fluentbit 1.8.9
Kube Cluster: 403 nodes
Elastic: 30 datanodes 8C 16G
Our main usage in ingestion, not so much querying, so for the index template I set:
"refresh_interval": "60s",
"number_of_shards": "30"
"translog": { "durability": "async" },
"number_of_replicas": "0"
Today we will try to also add:
indices.memory.index_buffer_size: 30%
The index is rolled up daily (fluentbit use the date in the index name it write to), and we move the index to warm phase after 2 days.
FluentBit config:
[SERVICE]
Flush 1
Daemon Off
Log_Level info
Parsers_File parsers.conf
HTTP_Server On
[INPUT]
Name tail
Path /var/log/containers/*.log
Tag kube.*
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 512MB
Skip_Long_Lines On
Docker_Mode On
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
Merge_Log_Key json_message
K8S-Logging.Parser On
K8S-Logging.Exclude Off
Annotations Off
[OUTPUT]
Name es
Match kube.*
Host ${ELASTICSEARCH_HOST}
Port ${ELASTICSEARCH_PORT}
Generate_ID On
Logstash_Format On
Replace_Dots On
Logstash_Prefix kube-containers-${CLUSTER_NAME}
Retry_Limit 10
Suppress_Type_Name On
Trace_Error On
Buffer_Size False
Any idea ? If I set to create more shards could it bring any benefits ? (should ease queries but just add overheard for ingestion right ?)
Thanks !!
