Hi Team,
I have a logstash instance that's been running for a while now but started falling over due to OutOfMemory error since yesterday.
The memory is set as -Xms1g -Xmx1g.
And it would continue to go out of memory right after every time it is restarted - in the logs, there are not many useful logs - the only line relating to the OOM is:
[2018-04-25T09:24:32,557][ERROR][logstash.inputs.metrics ] Failed to create monitoring event {:message=>"undefined method `ephemeral_id' for nil:NilClass", :error=>"NoMethodError"}
[2018-04-25T09:24:37,813][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x1ae39f8f sleep>"}
[2018-04-25T09:24:38,044][INFO ][logstash.agent ] Pipelines running {:count=>2, :pipelines=>[".monitoring-logstash", "main"]}
[2018-04-25T09:30:30,279][ERROR][org.logstash.Logstash ] java.lang.OutOfMemoryError: Java heap space
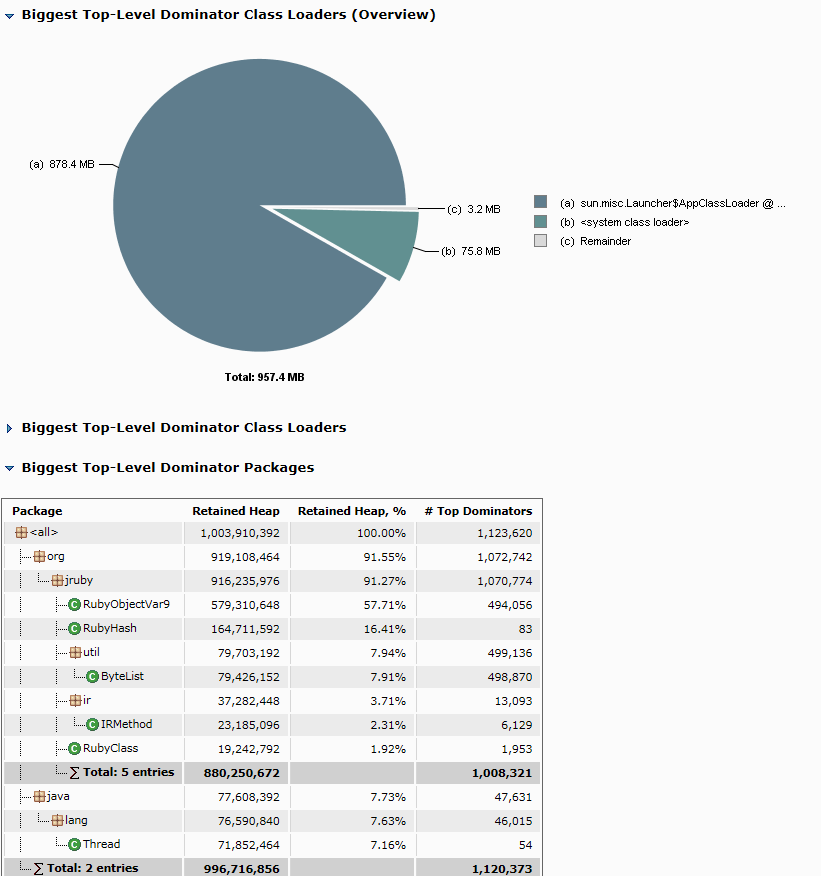
I've also looked at the heap dump but because I do not know the code base I was not able to draw a conclusion - I've attached the heap dump breakdown below for your reference.
However, upon investigation, I noticed there is one .since-db file that is quite large - it is nearly 9MB in size and has nearly 400,000 lines of content because under the logs folder there's 400,000 log files 
I have tested by moving that .since-db file away, and restarting logstash and voila, logstash would not fall over anymore.
However, as soon as I put back that big .since-db file back, and restart logstash, logstash would again crash due to OOM every time it tries to boot up.
So I guess my questions are:
- Is it normal for a .since-db file to grow that large?
- Is it normal for logstash to go OOM (surely not
 ) due to a large .since-db file?
) due to a large .since-db file? - What is your advice for preventing the above?
- I also noticed that when the large .since-db file is loaded, logstash creates a lot of "children" .since-db files of that large .since-db file that have name in the format like this: .sincedb-foobar.2064.13026.47260, and they all have zero content, they all have size 0 - what are these files?
Below is the relevant file input bit in my logstash.conf:
file {
sincedb_path => "/var/tmp/.sincedb-foobar"
max_open_files => 10000
close_older => 60
ignore_older => 1296000 # 15 days
path => "/foo/bar/*"
type => "foobar"
start_position => "beginning"
codec => multiline {
patterns_dir => ["${LS_PATTERNS}"]
pattern => "^%{TIMESTAMP_ISO8601}"
negate => "true"
what => "previous"
auto_flush_interval => 60
max_lines => 5000
}
}


 Timing.
Timing.