I have just finished rebuilding my entire ELK stack environment. I got the clusters build last night and finished turning everything back on about 3 hours ago.
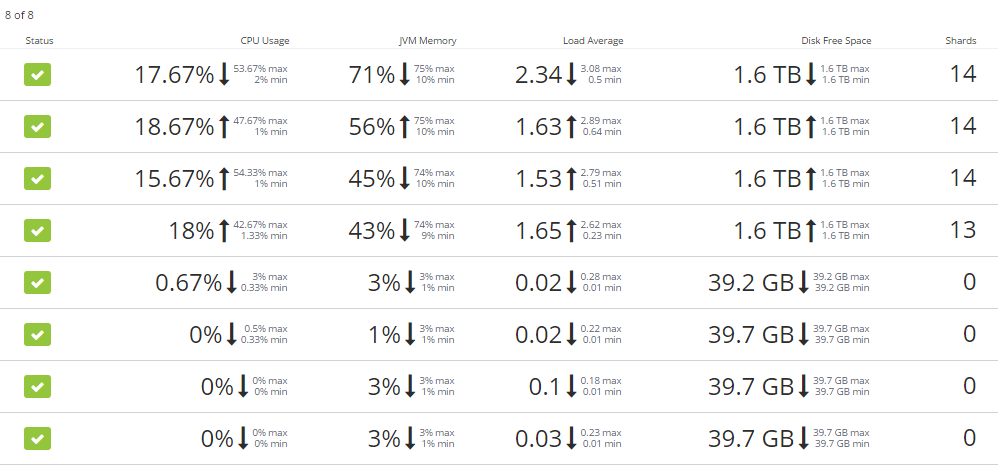
With the help of others in here and the Logstash forums, I was able to correct several settings related to shards and replicas. So, here is a quick run down of my setup. I have 26 locations, running Logstash, that parse and forward into 2 data center clusters.
Each DC cluster is 8 servers.
- 1 Kibana client node
- 3 Master nodes
- 4 Data nodes
All external Logstash servers are configured for all 3 master nodes, round robin.
output {
elasticsearch {
hosts => ["http://x.x.x.x:9200","http://x.x.x.x:9200","http://x.x.x.x:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
I get this from checking the cluster health:
MASTER-SERVER:~$ curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
{
"cluster_name" : "CLUSTER",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 8,
"number_of_data_nodes" : 4,
"active_primary_shards" : 9,
"active_shards" : 9,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
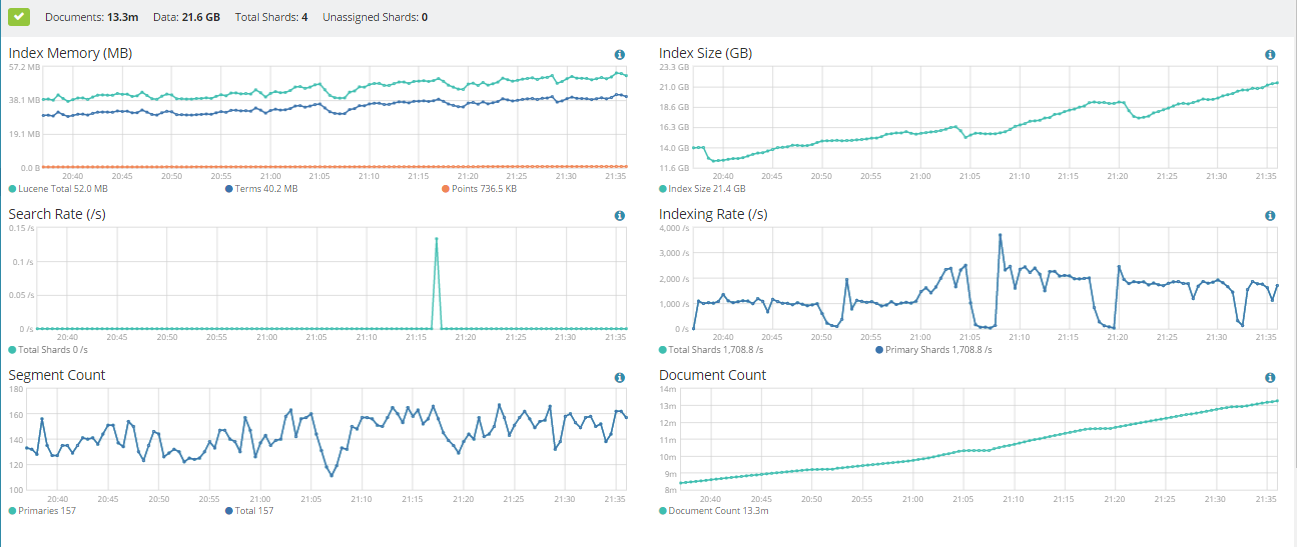
Here is a shard count:
MASTER-SERVER:~$ curl -XGET 'http://localhost:9200/_cat/count?v'
epoch timestamp count
1484950824 17:20:24 30078971
Here are the settings:
MASTER-SERVER:~$ curl -XGET 'http://localhost:9200/_settings?pretty'
{
"logstash-2017.01.19" : {
"settings" : {
"index" : {
"refresh_interval" : "5s",
"number_of_shards" : "4",
"provided_name" : "logstash-2017.01.19",
"creation_date" : "1484943134900",
"number_of_replicas" : "0",
"uuid" : "957Z9QcUSJSCzc97AJhK7A",
"version" : {
"created" : "5010299"
}
}
}
},
"logstash-2017.01.20" : {
"settings" : {
"index" : {
"refresh_interval" : "5s",
"number_of_shards" : "4",
"provided_name" : "logstash-2017.01.20",
"creation_date" : "1484940151889",
"number_of_replicas" : "0",
"uuid" : "PL2WTAWETAulatYdccILaw",
"version" : {
"created" : "5010299"
}
}
}
}
}
Here the status of my shards:
manager@KNOX-LOGMS-01:~$ curl -XGET 'http://localhost:9200/_cat/shards?v&s=node'
index shard prirep state docs store ip node
logstash-2017.01.20 0 p STARTED 9030811 17.6gb x.x.x.x DATA-NODE01
logstash-2017.01.19 0 p STARTED 86795 54.5mb x.x.x.x DATA-NODE01
logstash-2017.01.20 1 p STARTED 9016759 17.8gb x.x.x.x DATA-NODE02
logstash-2017.01.19 1 p STARTED 85824 53.8mb x.x.x.x DATA-NODE02
logstash-2017.01.20 3 p STARTED 9042439 17.7gb x.x.x.x DATA-NODE03
logstash-2017.01.19 3 p STARTED 85905 53.8mb x.x.x.x DATA-NODE03
logstash-2017.01.20 2 p STARTED 8998451 17.7gb x.x.x.x DATA-NODE04
logstash-2017.01.19 2 p STARTED 85581 53.7mb x.x.x.x DATA-NODE04
Here is a log that I am seeing, coming from one of the endpoint, running Logstash forwarding to the DC cluster.
<13>Jan 20 16:44:13.869466 LOGSERVER [2017-01-20T16:44:12,960][INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 429 ({"type"=>"es_rejected_execution_exception", "reason"=>"rejected execution of org.elasticsearch.transport.TransportService$6@b0521cb on EsThreadPoolExecutor[bulk, queue capacity = 50, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@300b72e4[Running, pool size = 4, active threads = 4, queued tasks = 50, completed tasks = 2142248]]"})
I am at a loss as to what is left to do.