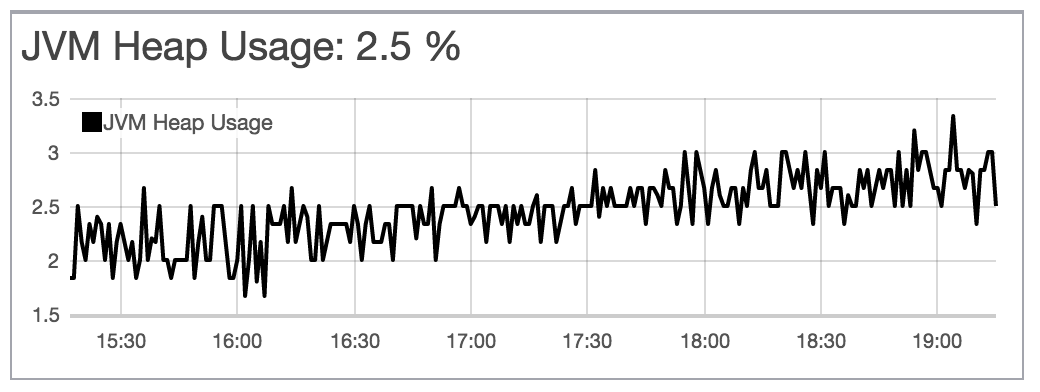
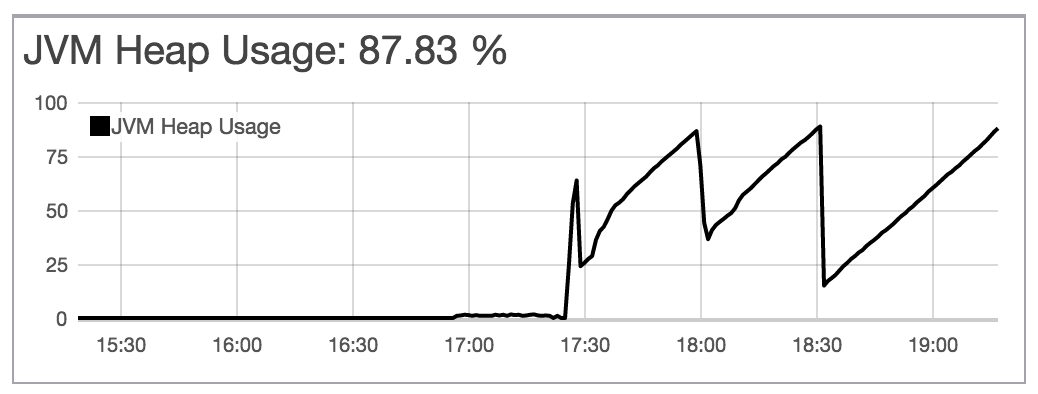
Hello,
I am upgrading my Elasticsearch cluster with 4 nodes from 14.04 (ES 2.3.2) to Ubuntu 16.04 (ES 2.3.3). I upgraded the ES first to the latest 2.3.3 on Ubuntu 14.04 to see what happens and everything is green and functional. So I started to install a fresh Ubuntu 16.04 and Elasticsearch with my configs.
Now I am seeing these warnings. Also it fails to lock the memory. I have swap off (no partition for swap at all) and 60GB of memory on each machine and all it shows in top is less than 2GB:
[2016-05-25 17:35:37,125][WARN ][bootstrap ] Unable to lock JVM Memory: error=12,reason=Cannot allocate memory
[2016-05-25 17:35:37,126][WARN ][bootstrap ] This can result in part of the JVM being swapped out.
[2016-05-25 17:35:37,126][WARN ][bootstrap ] Increase RLIMIT_MEMLOCK, soft limit: 65536, hard limit: 65536
[2016-05-25 17:35:37,126][WARN ][bootstrap ] These can be adjusted by modifying /etc/security/limits.conf, for example:
# allow user 'elasticsearch' mlockall
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
[2016-05-25 17:35:37,126][WARN ][bootstrap ] If you are logged in interactively, you will have to re-login for the new limits to take effect.
[2016-05-25 17:35:37,582][INFO ][node ] [cluster-es-1] version[2.3.3], pid[940], build[218bdf1/2016-05-17T15:40:04Z]
[2016-05-25 17:35:37,583][INFO ][node ] [cluster-es-1] initializing ...
[2016-05-25 17:35:38,755][INFO ][plugins ] [cluster-es-1] modules [reindex, lang-expression, lang-groovy], plugins [license, marvel-agent, kopf, graph], sites [kopf]
[2016-05-25 17:35:38,836][INFO ][env ] [cluster-es-1] using [1] data paths, mounts [[/data (/dev/vdb1)]], net usable_space [1.8tb], net total_space [1.9tb], spins? [possibly], types [ext4]
[2016-05-25 17:35:38,836][INFO ][env ] [cluster-es-1] heap size [19.9gb], compressed ordinary object pointers [true]
[2016-05-25 17:35:38,837][WARN ][env ] [cluster-es-1] max file descriptors [65535] for elasticsearch process likely too low, consider increasing to at least [65536]
[2016-05-25 17:35:42,242][INFO ][node ] [cluster-es-1] initialized
[2016-05-25 17:35:42,243][INFO ][node ] [cluster-es-1] starting ...
What am I missing?
/etc/default/elasticsearch
ES_HEAP_SIZE=20g
MAX_OPEN_FILES=65536
MAX_LOCKED_MEMORY=unlimited
/etc/elasticsearch/elasticsearch.yml
bootstrap.mlockall: true
/etc/security/limits.conf
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
* soft nofile 999999
* hard nofile 999999
* soft memlock unlimited
* hard memlock unlimited
root soft nofile 999999
root hard nofile 999999
root soft memlock unlimited
root hard memlock unlimited
ulimit -a
file size (blocks, -f) unlimited
pending signals (-i) 241446
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 999999
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
max user processes (-u) unlimited
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
Node on Ubuntu 14.04:
"jvm": {
"timestamp": 1464192255402,
"uptime": "23.9h",
"uptime_in_millis": 86054857,
"mem": {
"heap_used": "518.5mb",
"heap_used_percent": 2,
"heap_committed": "19.9gb",
"heap_max": "19.9gb",
"non_heap_used": "105.7mb",
"non_heap_committed": "107.3mb",
Node on Ubuntu 16.04:
"jvm": {
"timestamp": 1464192290592,
"uptime": "2.6m",
"uptime_in_millis": 156539,
"mem": {
"heap_used": "389.8mb",
"heap_used_percent": 1,
"heap_committed": "19.9gb",
"heap_max": "19.9gb",
"non_heap_used": "81.7mb",
"non_heap_committed": "83.2mb",
Even though the jvm stats are relatively the same but that's what I see in my machine:
Ubuntu 16.04: free -m
total used free shared buff/cache available
Mem: 60399 1653 58212 8 533 58618
Swap: 0 0 0
Ubuntu 14.04: free -m
total used free shared buffers cached
Mem: 60400 58669 1731 0 326 35014
-/+ buffers/cache: 23328 37071
Swap: 0 0 0