Hi,
We found an OOM error when elasticsearch was merging segments.
Our cluster
4 instances of c3.xlarge instances running on aws running elasticsearch 1.7.0
There is continuous indexing of small documents (~5kb) at the rate of 4000 per second.
Documents are being written to ES from a storm cluster of 3 nodes.
Here are the JVM args used:
-server -Djava.net.preferIPv4Stack=true
-Xms4479m -Xmx4479m -Xss256k -XX:NewRatio=1
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly
-XX:+HeapDumpOnOutOfMemoryError
After some period of time found that the cluster was in yellow state.
Found OOM errors on one of the nodes while looking into the logs and looking back at the first occurrence of this error, we found the following exception:
[2015-07-25 12:42:54,907][WARN ][transport.netty ] [metrics-datastore-4-es-tune] Message not fully read (request) for requestId [129230], action [indices:data/write/bulk[s]], readerIndex [64362] vs expected [202995]; resetting
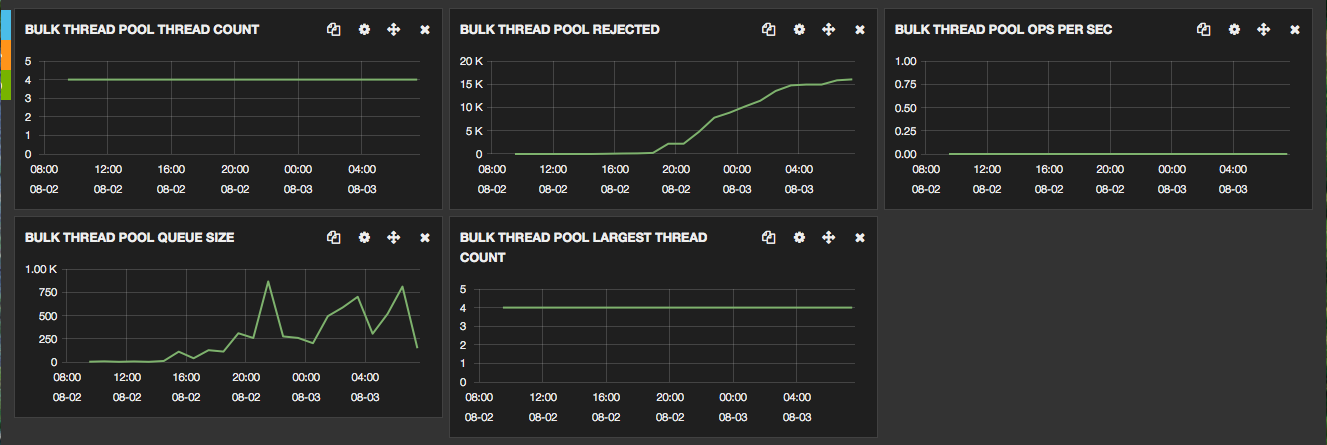
[2015-07-25 12:42:55,258][ERROR][marvel.agent.exporter ] [metrics-datastore-4-es-tune] create failure (index:[.marvel-2015.07.25] type: [node_stats]): EsRejectedExecutionException[rejected execution (queue capacity 100) on org.elasticsearch.action.support.replication.TransportShardReplicationOperationAction$PrimaryPhase$1@1ec774e7]
[2015-07-25 12:43:01,545][INFO ][monitor.jvm ] [metrics-datastore-4-es-tune] [gc][old][28074][1011] duration [6.1s], collections [1]/[6.5s], total [6.1s]/[46m], memory [4gb]->[3.8gb]/[4.1gb], all_pools {[young] [1.7gb]->[1.6gb]/[1.7gb]}{[survivor] [122.3mb]->[0b]/[224mb]}{[old] [2.1gb]->[2.1gb]/[2.1gb]}
[2015-07-25 12:43:02,508][WARN ][index.merge.scheduler ] [metrics-datastore-4-es-tune] [asdf3003444][0] failed to merge
org.apache.lucene.store.AlreadyClosedException: refusing to delete any files: this IndexWriter hit an unrecoverable exception
at org.apache.lucene.index.IndexFileDeleter.ensureOpen(IndexFileDeleter.java:354)
at org.apache.lucene.index.IndexFileDeleter.deleteFile(IndexFileDeleter.java:719)
at org.apache.lucene.index.IndexFileDeleter.refresh(IndexFileDeleter.java:451)
at org.apache.lucene.index.IndexWriter.merge(IndexWriter.java:3826)
at org.apache.lucene.index.ConcurrentMergeScheduler.doMerge(ConcurrentMergeScheduler.java:409)
at org.apache.lucene.index.TrackingConcurrentMergeScheduler.doMerge(TrackingConcurrentMergeScheduler.java:107)
at org.apache.lucene.index.ConcurrentMergeScheduler$MergeThread.run(ConcurrentMergeScheduler.java:486)
Caused by: java.lang.OutOfMemoryError: Java heap space
at org.apache.lucene.util.packed.PackedInts.getReaderIteratorNoHeader(PackedInts.java:865)
at org.apache.lucene.codecs.compressing.CompressingStoredFieldsReader$ChunkIterator.next(CompressingStoredFieldsReader.java:471)
at org.apache.lucene.codecs.compressing.CompressingStoredFieldsWriter.merge(CompressingStoredFieldsWriter.java:368)
at org.apache.lucene.index.SegmentMerger.mergeFields(SegmentMerger.java:332)
at org.apache.lucene.index.SegmentMerger.merge(SegmentMerger.java:100)
at org.apache.lucene.index.IndexWriter.mergeMiddle(IndexWriter.java:4223)
at org.apache.lucene.index.IndexWriter.merge(IndexWriter.java:3811)
... 3 more
Questions:
1, This seems to suggest that merging resulted in the OOM error. Does merging load the segments into memory while merging?
2, What is a safe value for index.merge.policy.max_merged_segment? In this setup it was set to 5g with index.merge.policy.max_merge_at_once: 4. Are we expected to configure these settings based on JVM heap size?
3, Looking into other settings, what is a good value for index.translog.flush_threshold_size?