I have following setup and I am missing documents. it is very hard to pinpoint at this time. that is why posting here to get some idea
1000 machine running metricbeat sending metric every min to HA proxy
Ha Proxy then sends data to 5 logstash server.
5 logstash server parse the data and send to elasticsearch cluster. Logstatsh is also creating _id because without creating _id I was getting duplicate entry.
I am stil missing data, reason I know it is missing is because of process metric.
For example user process is running for 10 min and it is sending data for few min stops and then shows up again. there is no exact timeframe or exact system that is showing this behavior. it is all random. I am trying to see some pattern but it is complete random. logstash server are not throwing any error that it didn’t ingested some data. elastic cluster is also not showing any error that it rejected anything.
Haproxy has no error either. Elastic output index is datastream.
only talking about process metric, because only issue with them. other metrics are there all the time.
_id = jobno_hostname_pid_@timestamptimestamp ( this will make sure one id for a process per system per min)
here is extract of logstash.
if ([system][process][cmdline]) {
if ( "JOBNO" in [system][process][cmdline]) {
grok {
tag_on_failure => ["grok_parse_failed"]
match => {"[system][process][cmdline]" => "%{GREEDYDATA:rm1}:%{WORD:project} %{WORD:rm2}=%{NUMBER:jobno:int}" }
match => {"[system][process][cmdline]" => "%{GREEDYDATA:rm1} %{GREEDYDATA:rm2}=%{NUMBER:jobno:int} %{GREEDYDATA:rm3}" }
match => {"[system][process][cmdline]" => "%{GREEDYDATA:rm1}:%{WORD:project} %{GREEDYDATA:rm2}=%{NUMBER:jobno:int}" }
match => {"[system][process][cmdline]" => "%{GREEDYDATA:rm1}=%{NUMBER:jobno:int}" }
}
if ![project] {
mutate { add_field => { "[system][process][project]" => "NA" } }
}
else {
mutate { add_field => { "[system][process][project]" => "%{project}" } }
}
# process.name has 15 char limit /proc/pid/stats, which is unix limit
# we need full name of process hence this
ruby { code => "event.set('process_fullname', event.get('[system][process][cmdline]').split(' ').first.split('/').last)" }
if ([process_fullname] == "bash" or [process_fullname] =~ /python/) {
ruby { code => "event.set('process_fullname', event.get('[system][process][cmdline]').split(' ')[1].split('/').last)" }
}
# create jobno and hpid
mutate { add_field => { "[system][process][jobno]" => "%{jobno}" }
add_field => { "[system][process][hpid]" => "%{[host][name]}_%{[process][pid]}" }
add_field => { "[system][process][jhpid]" => "%{jobno}_%{[host][name]}_%{[process][pid]}" }
convert => { "[system][process][jobno]" => "integer" }
}
mutate { rename => { "[process_fullname]" => "[system][process][fullname]" }
rename => { "[process][pid]" => "[system][process][pid]" }
rename => { "[process][ppid]" => "[system][process][ppid]" }
rename => { "[process][pgid]" => "[system][process][pgid]" }
rename => { "[process][state]" => "[system][process][state]" }
}
# jobno_hostname_pid_@timestamp should make this uniq, because there is no same pid runs at same time in Linux
mutate { add_field => { "[@metadata][id]" => "%{[system][process][jhpid]}_%{@timestamp}" } }
} # end of if JOBNO
else if ([metricset][name] == "uptime" or [metricset][name] == "filesystem" or [metricset][name] == "process_summary" or [metricset][name] == "network" or [metricset][name] == "cpu" or [metricset][name] == "memory" or [metricset][name] == "diskio" or [metricset][name] == "load")
{
# Do some other process
}
There is no way it can collide with id because of pid can’t be duplicated on a same host.
Weird thing is same process (PID) is reporting few times then stops and then show up again in elasticsearch. this means my grok pattern is working fine as well.
So far I'm not sure you have made convincing case that there are "missing documents". You seem more to have inferred that, based on expectations, rather than observed same. I am likely wrong on this. But just maybe, if you elaborate on the evidence that a document was produced there, then sent there, and so on, it will help track down whats gone wrong.
e.g. this is a bit opaque to me
You are describing here what is supposed to happen, rather than demonstrating that it is actually happening. e.g. very first claim - the 1000 machines are sending process data to haproxy every minute, how did you verify that?
haproxy tcp mode is difficult to troubleshoot, as you dont have easy access to the actual individual messages. There's a fair few hacky ways, eg. "tee" the incoming traffic using iptables or port mirroring to some other host for analysis, or use socat scripts, .... Or just packet capture and try to trace all the way E2E. But logstash allows multiple outputs, so you can enable additional debugging there and try to pair with what originated on your "1000 machines".
Kevin I understand but I can’t post this data as is due to proprietary data. but I can confirm I am missing data 100% sure.
this is happening as I am getting thousands of records per min.
big volume of data is what makes it very hard to debug.
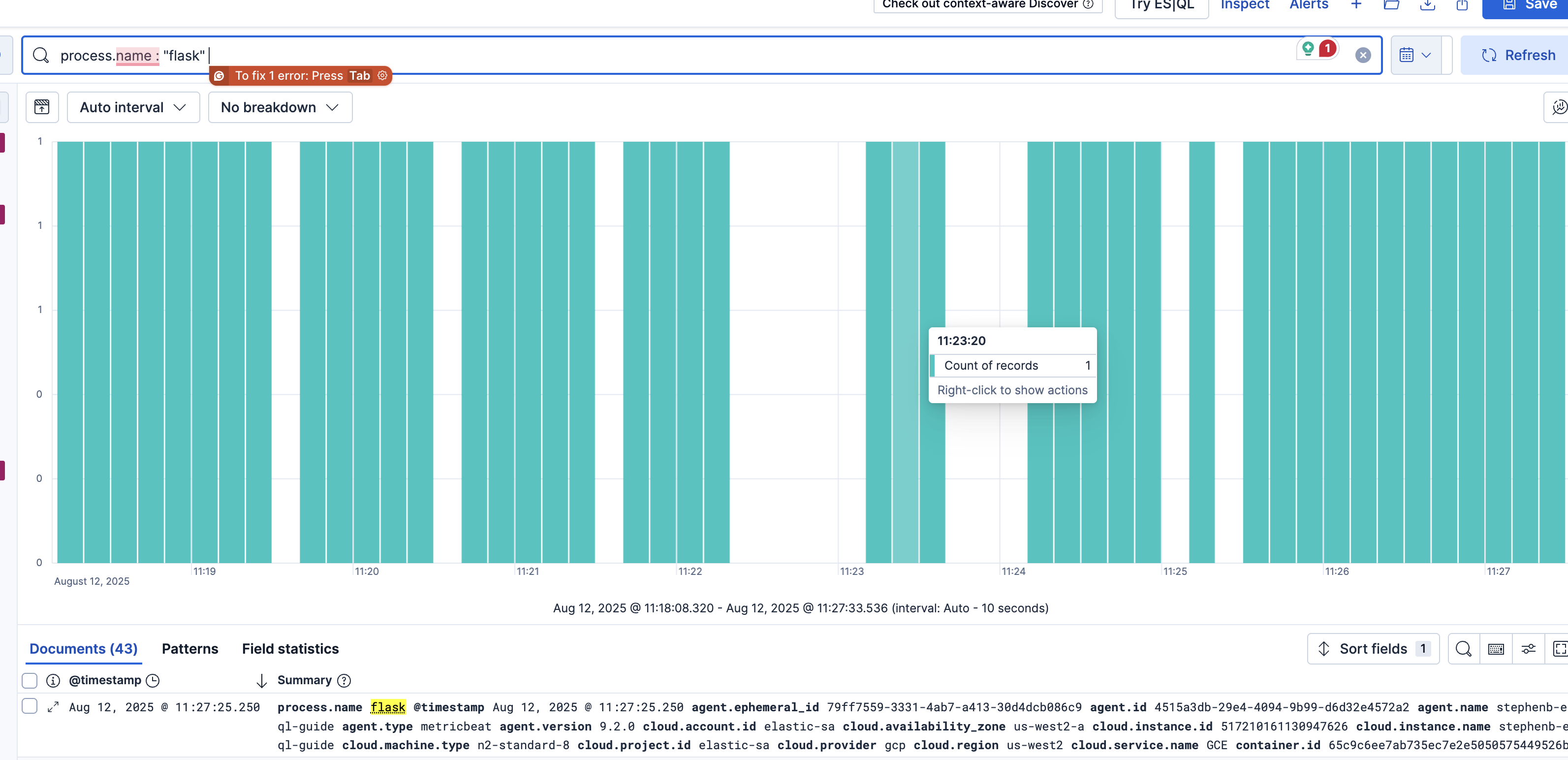
for example screenshot. this shows exact same process metric reported for few min then stop and reported, and this is random. not happening to same host again for few hours or days. that is why I don’t know how to check them.
Something like this is very difficult to troubleshoot as there are several steps in the ingestion pipeline where things could go wrong.
How frequently do you see this issue? Are there specific sets of devices that are affected or any pattern around periods of time where documents go missing?
Are there any connection probelms logged from the Metricbeat side? Metricbeat typically uses long-running connections and you are using a proxy, which is not standard. Is it possible that timeouts on proxy connections could be causing issues? Would it be possible to set up a new Logstash instance (or two) and have some Metricbeats connect directly to this and see whether or not that reduces data loss from those sources?
How are you handling parsing failures in Logstash? Are there written to Elasticsearch or perhaps a file that can be investigated?
I was writing much the same in parallel. I’d wager it’s a data collection issue — “gaps” caused by incorrect collection, parsing errors, intermittent processes with special characters in cmdline, stuff like that.
With 1,000 hosts, you’re bound to have a salad of the weird and wonderful.
And again: if everything worked as described, there would be no duplicates and no need for the hand-crafted _id. But there was, meaning there’s an underlying problem the hand-crafted _id is merely working around. My gut instinct tells me thats related here too.
Thank you every one for your input. yes this is defiantly weird one to debug.
all the time but random host at random interval. when this happens I still have cpu/memory/network metric from it. and parsing can’t be failed because process is still running with same argument.
good idea. let me work on it.
can do this as well.
this was initial issue two years ago when I design this setup. hence added _id afterward once I discover duplicate. thinking that proxy might be sending same record to two logstash and it does as I can see them on logstash logs. where it says record rejected because of version conflict.
This is no only two five metric. this is particular process metric which I do parse. basically from client side I drop most all root process and many other using drop filter. process metric I am looking for it jobs that we run on our HPC.
HPC is High Performance Computing in this context? The sort where (some) engineers have tuned their applications over years to try to squeeze every last flop of performance, and the CPU/memory/IO/... can often get significantly utilized?
<full disclosure, I was once one of those HPC engineers, if my CPUs weren't maxed out I'd felt that I'd done a bad job>
and as posted in logstash config. I parse anything which has system.process.cmdline exist and it has JOBNO (uppercase) exist. some job runs for days some for hours.
I am going to remove “weight 1” to roundrobin in haproxy. will see if it improves anything. ( this is gone a take day or two to validate if anything is missing)
next will redirect few hundred system directly to logstash bypassing haproxy. and check only on that batch of systems.
One thing to keep in mind is that the connection from Beats to Logstash is sticky, once connected it will not change unless the logstash endpoint has some issue and goes down.
From my experience this makes no difference, the connection will still be sticky, metricbeat will open a connection to haproxy and haproxy will then open a connection to one of the logstash servers, this will be sticky.
It is not the logs, but the output configuration in metricbeat.yml, how is the logstash output configured there? When using Logstash behind a load balancer there are some required configurations that you need to have for it to work as desired.
The traffic from metricbeat is just plaintext over TCP, right?
I repeat my suggestion from before, try tap the network port of the haproxy (input side), and you'll have a copy of all the traffic arriving at the haproxy. If you have a big memory machine you could tap it into a set of tmpfs (RAM) files to cover last X minutes/hours/... Then wait.
If this is the case, you should be able to see this fairly quickly, if the "missing" packets are frequent enough (if that's not an oxymoron!).
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.