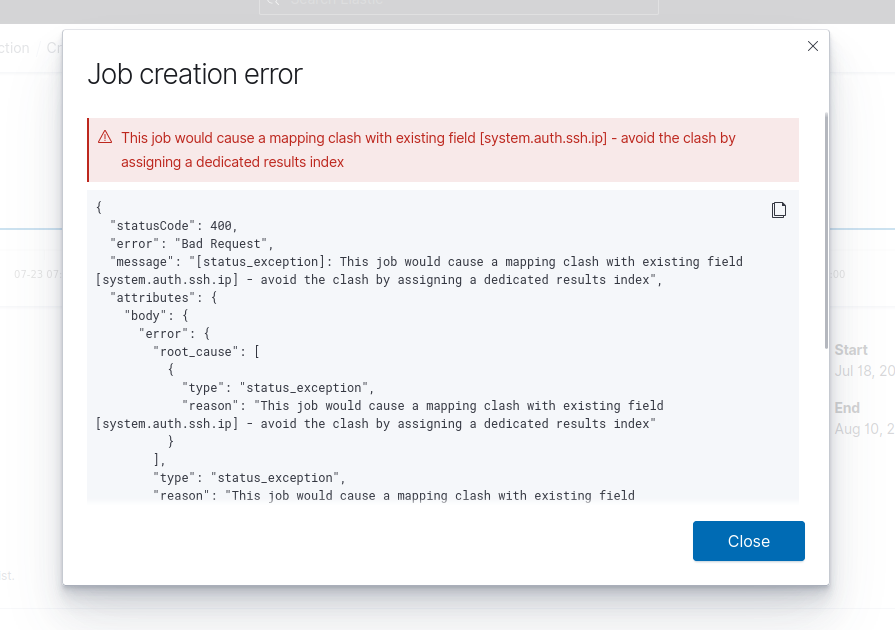
OK. After created job with keyword field, I got this
{
"job_id": "login_ssh_multi_metric",
"job_type": "anomaly_detector",
"job_version": "7.13.3",
"create_time": 1628622270365,
"finished_time": 1628622303319,
"model_snapshot_id": "1628622302",
"description": "",
"analysis_config": {
"bucket_span": "1m",
"detectors": [
{
"detector_description": "high_count partitionfield=\"system.auth.hostname.keyword\"",
"function": "high_count",
"partition_field_name": "system.auth.hostname.keyword",
"detector_index": 0
}
],
"influencers": [
"system.auth.hostname.keyword",
"system.auth.ssh.ip.keyword"
]
},
"analysis_limits": {
"model_memory_limit": "11mb",
"categorization_examples_limit": 4
},
"data_description": {
"time_field": "@timestamp",
"time_format": "epoch_ms"
},
"model_plot_config": {
"enabled": false,
"annotations_enabled": false
},
"model_snapshot_retention_days": 10,
"daily_model_snapshot_retention_after_days": 1,
"results_index_name": "custom-login_ssh_multi_metric",
"allow_lazy_open": false,
"data_counts": {
"job_id": "login_ssh_multi_metric",
"processed_record_count": 1685,
"processed_field_count": 958,
"input_bytes": 90377,
"input_field_count": 958,
"invalid_date_count": 0,
"missing_field_count": 2412,
"out_of_order_timestamp_count": 0,
"empty_bucket_count": 32938,
"sparse_bucket_count": 2,
"bucket_count": 32968,
"earliest_record_timestamp": 1626604733000,
"latest_record_timestamp": 1628582785000,
"last_data_time": 1628622272689,
"latest_empty_bucket_timestamp": 1628582640000,
"latest_sparse_bucket_timestamp": 1628529060000,
"input_record_count": 1685,
"log_time": 1628622272689,
"latest_bucket_timestamp": 1628582760000
},
"model_size_stats": {
"job_id": "login_ssh_multi_metric",
"result_type": "model_size_stats",
"model_bytes": 82740,
"peak_model_bytes": 104736,
"model_bytes_exceeded": 0,
"model_bytes_memory_limit": 11534336,
"total_by_field_count": 4,
"total_over_field_count": 0,
"total_partition_field_count": 3,
"bucket_allocation_failures_count": 0,
"memory_status": "ok",
"assignment_memory_basis": "current_model_bytes",
"categorized_doc_count": 0,
"total_category_count": 0,
"frequent_category_count": 0,
"rare_category_count": 0,
"dead_category_count": 0,
"failed_category_count": 0,
"categorization_status": "ok",
"log_time": 1628622302104,
"timestamp": 1628582700000
},
"forecasts_stats": {
"total": 0,
"forecasted_jobs": 0
},
"state": "closed",
"timing_stats": {
"job_id": "login_ssh_multi_metric",
"bucket_count": 32968,
"total_bucket_processing_time_ms": 18977.00000000005,
"minimum_bucket_processing_time_ms": 0,
"maximum_bucket_processing_time_ms": 532,
"average_bucket_processing_time_ms": 0.5756187818490673,
"exponential_average_bucket_processing_time_ms": 1.1737351400660319,
"exponential_average_bucket_processing_time_per_hour_ms": 60.74121520456408
},
"datafeed_config": {
"datafeed_id": "datafeed-login_ssh_multi_metric",
"job_id": "login_ssh_multi_metric",
"query_delay": "90505ms",
"chunking_config": {
"mode": "auto"
},
"indices_options": {
"expand_wildcards": [
"open"
],
"ignore_unavailable": false,
"allow_no_indices": true,
"ignore_throttled": true
},
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"match_phrase": {
"system.auth.ssh.event": "Failed password"
}
}
],
"must_not": []
}
},
"indices": [
"filebeat*"
],
"scroll_size": 1000,
"delayed_data_check_config": {
"enabled": true
},
"state": "stopped",
"timing_stats": {
"job_id": "login_ssh_multi_metric",
"search_count": 4,
"bucket_count": 32968,
"total_search_time_ms": 29,
"average_search_time_per_bucket_ms": 0.0008796408638679932,
"exponential_average_search_time_per_hour_ms": 20.478633887048332
}
}
}
The result didn't have value and system. auth.ssh.ip.