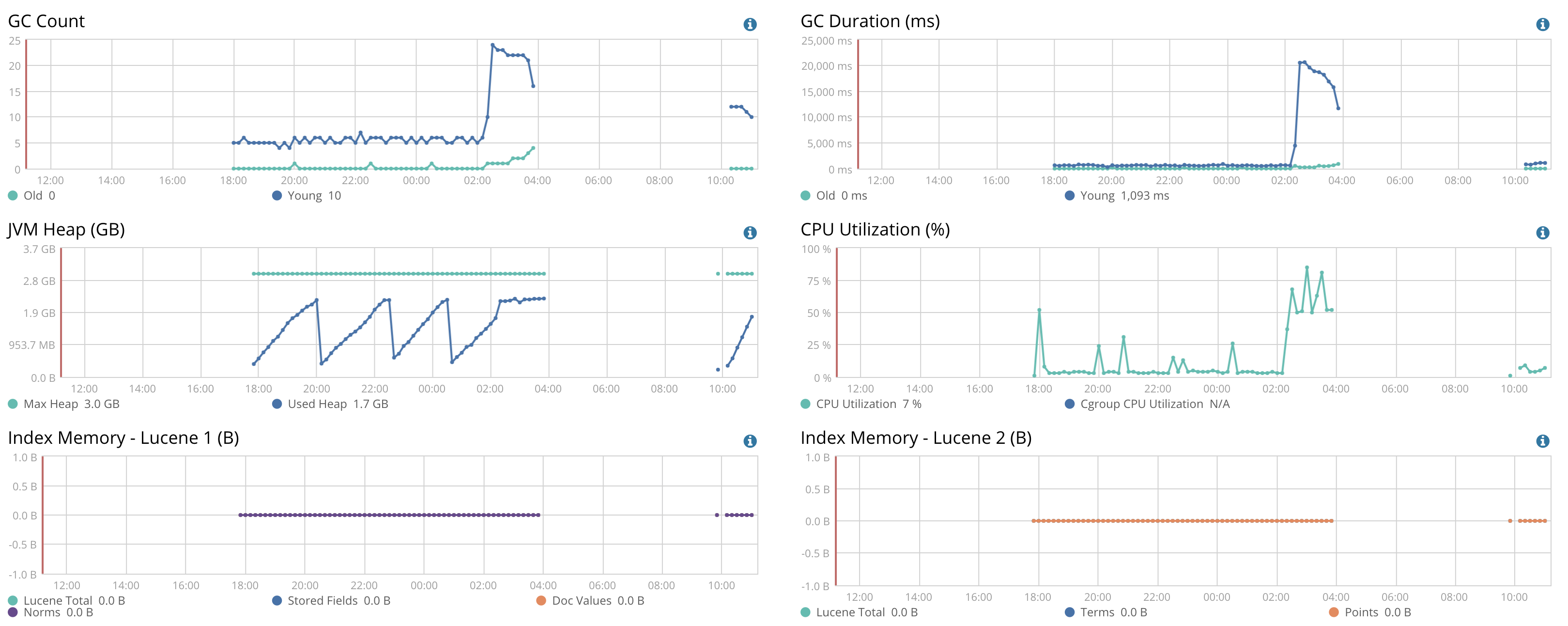
The masters and the ingest nodes borked with OutOfMemoryError, the data nodes seemed to have survived.
Master (each): 16GB of which ES_JAVA_OPTS="-Xms7g -Xmx7g"
Ingest (each): 4GB of which ES_JAVA_OPTS="-Xms3g -Xmx3g"
Coordinator (each): 64GB of which ES_JAVA_OPTS="-Xms30g -Xmx30g"
Data (each): 64GB of which ES_JAVA_OPTS="-Xms30g -Xmx30g"
All nodes running ubuntu JDK
openjdk version "1.8.0_162"
OpenJDK Runtime Environment (build 1.8.0_162-8u162-b12-0ubuntu0.16.04.2-b12)
OpenJDK 64-Bit Server VM (build 25.162-b12, mixed mode)
All nodes have
MAX_OPEN_FILES=65536
MAX_LOCKED_MEMORY=unlimited
MAX_MAP_COUNT=262144
The fact that master and ingest nodes have the problem but not data nodes suggests that the issue might be related to the size of your cluster state. Maybe you have many indexes / shards / fields? What is the size of the output of GET /_cluster/state?
Switching from daily to monthly requires reindexing, so it is better if you switch to monthly indices for all data. Kibana does not use date math based on index names any longer, so that is not a problem.
Cool so reading the docs... Snapshots only store the changed files correct? So if a monthly index has NOT changed in 31 days and we took 31 snapshots the snapshot repo would remain the same size and NOT have grown right?
Ok cool gotcha. So, 1 index with 5 shards is the same as 5 indexes with 1 shard each. And each shard is a Lucene index which takes up X amount of resources.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.