Python script runs once each month to create a monthly index using the bulk insert function in the elasticsearch module.
The script uses strings to define the field name during creation as shown below
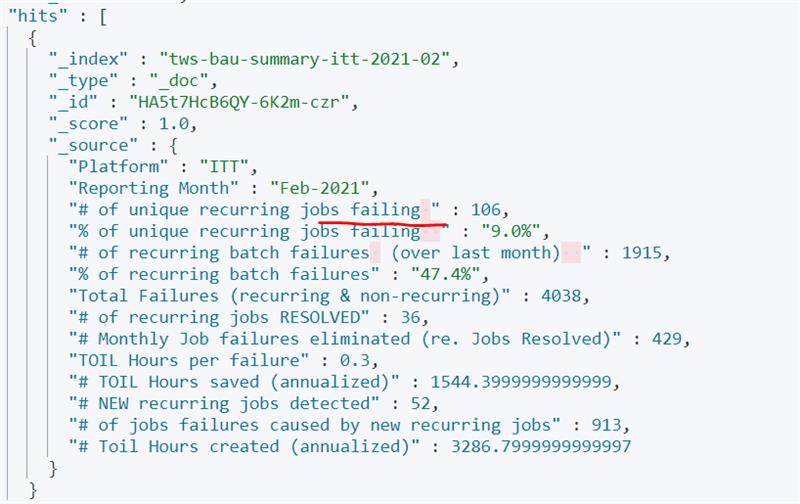
Issue: Visible pink spaces in Elasticsearch field names.
Even though the strings look perfectly normal above, strange pink spaces appear in the field names when inserted into Elasticsearch.
There's no issue using the field in visualizations per se. However, when my script generates data for a new month, the field names might have pink spaces at a different place.
For '# of unique recurring jobs failing' as an example, the name of the field differs between the Jan 2021 and Feb 2021 indices; thus unable to use it as a common field in an index pattern for visualizations.
I've tried to look up the issue online but it seems like an elusive shiny pokemon.
I've seen this problem once before and the pink areas were caused by special characters. I'd suggest you try having your python script write to a file, then view that file in a way that shows all special characters. In my case I can't remember if it was either \t (tab) or ^M (Windows Newline) causing the issue.
If you see any special characters that probably is your problem. You could also try setting python to encode your output in UTF-8 to see if that fixes/shows anything. Though it is weird that the pink spaces are showing up inconsistently.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.