We are using ElasticSearch 5.1.2:
Bootstrap is passed except system_call_filter, because we are running on CentOS 6
Here is the setting:
The document to be indexed have 1200 fields, each document is near 4K. But all the fields are consisted of three types: date, keyword, numberic. 24 millions records in total.
We want to use ElasticSearch to do near real-time aggregations.
We have three common nodes(master:true; data:true; ingest:default true) & one standalone ingest node(master:false; data:false; ingest:true). All these nodes jvm config are same as the following.Each node have 64GB memory, SSD, 24cores.
jvm.options:
-Xms24g
-Xmx24g
-XX:NewSize=8g
-XX:MaxNewSize=8g
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
We load data into ES by using elasticsearch-spark, DataFrame.saveToEs() method, which is bulk insert. We use 10 executers which means 10 clients to parallel insert to the ingest node.
Here is the performance we got.
Ingest Node's

detail

One of data node's
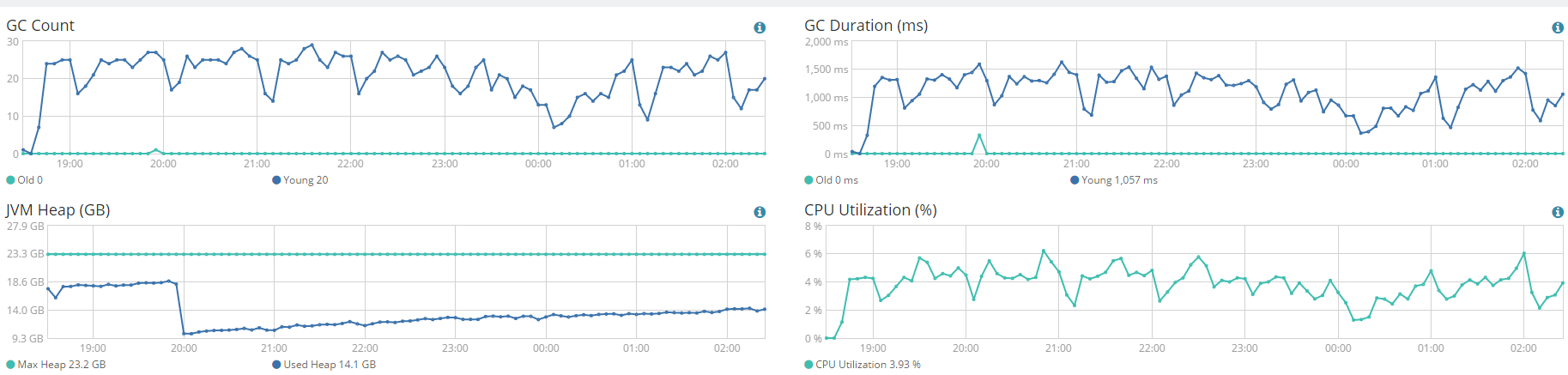
With 4 nodes, we only got index rate near 1000 document/s。 near 4 ms for indexing one document.
All the nodes' cpu usage is under 10%. it won't be bottleneck.Don't have throttle, bulk queue, bulk rejections, index queue, index rejections or other issues.
Increase client, the performance will deteriorate.
Settings of Index:
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 0,
"mapping.total_fields.limit": 1500,
"refresh_interval": "60s"
}
Settings of Cluster
Cluster:
{
"persistent": {
"indices": {
"store": {
"throttle": {
"max_bytes_per_sec": "100mb"
}
}
}
},
"transient": {}
}
Other settings are default.
My question is why indexing performance is so poor, only 1000 document/s and why ingest node is so heavy, happened so much young gc, even full gc.
From document, ingest does:
• intercepts bulk and index requests
• applies the transformations
• passes the documents back to the index or bulk APIs
We didn't use pipeline.