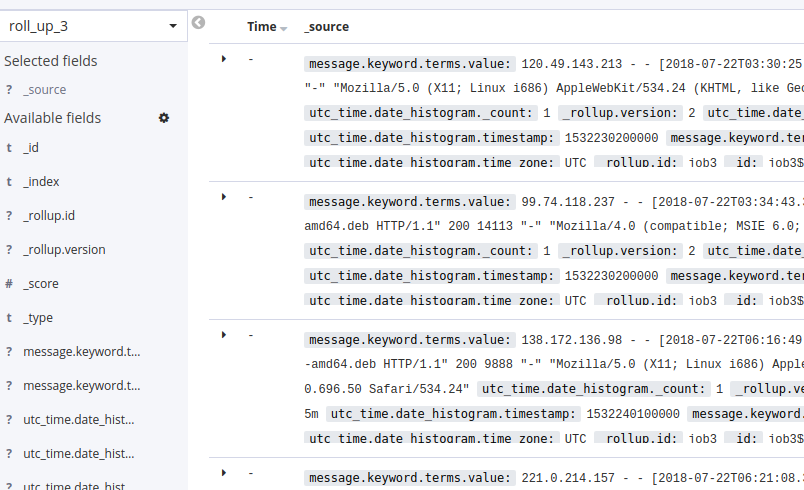
"Date field": timestamp
"Time bucket size": 10m
"Time zone": UTC
Terms
None
Histogram
None
Metrics
None
So as you see, it's a very basic configuration, but I can't get the Time field filled.
I also tried different combinations, such as selecting a term and some histogram to test it, but it doesn't work. Do you have any suggestions?
The time is in the field utc_time.date_histogram.timestamp. It's not showing up correctly in Discover because Discover is not meant to be used on rollup indicies. It's a tool optimized for inspecting individual documents.
When rolling up documents, this is not possible anymore (as there are not individual documents, just a technical pre-aggregated view).
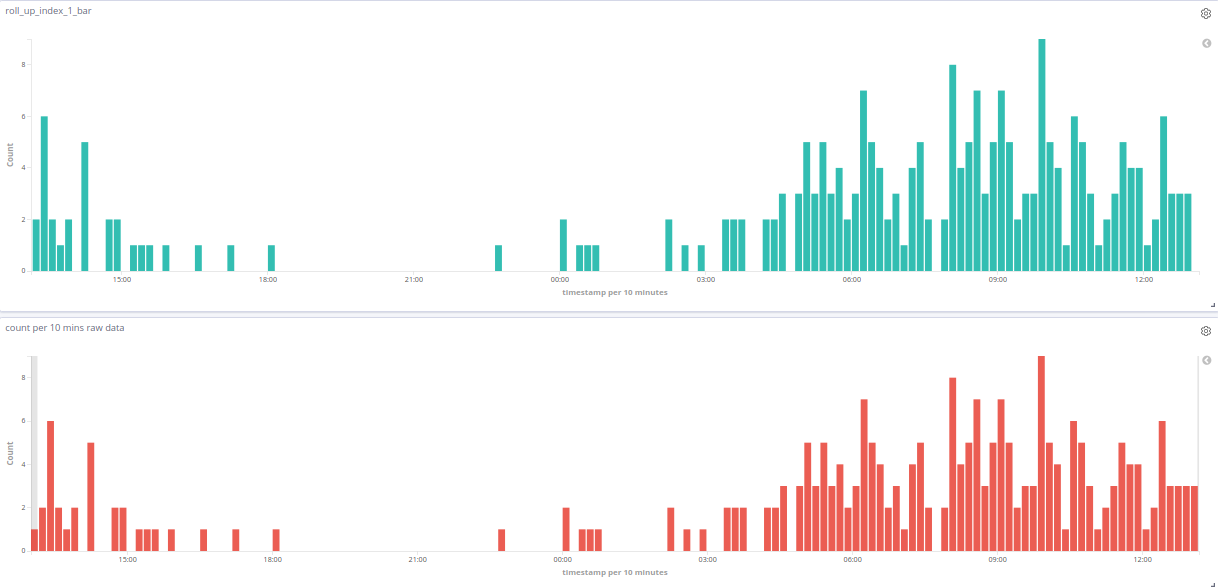
You can use Visualizations (which are based on aggregations) to look at the data in rollup indices.
Ok @flash1293, thank you, very much. That really explained a lot to me, and I think that is not explicitly expressed in the documentation..
So to conclude with my question, I would like to sum up with what was struggling me and how did I test it.
To begin with, the first time I dug into this, I understood that roll up indices would just "compress" my raw data, and it would be available to be queried again. But I thought that the query could be done in the "Discovery" section as any other, missing the part of the documentation that says it is possible to do queries across roll up indices via API only
Searching both historical rollup and non-rollup data
The Rollup Search API has the capability to search across both "live", non-rollup data as well as the aggregated rollup data.
source: Rollup search | Elasticsearch Guide [6.6] | Elastic
Without that in mind, in my head the logic was that roll up indices should have:
the same amount of documents in the roll up index as the raw index but with a much smaller storage size
data could be queried and filtered in the "Discover" section
All of that is WRONG, because:
the amount of documents should be different from the raw index, cause you are setting a time bucket which will be the minimum range of time to your new roll up index, so for example in a 10 minutes bucket are saving a "set of documents" together from the raw index (they are aggregated by the time bucket interval you set).
data can not be filtered and queried from the Discover section (thanks to @flash1293 for pointing that out), but you could do it from the API if you needed to
The only thing that I couldn't modify in the green visualization, is setting a timestamp per less than 10 minutes, cause that is the minimum time interval when i created the roll up index in this example.
Searching both historical rollup and non-rollup data
The Rollup Search API has the capability to search across both "live", non-rollup data as well as the aggregated rollup data.
source: Rollup search | Elasticsearch Guide [6.6] | Elastic
I agree, the use of the term "search" is also really confusing here - it's not about searching for documents, it's about querying the aggregates of the data. I guess this is due to the fact that in Elasticsearch, there is just a single endpoint for doing both (looking for individual documents and querying aggregated summaries)
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.