we run ECE in our own datacenters and internet access is only available via corporate proxy. The AWS S3 bucket works like a charm. ECE runs on RedHat Linux 7. We have configured the corporate proxy in: /usr/lib/systemd/system/docker.service.d/docker.conf
[Unit]
Description=Docker Service
After=multi-user.target
What is the best practice regarding snapshot repos on AWS, Gcloud or Azure if you run ECE in an on-premise Data Center and the only way to the internet is via a corporate proxy?
Thanks.
Cheers,
Mark
P.S. we did not find a clear answer in the documentation or other discussion topics.
Hi Alex, thanks for your response. We are a bit struggling with setting the proxy in de docker containers via /home/$user/.docker/config.json (https://docs.docker.com/network/proxy/). It seems not to work. Currently work in progress.
What we fail to understand is why do we need to set the S3 Repo on ECE level AND we should add the proxy ALSO in the elasticsearch.yml. Because with the latter we would still have manual maintenance on each Elasticsearch cluster (for each ES node) running on our ECE. Would this not contradict with the orchestration principle?
The way the Elasticsearch snapshot is structured, you have 3 different elements:
The repository info ("information needed to snapshot/restore given a blobstore", eg the bucket name) ... that lives in _snapshot
The client information ("info the blobstore client needs to connect to the blobstore"), split into:
insecure settings: blobstore endpoint, proxy settings, etc ... this lives in the YAML
secure settings: creds ... this lives in the keystore
For historical reasons the first and third (repo info and secure client info) can be set in the ECE repo object, and ECE then pulls out the creds and puts them in the keystore (Older versions of ES let you put everything together in the _snapshot object, but that is no longer the case)/
The insecure settings need to be set separately as part of a plan reconfiguration. The recommended way is that you create a Deployment Template and then those settings are "pre-loaded" into the YAML box when you create a deployment (you'd have to hand add them for existing deployments of course)
thanks! That makes sense. We will update it accordingly.
We already configured the S3 repository at ECE level.
So we would set in the elasticsearch.yml (deployment template):
s3.client.default.proxy.host: 10.10.10.something
s3.client.default.proxy.port: 8080
Just wondering why we would need that proxy information also needs to be configured in the docker container. Would Elasticsearch process not try to go via the proxy directly?
Thanks,
Mark
P.S. the s3.client proxy settings in the YAML did not work (maybe because the proxy env was not set in the Docker containers?). This is the error message from the ECE GUI:
There was a problem applying this configuration change
Plan change failed: [ClusterFailure:CouldNotEnsureSnapshotRepository]: Unable to ensure existence of snapshot repository. Please validate that the repository is accessible and retry. Details: [{"details":"status: [500 Internal Server Error], entity: [{\"error\":{\"root_cause\": [{\"type\":\"repository_verification_exception\",\"reason\":\"[found-snapshots] path [snapshots/46505578eb2748259fcb664823fd3a5b] is not accessible on master node\"}],\"type\":\"repository_verification_exception\",\"reason\":\"[found-snapshots] path [snapshots/46505578eb2748259fcb664823fd3a5b] is not accessible on master node\",\"caused_by\":{\"type\":\"i_o_exception\",\"reason\":\"Unable to upload object [snapshots/46505578eb2748259fcb664823fd3a5b/tests-qG-rvkiESRuDFO8VF18UfQ/master.dat] using a single upload\",\"caused_by\":{\"type\":\"sdk_client_exception\",\"reason\":\"sdk_client_exception: Unable to execute HTTP request: xyz-repo.s3.amazonaws.com\",\"caused_by\":{\"type\":\"i_o_exception\",\"reason\":\"ece-snapshot-repo.s3.amazonaws.com\"}}}},\"status\":500}], headers: [List()], protocol: [HttpProtocol(HTTP/1.1)]"}]
Unless ES itself doesn't support a host level proxy *, I don't see why the approach you initially took wouldn't work. Did you confirm that say wget inside the ES docker container was going via the corporate proxy?
To my knowledge we've never had anyone configure a proxy (including via Docker), so don't have any experience of ways in which it might fail. I assume just setting the proxy at the host level doesn't work?
* (I don't know that, the fact it has a proxy field suggests someone had issues at some point though! It would be a question for the stack forum)
In terms of your config - is default the right client? Eg if you do GET _snapshot/found-snapshots, is there a client_name field?
(One other thing I'm not sure about that fails in the "stack question" category is how the proxy setting handles HTTP/HTTPS)
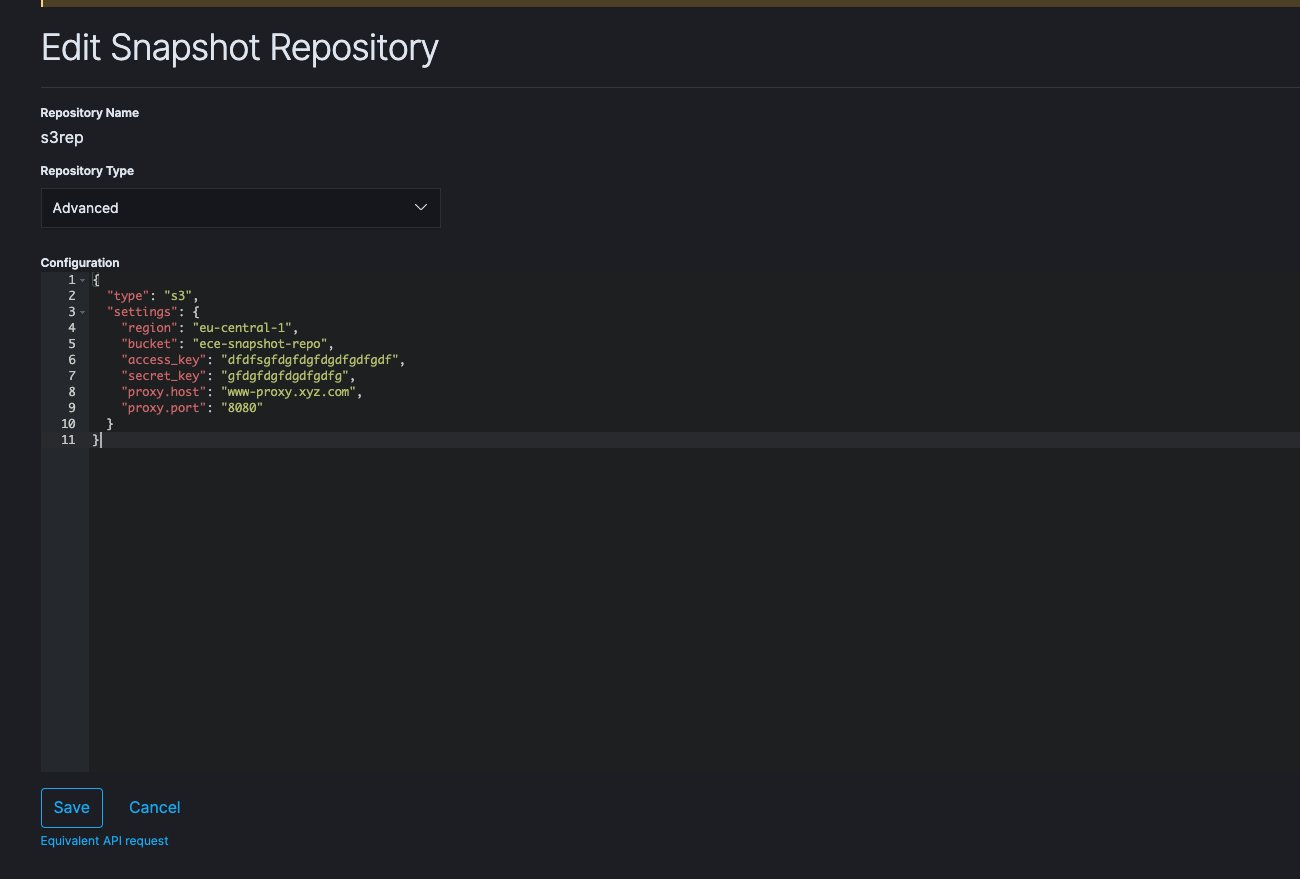
We just got it working by adding the proxy.host and proxy.port in the ECE repository. That seems like an undocumented feature. See screenshot attached.
We did not add the proxy information to YAML or docker container.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.
{kind=link}