I have a very small and simple test I'm trying to perform.
I use TransportClient in order to insert 1000 documents into my index.
This is done as you can see below:
for (Integer i = 0; i < 1000; i++) {
ManagedEvent event = createEvent(i);
IndexRequest indexRequest = new IndexRequest("events4", "event", i.toString());
indexRequest.source(JsonUtils.toJson(event, false));
IndexResponse response = transportClient.index(indexRequest).actionGet();
}
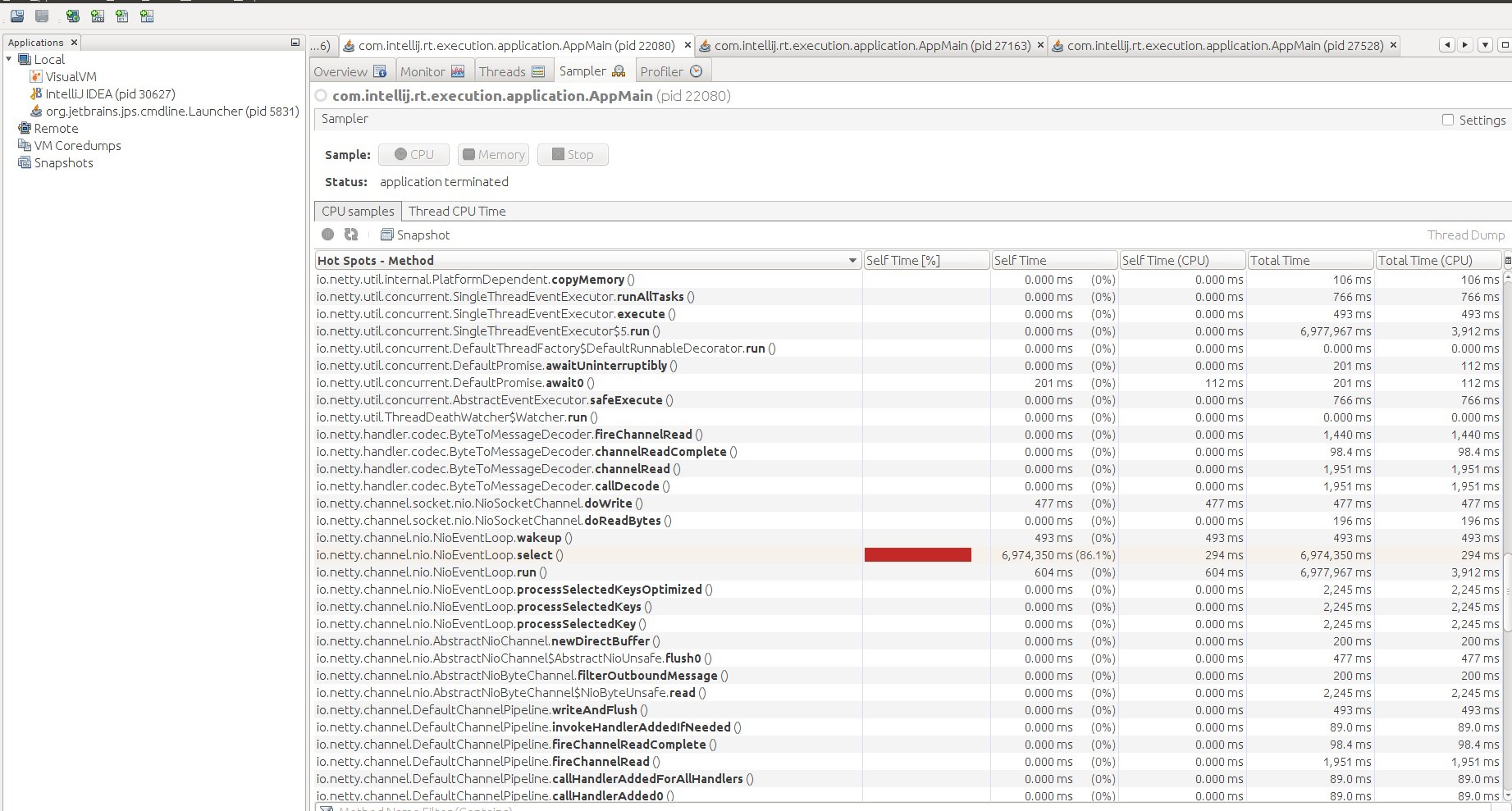
When I use JVisualVM in order to sample it, I see that NioEventLoop.select() is taking much of the CPU usage.
This causes performance to drop.
Am I doing something wrong?
In my test, there is only 1 thread using the transportClient and the client is created once at the start of it:
I think switching from nio to the native Linux epoll transport in Netty 4 http://netty.io/wiki/native-transports.html would fix the situation but the Elastic team decided not to include this code in the netty4 module.
So giving what you wrote, is the use of TransportClient recommended?
Using this client causes massive loss of performance...
It gets event worse when the loop is not 1000 but 10000 or more... How TransportClient can
operate in production environment with tens/hundreds of threads trying to read and write to ElasticSearch?
The TransportClient is based on Netty and there may be problems of all kind in Netty's NioEventLoop.select() - this depends on the situation. Such a select() problem is not affecting all systems and all configurations. Maybe it is only relevant if there are many hundred connections on the socket.
I do this as a test case that ilustrates, let's say, 1000 different events coming from different components/users at different times.
Theoritcally I can create a buffer that flushes every few seconds or so events via bulk, but this means that the user suffers a lag between the time of the insert and the time of the query (in addition to the refresh interval)
That's true, you will have an average 2 second delay between event submission and searchable event when using the default configuration, 1 second for bulk flush, the other 1 second for index refreshing.
But, from the eyes of performance, this is not slow because it scales. If you have 10, 100, 1k, 10k, 100k, or even 1m events per second, you can ramp up nodes to handle this throughput - and the delay will still be around 2 seconds.
You can try to tune for latencies under 1 second but you will notice your CPU and I/O load will increase, and performance and throughput will decrease.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.