Hi,
We upgraded our cluster from ES 2.3.3 to 5.2.
our new 5.2 cluster was built with much stronger servers (for future growth) than our 2.3.3 cluster which was rock solid.
Everything was running smoothly for few hours, monitoring shows that servers were calm and didn't work hard at all.
Then, suddenly Heap size jumps from 6.1GB to MAX (15GB) causing long GC's and then Nodes became unresponsive and then disconnected from cluster.
All other metrics looks stable, in terms of CPU (very low), indexing rate, get rate and search rate.
query cache, request cache and fielddata are stable as well.
Our usage is pretty basic, mainly textual search, some aggregations (sum, avg, and some contains scripts). very very low usage of nested documents and no usage of parent/child relationships.
It is not clear why the Heap jumps so fast to MAX - seems to be a MAJOR bug of elasticsearch or lucene.
then we found about this lucene 6.4.0 memory leak, so we tried deploing again but this time with ES 5.2.2 + lucene 6.4.1 but still same scenario happend.
Here is some technical information about the cluster:
- 3 master nodes
- 5 data nodes (32GB RAM, 8 cores)
- indices are not that big, most used ones contains 1.5 Mil docs, and take 4GB store size
indices used for aggs contains about 6Mil docs and weight about 15GB.
Attaching some graphs from crush time:
-
Heap (All nodes - The bottom lines are master nodes)
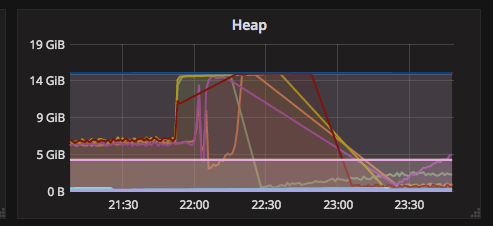
-
GC data (of first node that started the issue):
-
Index, Merge, Get & Search rates:


We've been working with elasticSearch for 5 years now and upgraded versions few times. this is the first time we encounter such major issue.
This is critical for us, so thank you in advance for helping!