Hi, When I used the new field type - wildcard field - for some queries, I found that different query inputs had a significant time difference, even though the input length was always one character:
Hi @913043599,
This is REALLY going to depend upon the underlying data which is not talked about here, but what I'm seeing makes sense.
The "n query" search is faster, but n is a pretty common letter. As soon as an "n" is found the query can move on to a new record. The "q query" however is looking for a letter that is not as common. It very well could be checking every letter in the field and not moving on to the next record until it doesn't find a "q".
For example:
"Hello everyone! We hope you are having a good day."
Would stop at the "n" in everyone with the "n query", where as "q query" would have to check the entire string to know there is or isn't a q present.
Final comment is the count query is letting you know the number of records found with the query. It is still looking at the entire index when running the query (all other things being equal). In other words "q query" and "n query" are looking the same number of records but "n query" is finishing quicker because it is doing fewer comparisons.
I could be wrong on this, but is how I make sense out of it.
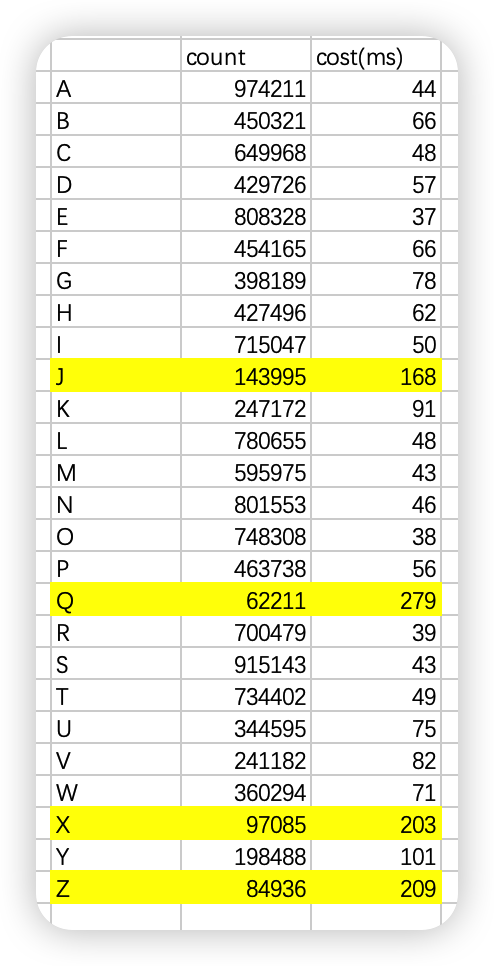
Hi @Wave , Thanks for your reply! Your conclusions and examples were very helpful to me. And I tried to verify the letters of the alphabet according to your claim and got the following table.
It seems that the more expensive queries correspond to lower counts. The data supports your claim, so I believe my problem is solved. And thank you again
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.