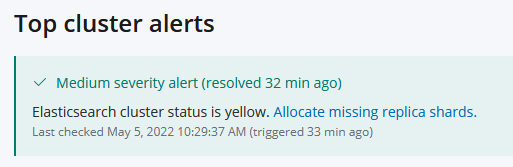
I then click on the Allocate missing replica shards which takes me to the Indices view (e.g. Monitoring/Indices). It says Unassigned Shards: 0, which makes sense since the alert says that it was resolved. Otherwise that view looks fine.
My question is what does this alert mean? I am assuming there are unassigned shards? Why is the cluster getting unassigned shards? How do I prevent it?
For information, ES is version 6.6.1. There is 40% (1.2 TB / 2.9 TB) of disk space available and JVM heap is at 34.37% (16.9 GB / 47.9 GB).
It's not 0000UTC . I mentioned that there is an alert every day. I meant, I see it everyday, but it happens many times throughout the day.
Yeah, we should upgrade, but "it works" and the cluster is huge and must remain online 24/7, so it'll be a good long while before that gets done.
Also, the idea that for the current ES version there is only 18 months at best before it goes EOL is completely ludicrous. No enterprise wants to be upgrading software nonstop. Consider Microsoft SQL Server 2016. It's EOL is not until 2026 - that's 10 years.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.