 What’s new in Elastic 8.19/9.1
What’s new in Elastic 8.19/9.1
Elastic 9.1 and 8.19 are here! We have extended the 8.x series one final time to 8.19, so those who are still waiting to upgrade to 9.x can already benefit from the new features in 9.1.
To help you plan upgrades, this is the release and maintenance plan for the Elastic Stack:
- Approximately quarterly releases, with 2 minor versions maintained in parallel, to give you more time for upgrades and provide an overlap in maintained versions.
- 8.19 will be maintained for quite a bit longer, but from 9.2 on, all new features will only make it to the 9.x series.
- If you are still on 7.x or earlier, now is a great time to plan moving to a maintained version.

Elastic 9.1 and 8.19 include new features and enhancements including GA of Cross Cluster Search and LOOKUP JOINs with ES|QL, LogsDB and TSDS performance and storage improvements, BBQ by default & ACORN. Check out the key highlights below.
GA of Cross Cluster Search in Enterprise and LOOKUP JOINs with ES|QL
ES|QL with LOOKUP JOINs are now GA, providing better performance and scaling. LOOKUP JOINs simplify data correlation, removing the need for data denormalization or complex client-side joins — and they are now GA. Unlike the ingest-time enrich processor, which requires managing policies and waiting for them to execute, a lookup index can be updated directly.
Example of how to enrich security logs with employee directory information:
FROM security_events
| WHERE event.action == "login_failure"
| KEEP event.id, event.action, emp_id
| LOOKUP JOIN employee_directory ON emp_id
| STATS failed_logins = COUNT(event.id) BY emp_department
| SORT failed_logins DESC
| KEEP emp_full_name, emp_department, failed_logins
With a combination of pushdowns to Lucene, smarter query planning and execution, and optimized memory and CPU usage, ES|QL is more performant than ever. New features include COMPLETION to access LLM completions within a query, MATCH_PHRASE, and FORK to run multiple queries.
Cross-Cluster Search (CCS) with ES|QL is now generally available as an Enterprise feature, allowing you to search across distributed clusters using the _search API.
The query is routed to one of the cluster nodes, further referred to as the coordinator node. The coordinator node is responsible for parsing, validating and executing the query, aggregating the results, and sending them to the user. It generates a query plan that describes the exact manner of query execution before determining the nodes it needs to coordinate with and sending out the query plan to other local nodes and to the remote clusters.

With the nature of distributed search across clusters, robust and predictable failure handling mechanisms are required. With CCS the skip_unavailable option (set to true by default) ensures that if a remote cluster is unreachable or has no matching indices, it is gracefully skipped. The default setting for allow_partial_results being true also supports shard failures mid-query (e.g., during a rolling restart). It ensures that the query succeeds with results from all available shards, and will also automatically retry the failed shard first.
LogsDB and TSDS Performance and Storage Improvements
LogsDB and TSDS indexing mode automatically trigger a suite of optimizations geared toward storage efficiency. Two of the most important ones are synthetic _source and index sorting. Compared to standard indexing mode in 8.17, LogsDB is now up to 4x more storage efficient, with an indexing throughput penalty that is at max 10%. The latest improvements include a ~50% reduction in disk I/O driven by removing the temporary writing of the recovery source, lower CPU overhead, and smarter array handling for greater storage efficiency.

You can read more about these enhancements here.
BBQ and ACORN
Better Binary Quantization (BBQ), which is 5x faster than OpenSearch, is now enabled by default for dense vectors of 384 dimensions or higher. BBQ reduces the memory footprint by over 95%. It’s a two-stage search process, starting with a broad scan and then reranking the oversampled initial scan.
We ran several benchmarks across 10 public datasets from the BEIR data sets, comparing traditional BM25 search, vector search with the e5-small model (float32 vectors), and vector search with the same model using BBQ. Thanks to the oversampling, BBQ performed better in 9 out of 10 datasets than the pure float32 search.
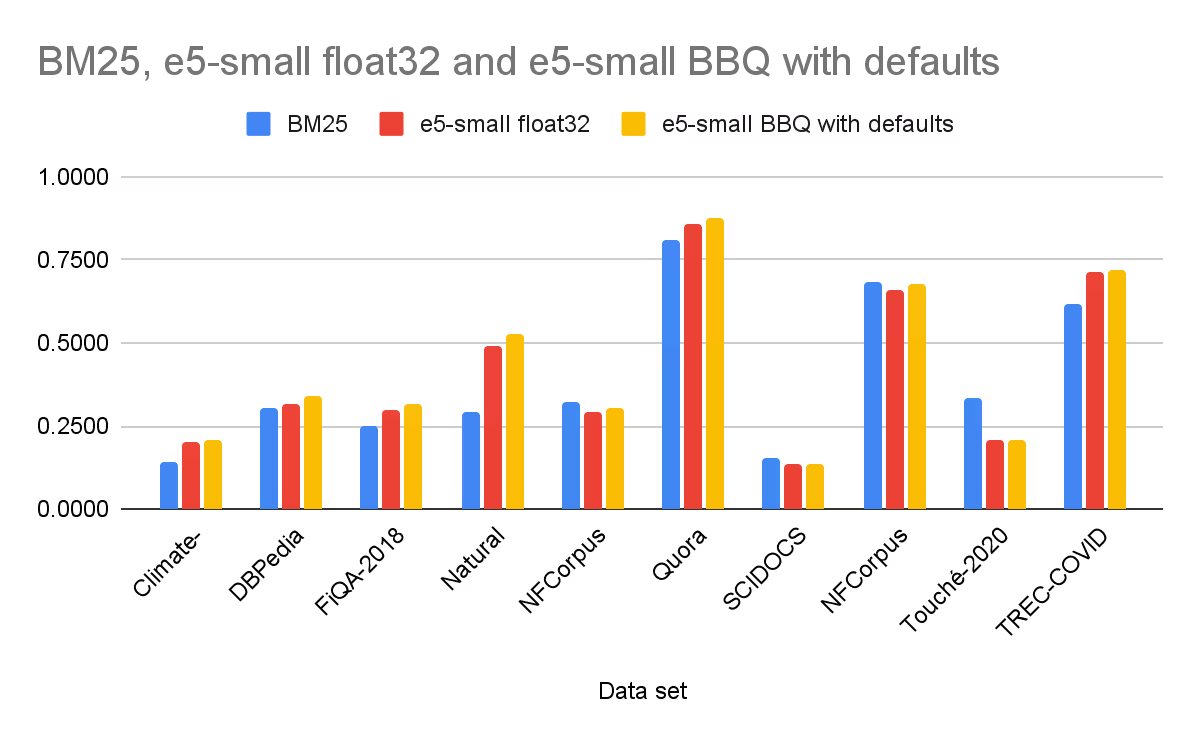
ACORN is a new algorithm for filtered vector search that integrates filtering directly into the HNSW graph traversal and provides the flexibility to define filtering fields after documents are indexed — delivering up to 5x faster filtered search and no compromise on accuracy, all out of the box.
Token pruning for sparse vectors is now generally available and enabled by default — bringing faster, more efficient semantic search for ELSER queries.
You can dive into the details of BBQ, ACORN and token pruning in this article.
Start today
If you want to try these out, check out start-local to run a trial on your own machine:
curl -fsSL https://elastic.co/start-local | sh
Or start on the cloud with a free trial. Just click here.