Hello,
It's been several times working with rally and every time I feel like it's hard to understand and use. I started an http_logs track against a cluster, and can't find the meaning of the following operations that rally did and couldn't find it in the official documentation:
Running delete-index [100% done]
Running create-index [100% done]
Running check-cluster-health [100% done]
Running index-append [100% done]
Running refresh-after-index [100% done]
Running force-merge [100% done]
Running refresh-after-force-merge [100% done]
Running wait-until-merges-finish [100% done]
Running default [100% done]
Running term [100% done]
Running terms_enum [100% done]
Running range [100% done]
Running 200s-in-range [100% done]
Running 400s-in-range [100% done]
Running hourly_agg [100% done]
Running scroll [100% done]
Running desc_sort_timestamp [100% done]
Running asc_sort_timestamp [100% done]
Running desc_sort_with_after_timestamp [100% done]
Running asc_sort_with_after_timestamp [100% done]
Running desc_sort_timestamp_can_match_shortcut [100% done]
Running desc_sort_timestamp_no_can_match_shortcut [100% done]
Running sort_keyword_can_match_shortcut [100% done]
Running sort_keyword_no_can_match_shortcut [100% done]
Running sort_numeric_can_match_shortcut [100% done]
Running sort_numeric_no_can_match_shortcut [100% done]
Running force-merge-1-seg [100% done]
Running refresh-after-force-merge-1-seg [100% done]
Running wait-until-merges-1-seg-finish [100% done]
Running desc-sort-timestamp-after-force-merge-1-seg [100% done]
Running asc-sort-timestamp-after-force-merge-1-seg [100% done]
Running desc-sort-with-after-timestamp-after-force-merge-1-seg [100% done]
Running asc-sort-with-after-timestamp-after-force-merge-1-seg [100% done][INFO] Racing on track [http_logs], challenge [append-no-conflicts] and car ['external'] with version [8.5.3].
Also I have several questions regarding rally:
- What's the meaning of
index-appendis it indexing operation? same for200s-in-range, etc. if there is a documentation describing each meaning it would be appreciated! - the default challenge for
http_logsisappend-no-conflicts, what's the meaning ofappend-no-conflicts? also, I tried to run many challenges using a Kubernetes manifest with rally as follow but failed:
# ...
args:
[
"race",
"--track=http_logs",
"--pipeline=benchmark-only",
"--challenge=append-no-conflicts,append-no-conflicts-index-only,append-fast-with-conflicts,significant-text",
"--track-params=bulk_size:5000,bulk_indexing_clients:10",
"--target-hosts=my_host",
"--client-options='use_ssl:false,verify_certs:false,basic_auth_user:elastic,basic_auth_password:xxxxx"
]
#....
- when rally finishes a track, it stores data into 3 index:
a.rally-races*
b.rally-results*
c.rally-metrics*
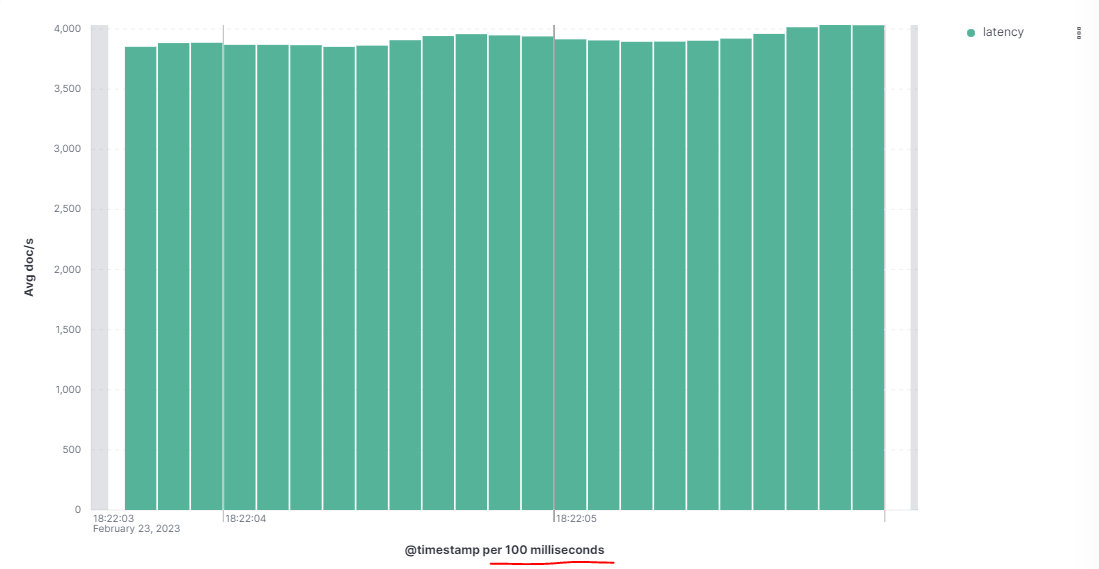
When I make some visualization using the index rally-metrics I get discrete points on kibana (in this viz I have only 3 points of data, but the whole test took around 3 hours, I expected to have many data points to look continuous on a viz):

Also what about the index rally-results*, it contains the same summary table we get when rally is finished right?
Also if there is any recommendation for "how to analyze" the results of the benchmark it would be helpful.
Thank you,
Marwane.